
Кадр из Top Gear: USA (серия 2)
В своих самых высоконагруженных сервисах мы в Badoo используем язык C и иногда C++. Зачастую эти сервисы хранят в памяти сотни гигабайт данных и обрабатывают сотни тысяч запросов в секунду. И нам важно использовать не только подходящие алгоритмы и структуры данных, но и производительные их реализации.
Практически с самого начала в качестве реализации ассоциативных массивов мы использовали Judy. У неё есть C-интерфейс и множество преимуществ. Мы даже используем обёртку для PHP, так как в версиях PHP до 7.0 Judy сильно выигрывает по количеству потребляемой памяти по сравнению со встроенными мапами.
Однако время идёт, и с момента последнего релиза Judy прошло немало лет – самое время посмотреть на альтернативы.
Меня зовут Марко, я – системный программист Badoo в команде «Платформа». Мы с коллегами провели небольшое исследование в поисках альтернатив Judy, сделали выводы и решили поделиться ими с вами.
Ассоциативный массив
Если вы знаете, что такое ассоциативный массив, дерево и хеш-таблица, этот раздел можете смело пропускать. Для остальных – небольшое введение в тему.
Ассоциативный массив – это абстрактный тип данных, который позволяет по ключу получать или сохранять значение. Абстрактный он, потому что ничего не говорит о том, как этот тип данных должен быть реализован. И правда, если немного пофантазировать, можно придумать десятки разных реализаций разного уровня адекватности.
Для примера можем взять банальный связный список. На put мы обойдём его весь от начала до конца, чтобы убедиться, что у нас ещё нет такого элемента, а если нет, то добавим его в конец списка; на get – просто обойдём список от начала до конца в поисках нужного элемента. Алгоритмическая сложность поиска и добавления элемента в такой ассоциативный массив – O(n), что не очень хорошо.
Из простых, но чуть более адекватных реализаций можно рассмотреть простой массив, элементы которого мы всегда будем держать отсортированными по ключу. Поиск в таком массиве можно осуществлять бинарным поиском, получив O(log(n)), но вот добавление в него элементов может потребовать копирования больших кусков памяти из-за необходимости освободить место под элемент в строго определённой позиции.
Если же посмотреть на то, как реализуются ассоциативные массивы на практике, то вероятнее всего мы увидим какое-либо дерево или хеш-таблицу.
Хеш-таблица
Хеш-таблица – это структура данных, реализующая ассоциативный массив, устройство которой представляет собой двухэтапный процесс.
На первом этапе наш ключ прогоняется через хеш-функцию. Это функция, которая на вход принимает набор байт (наш ключ), а на выходе обычно даёт какое-то число. Это число на втором этапе мы используем для поиска значения.
Как? Вариантов множество. Первое, что приходит в голову, — использовать это число в качестве индекса в обычном массиве. Массиве, в котором лежат наши значения. Но этот вариант не будет работать как минимум по двум причинам:
Область значений хеш-функции, скорее всего, больше, чем размер массива, который бы нам хотелось хранить выделенным в памяти.
- Хеш-функции имеют коллизии: два разных ключа могут дать одно и то же число в ответе.
Обе эти проблемы обычно решаются выделением массива ограниченного размера, каждый элемент которого является указателем на другой массив (bucket). Область значений нашей хеш-функции мы затем отображаем на размер первого массива.
Как? Вариантов, опять же, много. Например, взять остаток от деления на размер массива или просто взять нужное количество младших бит числа, если размер массива у нас является степенью двойки (остаток от деления – значительно более медленная операция для процессора по сравнению со сдвигом, так что обычно предпочтение отдаётся именно массивам с размером, являющимся степенью двойки).
