Comments 45
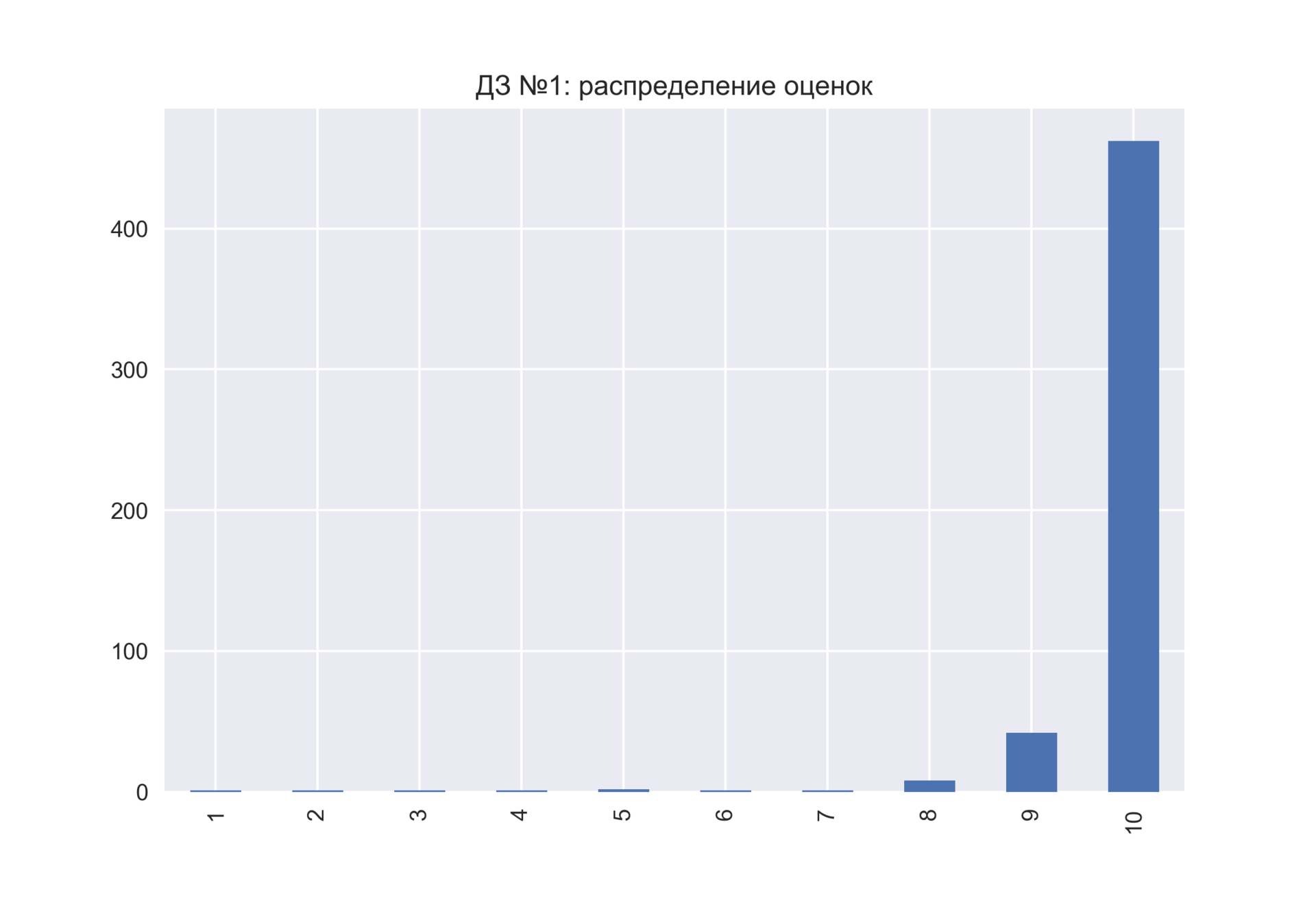
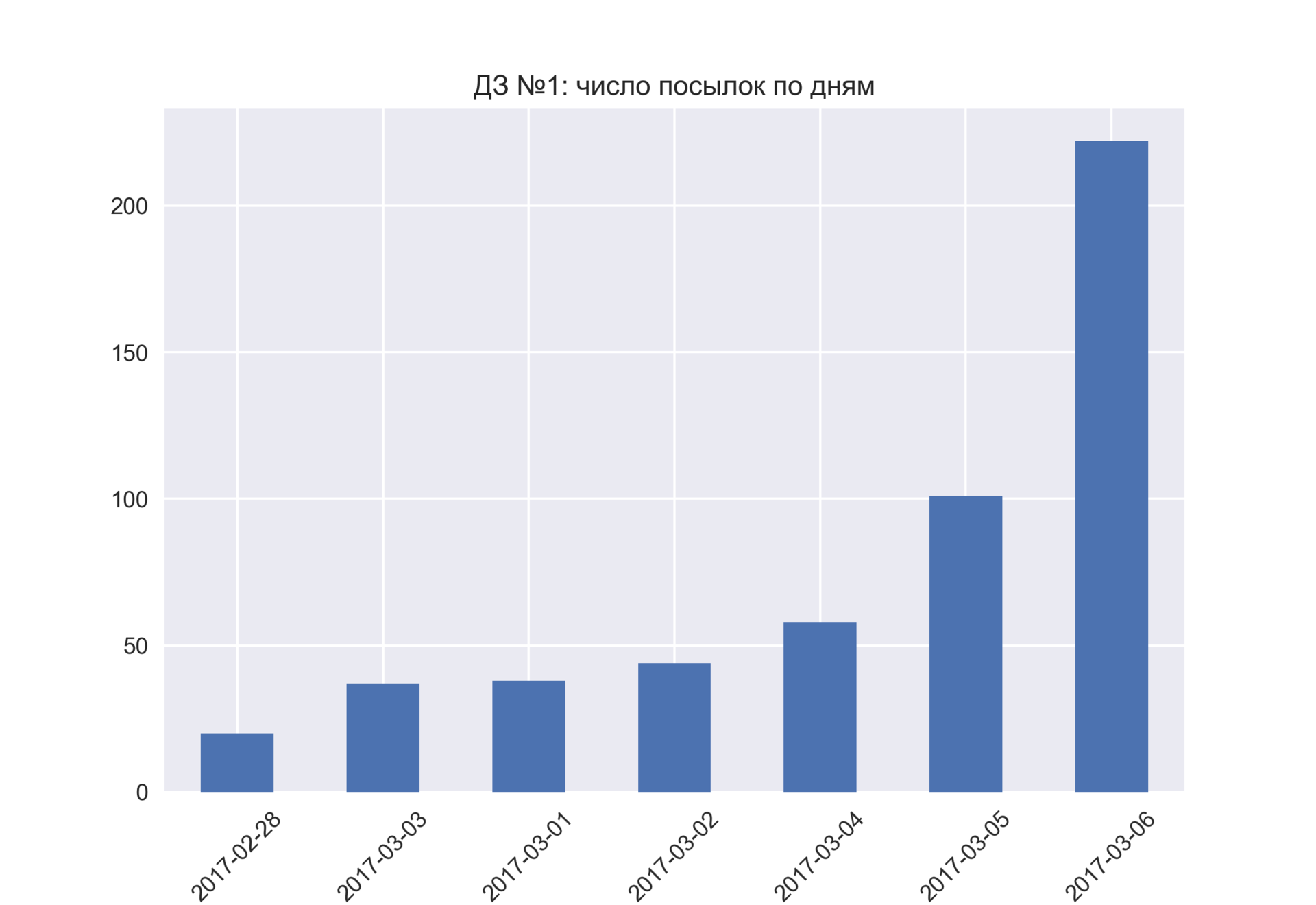
Небольшой фидбек по 1 ДЗ, краткая стата по оценкам и решение на GitHub будут сразу после дедлайна.
Также как и список фильмов из первого опроса :)
Спасибо за публикацию) seaborn очень зацепил в свое время. Все же приятно, когда иллюстрации в научные журналы не только информативные, но и выглядят хорошо.
Рейтинг участников. Будет считаться по домашним заданиям, соревнованиям и, возможно, дополнительным бонусам, оговариваемым заранее и публично.
Да, конечно! Правда, и оценки пойдут со второй домашки.
Дальше планируется ряд ништяков, главный из которых – серия лекций (вживую) про state-of-the-art машинного обучения. Темы сложные, требуют некоторого базового уровня. Если приглашать лучших по рейтингу, то почти наверное это обеспечит минимальный уровень слушателей, а также будет служить дополнительной мотивацией участников. Если не хотите участвовать в гонке – без проблем, можно проходить в своем темпе, польза всяко будет.
есть идеи где можно еще взять этот dataset?
Все данные для примеров есть еще в репозитории mlcourse_open.
А можно ли изолинии сохранять в dxf формате, с помощью данных библиотек.