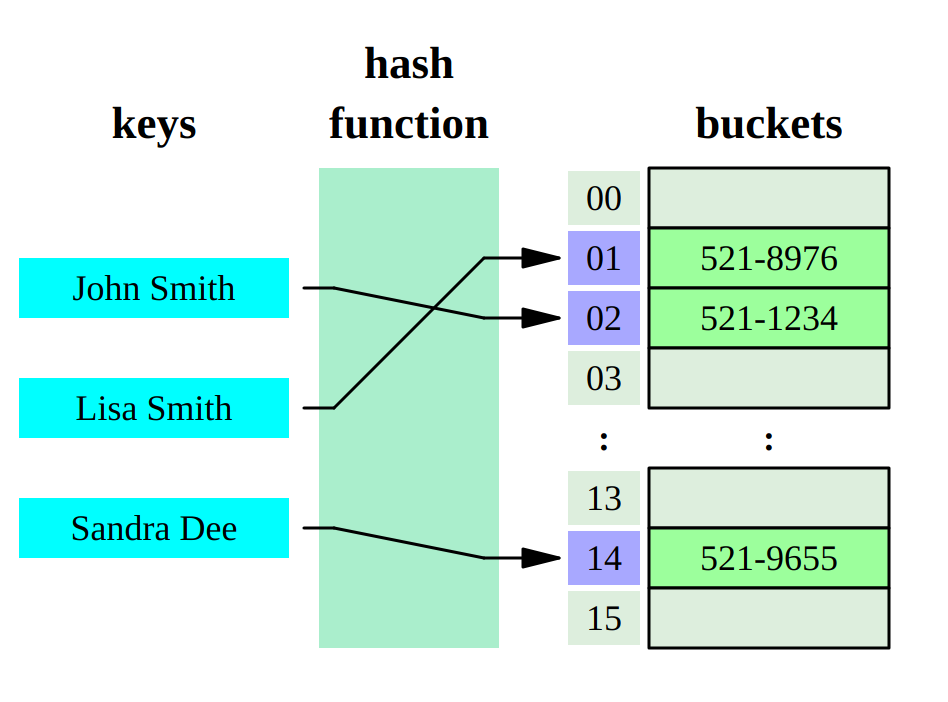
Я привёл в пример один из распространённых способов реализации хеш-таблицы, но вообще их великое множество. И в зависимости от выбранного способа борьбы с коллизиями мы получим разную производительность. Если же говорить об алгоритмической сложности для хеш-таблиц, то в среднем у нас будет O(1), а в вырожденных случаях (worst case) может получиться и O(n).
Деревья
С деревьями всё довольно просто. Для реализации ассоциативных массивов используются различные бинарные деревья – такие, как, например, красно-чёрное дерево. В случае если дерево сбалансировано, мы получим O(log n) на операцию.
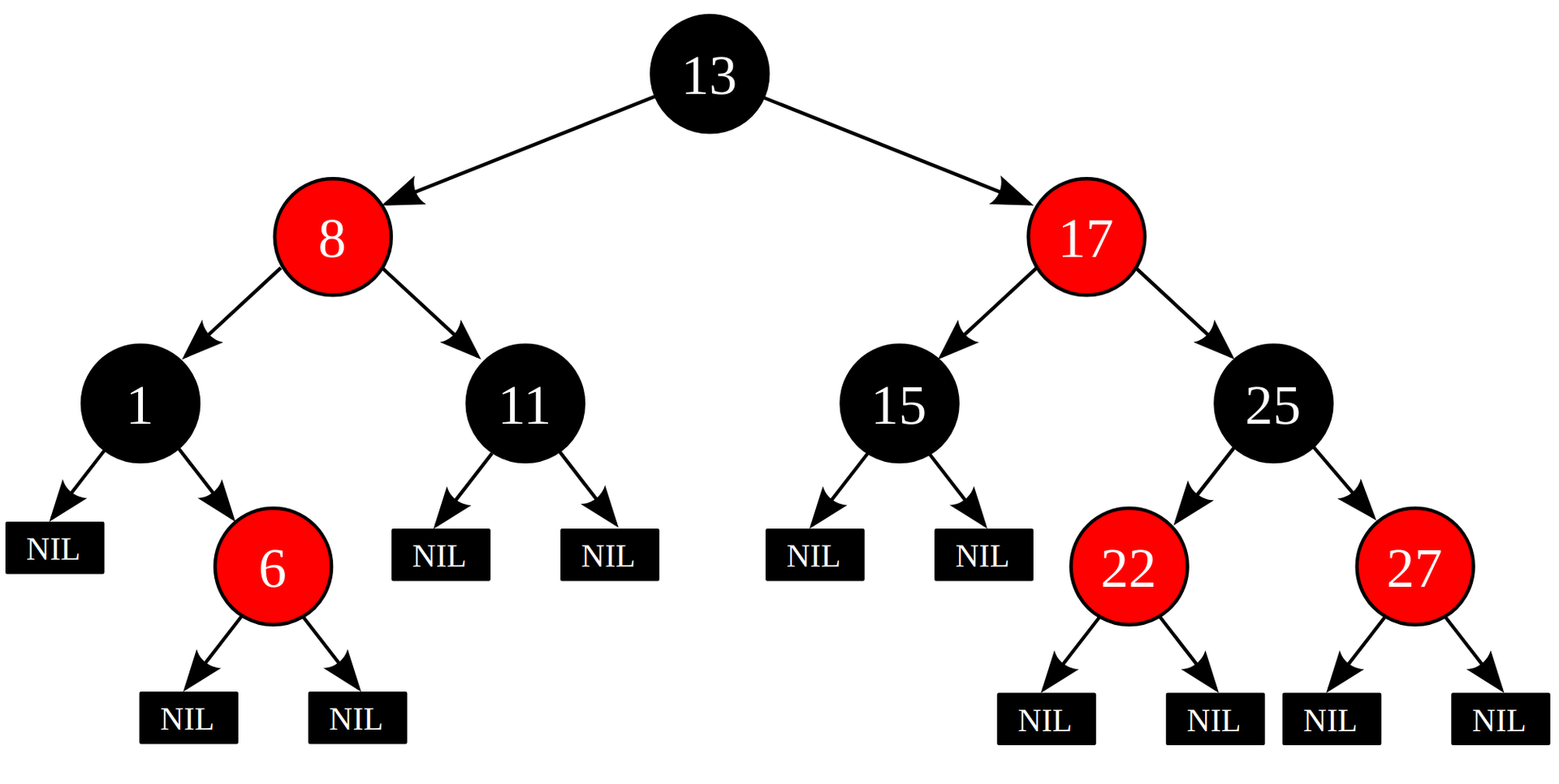
Некоторые реализации деревьев, такие как google btree, учитывают современную иерархию памяти и хранят ключи пачками для более эффективного использования процессорных кешей.
Деревья позволяют реализовать обход элементов по возрастанию или убыванию ключей, что зачастую является очень важным условием при выборе реализации. Хеш-таблицы этого не умеют.
На что смотрим?
Мир ассоциативных массивов, конечно, не чёрно-белый: у каждой реализации есть как преимущества, так и недостатки.
Разные реализации могут отличаться не только производительностью, но и набором предоставляемых функций. К примеру, какие-то реализации позволяют обходить элементы в порядке возрастания или убывания ключа, а какие-то – нет. И это ограничение связано с внутренней архитектурой, а не прихотями автора.
Да и банальная производительность может сильно отличаться в зависимости от того, каким образом вы используете ассоциативный массив: в основном пишете в него или читаете, читаете ключи в произвольном порядке или последовательно.
Прошли времена, когда О-нотации Кнута было достаточно для сравнения двух алгоритмов. Реальный мир гораздо сложнее. Современное железо, на котором работают наши программы, имеет многоуровневую память, доступ к разным уровням которой сильно отличается, и учёт этого может ускорить алгоритм в разы или на столько же его замедлить.
Немаловажным критерием является и вопрос потребления памяти: какой оверхед у выбранной реализации по сравнению с теоретическим минимумом (размер ключа + размер значения, умноженные на количество элементов) и допустим ли такой оверхед в нашей программе?
Паузы, максимальная задержка (latency) и отзывчивость тоже играют важную роль. Некоторые реализации ассоциативных массивов требуют одномоментного дорогостоящего перестроения своих внутренних структур при добавлении элемента, которому не повезло, а другие – «размазывают» эти задержки во времени.
Участники исследования
Judy
Judy (или Judy Array) – структура, придуманная Дугласом Баскинсом, реализующая упорядоченный ассоциативный массив. Реализация написана на C и крайне сложна. Автор попытался учесть современную архитектуру и использовать кеши процессора по максимуму.
Judy представляет из себя дерево, а не хеш-таблицу. И не просто дерево, а так называемое префиксное дерево. Для нас, потребителей, это означает, что, используя Judy, мы получаем сжатие ключей и возможность бежать по элементам в порядке возрастания или убывания ключа.