Или хотя бы получать координаты изолиний, чтобы потом сохранить в dxf.
Подскажите, пожалуйста, а нужно ли куда-то отправлять тетрадки с кодами по 2ДЗ?
Добрый вечер! Я не Юрий, но отвечу :)
Тетрадки с решениями никуда отправлять не нужно, достаточно ответить на вопросы в google-форме.
X['International plan'] = pd.factorize(X['International plan'])[0]
X['Voice mail plan'] = pd.factorize(X['Voice mail plan'])[0]
необходимо добавить
sort = TrueТ.е. должно быть:
X['International plan'] = pd.factorize(X['International plan'], sort = True)[0]
X['Voice mail plan'] = pd.factorize(X['Voice mail plan'], sort = True)[0]
Иначе Yes и No в разных колонках будут факторизованы как (1,0) и (0,1) соответственно, что приведет к невозможности в дальнейшем использовать их для обработки.
А что может быть особенного в них? Откуда берутся выводы?
Рекомендую посмотреть на примеры на странице с документацией по функции pairplot в библиотеке seaborn.
По гистограммам можно понять распределение признаков (нормальное оно или нет, сбалансированы ли классы и т.д.)
По scatter plots будет видна, например, линейная зависимость между признаками.
Если же отображать также классы разными цветами, то можно выявить в каком пространстве (паре признаков) классы будут хорошо отделяться друг от друга. Рассмотрим, pairplot для сортов ирисов: видно, классы сливаются в пространстве признаков (sepal_length, sepal_width), а в пространстве (petal_length, petal_width) достаточно легко провести разделяющие гиперплоскости.

User_Score 10015 non-null object
Нужно вспомнить первую лекцию и изменить тип колонки, что в целом, даже полезно.
3. Когда лучше всего публиковать статью?
…
На хабре дневные статьи комментируют чаще, чем вечерние
А что есть дневная, а что вечерняя статья? С какого по какое время?
Да, стоило это четче в задании указывать. Но на самом деле нет необходимости: по графикам сразу понятно будет, без двояких трактовок.
у меня тоже вопрос по 2-ой домашке, второй вопрос
2. Проанализируйте публикации в этом месяце ( из вопроса 1 )
имеется ввиду df.month = M или df.month = M & df.year = Y
где M, Y ответы из первого вопроса
Да, все последующие вопросы относятся ко всем данным.
Прошу разрешить вопрос Шреденгера. Во втором задании второй вопрос. По ощущениям утверждения «На графике не заметны какие-либо выбросы или аномалии» и «Один или несколько дней сильно выделяются из общей картины» затрагивают один и тот же момент — есть ли особые дни. Кажется что различие в вопросах определяются точкой взгляда, т.е. субъективно. Т.е. если день вполне укладывается границы, но при этом не стандартный относительно циклов, то считать ли это аномалией или выбивается ли он в этом случае из общей картины?
Выложил результаты 1 опроса (который был перед стартом курса) – в репозитории data/mlcourse_open_first_survey_data.csv (учел согласие на обработку, убрал е-мейлы)
Объявляется мини-конкурс по визуализации данных. Берете данные опроса, крутите их, вертите, ищите крутые закономерности, рисуете картинку. Кидаете в слэке в #mlcourse_open (обязательно с тегом #vis_contest), чья картинка набирает больше всего плюсов – тому респект и
1 место (по плюсам) – 5 баллов в рейтинг
2 место – 3 балла
3 место – 2 балла
Подсчет баллов будет 28 марта в 00:00, т.е. вместе с результатами 4 домашки.
Есть два вопрос:
На keras blog описан интересный метод: Variational autoencoder (VAE). Я так понял, что это гибкий алгоритм кластеризации. Используется сustom loss (vae_loss). Метод интересный, но достаточно трудный для понимания. Где, по-вашему мнению, данный метод может найти применение?
UPD: Видеозапись лекции по мотивам этой статьи в рамках нового запуска открытого курса (сентябрь-ноябрь 2017).
df = pd.read_csv('data/video_games_sales.csv')
а должна быть
df = pd.read_csv('data/video_games_sales.csv').dropna()
Новый запуск – 1 октября 2018 г., на английском. Подробности – тут.
Теперь курс можно проходить и самостоятельно – появились демо-версии заданий с решениями. Они описываются в конце каждой статьи, но есть и общий cписок. Решения доступны после отправки соотв. веб-формы.
Открытый курс машинного обучения. Тема 2: Визуализация данных c Python