Judy предоставляет несколько вариаций «ключ/значение»:
| Вариация | Ключ | Значение |
|---|---|---|
| Judy1 | uint64_t | bit |
| JudyL | uint64_t | uint64_t |
| JudySL | null-terminated string | uint64_t |
| JudyHS | array of bytes | uint64_t |
Judy1 удобно использовать для больших разреженных bitmap‘ов. JudyL является базовым типом, который мы в C-сервисах Badoo чаще всего и используем. JudySL, как видно, удобно использовать для строк, а JudyHL – просто для какого-то набора байт.
std::unordered_map
unordered_map реализован на C++ в виде шаблона, так что в качестве ключа и значения может выступать всё что угодно. В случае использования нестандартных типов вам придётся определить функцию для хеширования этих типов.
Это именно хеш-таблица, так что обход ключей по возрастанию или убыванию недоступен.
google::sparse_hash_map
Как видно из названия, sparse hash был разработан в Google и заявляет минимальный оверхед в размере всего два бита на значение. Он также реализован на C++ и сделан в виде шаблона (и это, на мой взгляд, несомненное преимущество реализаций на C++).
Кроме всего прочего, sparse hash умеет сохранять своё состояние на диск и загружаться с него.
google::dense_hash_map
Кроме sparse hash, Google сделала вариант под названием dense hash. Скорость у него (а особенно скорость get‘а) заметно выше, но за это приходится платить большим расходом памяти. Также, из-за того, что внутри у dense_hash_map плоские массивы, периодически требуется дорогое перестроение. Кстати, о таких проблемах и нюансах хеш-таблиц отлично рассказал Константин Осипов в своём докладе на HighLoad++. Рекомендую к изучению.
В случае если количество данных, которые вы храните в ассоциативном массиве невелико и его размер не будет сильно меняться, dense hash должен подойти вам лучше всего.
Аналогично sparse hash dense hash является хеш-таблицей и шаблоном. То есть, повторюсь, никакого прохождения по ключам в порядке возрастания, но при этом возможность использовать любые типы в качестве ключей и значений.
Также аналогично своему собрату sparse_hash_map dense_hash_map умеет сохранять своё состояние на диск.
spp::sparse_hash_map
И, наконец, последний претендент от одного из разработчиков google sparse hash. Автор взял за основу sparse hash и переосмыслил его, добившись минимального оверхеда в один бит на запись.
Всё то же самое: хеш-таблица и шаблон. Реализация на C++.
Претенденты представлены – пришло время проверить, на что они способны.
Ещё два фактора
Но сначала замечу, что на производительность и потребление памяти будут влиять ещё две вещи.
Хеш-функция
Все участники нашего исследования, являющиеся хеш-таблицами, используют хеш-функции.
У хеш-функций довольно много свойств, каждое из которых может быть более или менее важно в зависимости от области. Например, в криптографии важно, чтобы минимальное изменение входящих данных приводило к как можно большему изменению в результате.
Но нас больше всего интересует скорость. Производительность хеш-функций может сильно отличаться, и скорость часто зависит от того количества данных, которое им «скармливается». Когда на вход в хеш-функцию подаётся длинная цепочка байт, может быть целесообразно применение SIMD-инструкций для более эффективного использования возможностей современных процессоров.
В дополнение к стандартной хеш-функции из C++ я посмотрю, как справятся xxhash и t1ha.
Аллокация памяти
Второй фактор, который обязательно повлияет на наши результаты, — аллокатор памяти. От него напрямую зависят и скорость работы, и количество потребляемой памяти. Стандартный аллокатор из libc – это jack of all trades. Он хорош для всего, но ни для чего не идеален.
В качестве альтернативы я рассмотрю jemalloc. Несмотря на то, что в тесте мы не воспользуемся одним из его основных преимуществ – работой с многопоточностью – я ожидаю более быструю работу с этим аллокатором.
Результаты
Ниже представлены результаты теста по рандомному поиску среди десяти миллионов элементов. Два параметра, которые меня больше всего интересуют, – время выполнения теста и максимальная потреблённая память (RSS процесса в пике).
В качестве ключа я использовал 32-битное целое, а в качестве значения – указатель (64 бита). Именно такие размеры ключей и значений мы чаще всего используем.
Я не стал показывать результаты других тестов, которые представлены в репозитории, так как меня больше всего интересовали именно рандомный get и потребляемая память.
Самым быстрым ассоциативным массивом оказался dense hash от Google. Следом идёт spp, и затем – std::unordered_map.
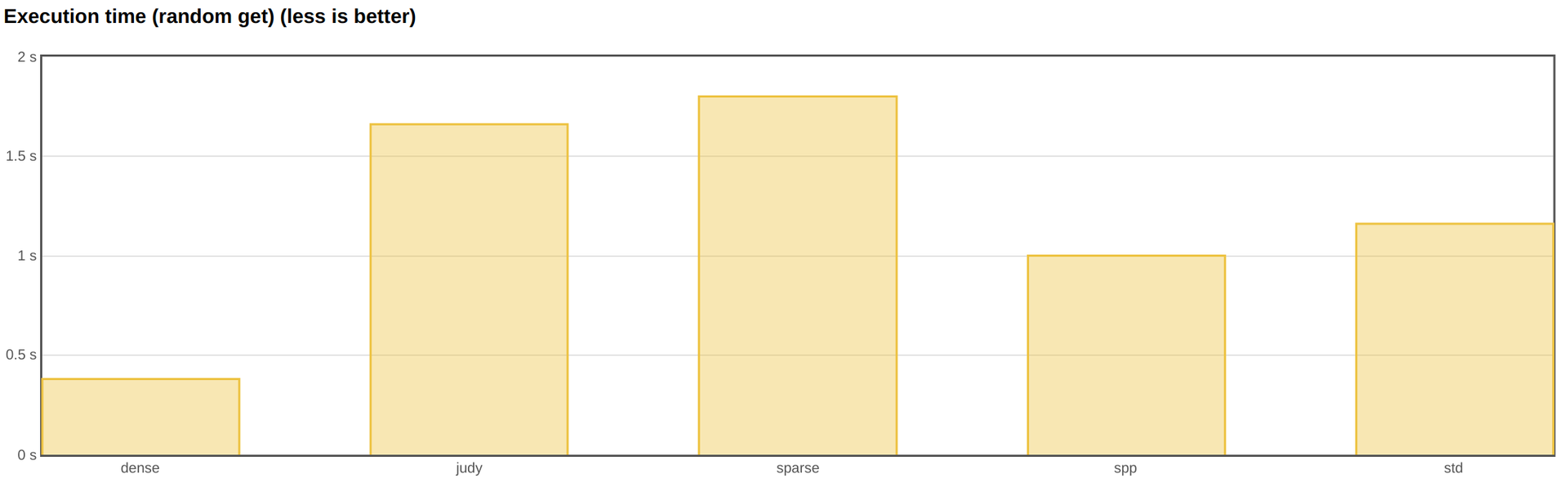
Однако если посмотреть на память, видно, что dense_hash_map потребляет её больше всех других реализаций. Собственно, именно это сказано в документации. Более того, если бы у нас в тесте были конкурирующие чтение и запись, мы бы, скорее всего, столкнулись со stop-the-world-перестроением. Таким образом, в приложениях, где важна отзывчивость и много записей, dense hash использовать нельзя.
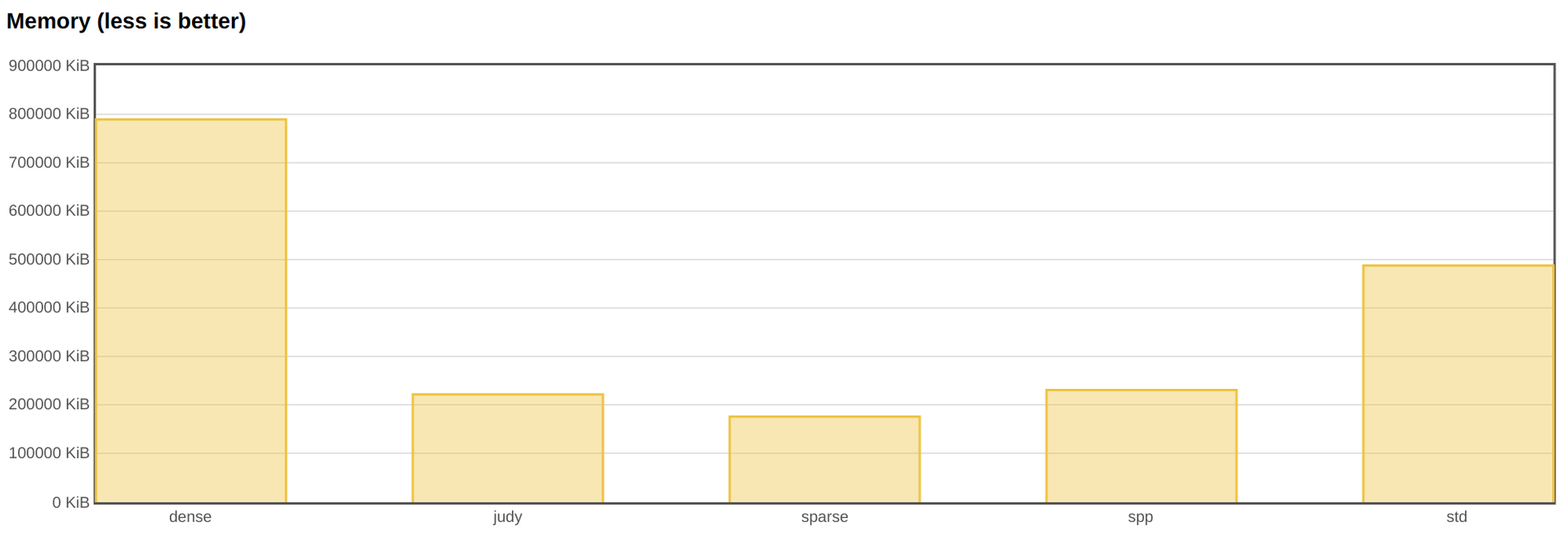
Также я посмотрел на альтернативные реализации хеш-функций. Но, как оказалось, стандартная std::hash быстрее.
Коллега случайно заметил, что в случае 32- или 64-битных ключей std::hash по сути просто identity. То есть на входе и выходе – одно и то же число, или, другими словами, функция ничего не делает. хxhash и t1ha же честно считают хеш.

В плане производительности jemalloc полезен. Практически все реализации становятся быстрее.
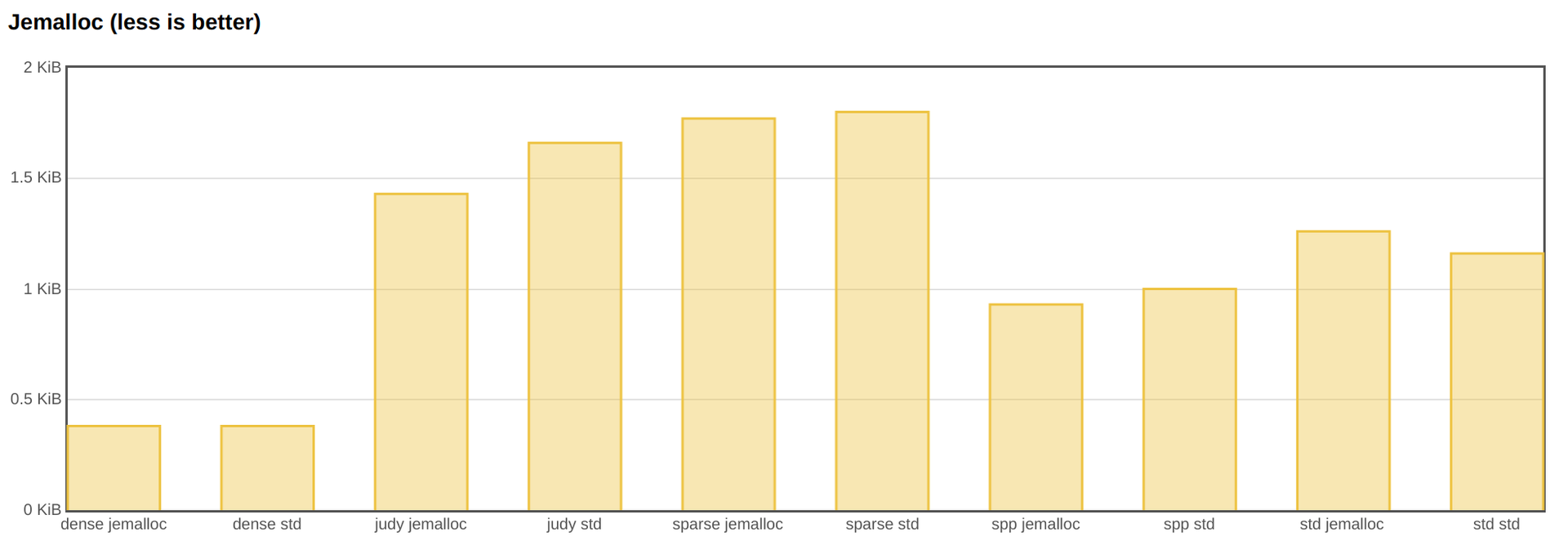
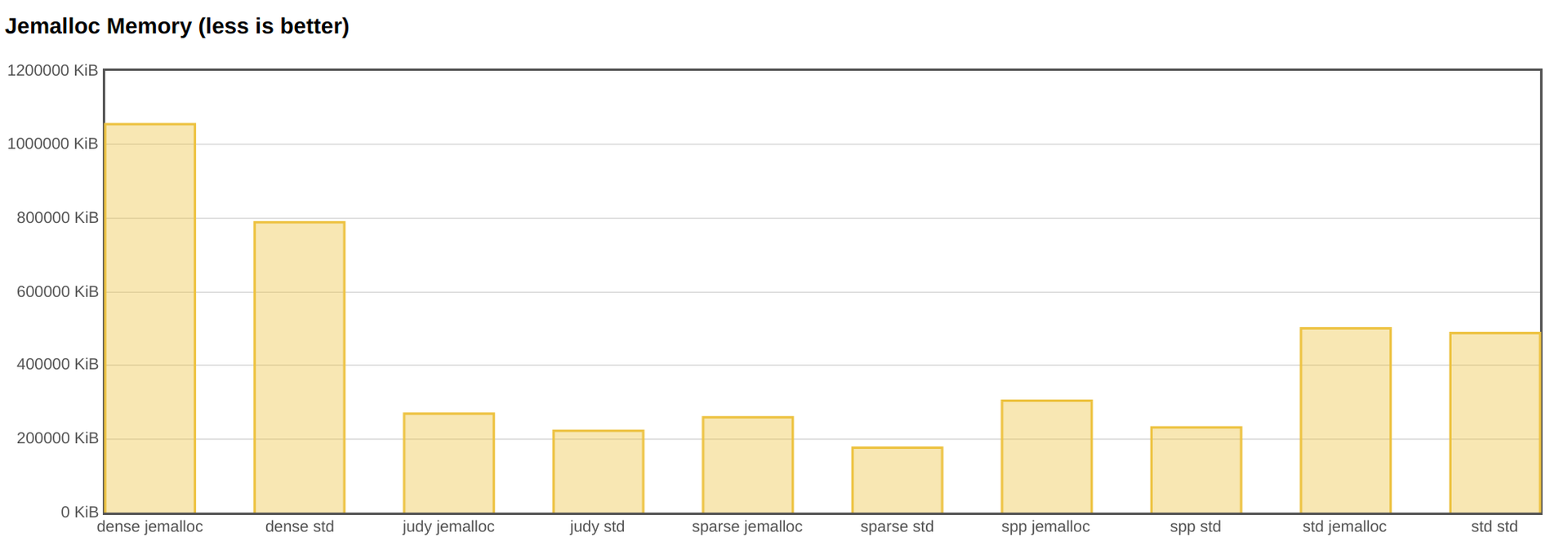
Однако по потреблению памяти jemalloc не настолько хорош.
Исходный код и железо
Исходный код бенчмарков я выложил на github. При желании вы можете повторить мои тесты или расширить их.
Я же проводил тестирование на своём домашнем десктопе:
- Ubuntu 17.04
- Linux 4.10.0
- Intel® Core(TM) i7-6700K CPU @ 4.00GHz
- 32 GiB DDR4 memory
- GCC 6.3.0
- Флаги компилятора: -std=c++11 -O3 -ffast-math
Краткие выводы и заключительные слова
Наши тесты показали хороший потенциал spp в качестве замены Judy. spp оказался быстрее на рандомных get‘ах, а его оверхед по памяти не слишком велик.
Мы сделали простенькую обёртку над C++ для C и в ближайшее время попробуем spp в одном из своих высоконагруженных сервисов.
Ну, и в качестве совсем философского заключения скажу, что у каждой из рассмотренных нами реализаций есть свои плюсы и минусы и выбирать следует, основываясь на решаемой задаче. Понимание их внутреннего устройства поможет вам сопоставить задачу и решение, и это понимание зачастую отличает простого инженера от продвинутого.
