Comments 14
А можно несколько примеров баек про электриков?
Сейчас мы «отпускаем» прямое проектирование архитектуры прикладного функционала, так как удержать его на целевых масштабах невозможно.
Мы собираемся ничего не знать про каждый модуль и переходим только к контролю:
качества проектируемых новых модулей, сравнивая их количественные характеристики с типовыми значениями статистически удачных решений;
характера вносимых изменений в коде через reverse engineering;
и обеспечиваем контент для автоматизации поиска модулей для повторного использования.
Ощущение, что зря потратил время на чтение. Большое вступление и "решение" на один абзац, без всякой детализации, даже без пояснений кто это "мы" будет контролировать и кого? Команда Q&A будет контролировать решения сотни архитекторов через метрики и реверс-инженеринг?
Спасибо за обратную связь, поясню.
В данной публикации мы обозначили тему, которую раскроем в нескольких статьях. В следующем материале, речь пойдет про интеграцию Eclipse Modeling Framework в инструменты DevOps. И никаких электриков, архитекторов и представителей Q&A :)
Сегодня, мы поделились с Вами общей проблематикой управления компонентной архитектурой в крупном корпоративном приложении. Но связывая этот текст с предыдущей публикацией и анонсируя будущую, конкретизирую:
Но это же так скучно ;)
В данной публикации мы обозначили тему, которую раскроем в нескольких статьях. В следующем материале, речь пойдет про интеграцию Eclipse Modeling Framework в инструменты DevOps. И никаких электриков, архитекторов и представителей Q&A :)
Сегодня, мы поделились с Вами общей проблематикой управления компонентной архитектурой в крупном корпоративном приложении. Но связывая этот текст с предыдущей публикацией и анонсируя будущую, конкретизирую:
- Мы автоматизировали процесс создания отдельных компонент (выше по тексту — модули), осуществляя прямую генерацию самих компонент и всех слоев изоляции внутри модулей, непосредственно из самой функциональной конфигурации (см. предыдущую публикацию)
- Реализовано на базе EMF с созданием собственной Model2Model трансформации и далее Model2Java трансформации.
- Важно что все конфигурации в рабочем места аналитика заранее валидируются на M2M генерацию с поддержкой приведенных в статье шаблонов проектирования для типового функционала фронт-офиса.
- Естественно, любой код может быть доработан руками. Требуется проверять изменения на нарушения по зависимостям модулей, да и вообще использования типовых паттернов.
- Для этого мы строим JavaModel кода (выполняем reverse) и выполняем трансформацию в модель, аналогичную исходной, из которой шла генерация кода.
- Сравниваем, 2 модели, ищем расхождения. Допустимые включаются в модель (пока в полу ручном режиме). Не допустимые фиксируются в отчете и отправляются в команду, вносившую изменения в сгенерированный код.
Но это же так скучно ;)
А как вы строите Java-модель? С помощью JaMoPP?
На каком языке описываете преобразования модель-модель?
На каком языке описываете преобразования модель-модель?
Если я правильно понял, то у вас
1) исходная модель на языке UML2
2) затем она преобразуется в промежуточную модель (с помощью Model2Model преобразования, написанного на Java)
3) промежуточная модель преобразуется в Java-код (генератор кода тоже на Java)
И в обратную сторону:
1) Получаем объектную модель Java-кода с помощью JavaModel
2) Генерим промежуточную модель
3) Сравниваем эту промежуточную модель с промежуточной моделью, которую сгенерили из UML2 (см. выше) (сравнивалка написана на Java)
Всё правильно?
1) исходная модель на языке UML2
2) затем она преобразуется в промежуточную модель (с помощью Model2Model преобразования, написанного на Java)
3) промежуточная модель преобразуется в Java-код (генератор кода тоже на Java)
И в обратную сторону:
1) Получаем объектную модель Java-кода с помощью JavaModel
2) Генерим промежуточную модель
3) Сравниваем эту промежуточную модель с промежуточной моделью, которую сгенерили из UML2 (см. выше) (сравнивалка написана на Java)
Всё правильно?
Добрый день. Точно:
Преобразования в обратную сторону также идут, как Вы указали.
- Первая модель — это модель исходных функциональных элементов (формы, процессы, точки интеграции). Она совсем оторвана от языка, на котором будет генерироваться исходный код. Вводная по ней была в предыдущей статье.
- Вторая модель — это модель типовых паттернов, на базе компонентной модели, описанной в данной статье. Она уже ближе к фактической реализации и предполагает генерацию кода на ООП.
- Ну и в конце-концов — исходный код на Java
Преобразования в обратную сторону также идут, как Вы указали.
Мы тоже делаем подобные штуки с помощью EMF. Описываем на UML систему, для которой будет генериться код. И генерим Java, XSLT, XPath и т.п. Только все преобразования описаны на языке QVTo (стандарт, реализация Eclipse и моя статья с простыми примерами).
А парсинг или генерацию кода мы вообще не реализуем, это делается автоматически средствами EMFText (статья 1, статья 2).
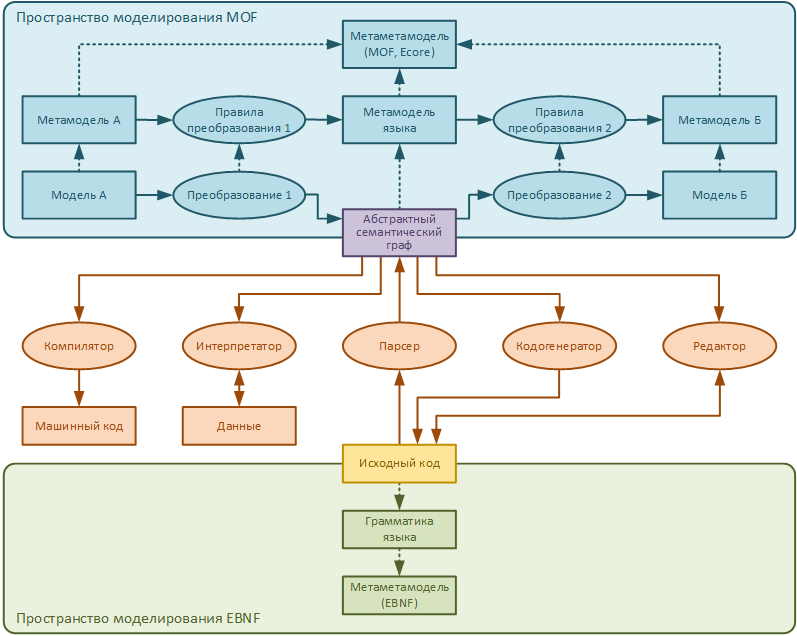
Вот, мозговыносная картинка из статьи, как оно у нас работает. Прямой путь — по стрелкам от модели А до исходного кода. И обратный — по стрелкам от исходного кода до модели Б. Парсер и кодогенератор мы не пишем, генерим их с помощью EMFText. А «преобразование 1» и «преобразование 2» пишем на QVTo.
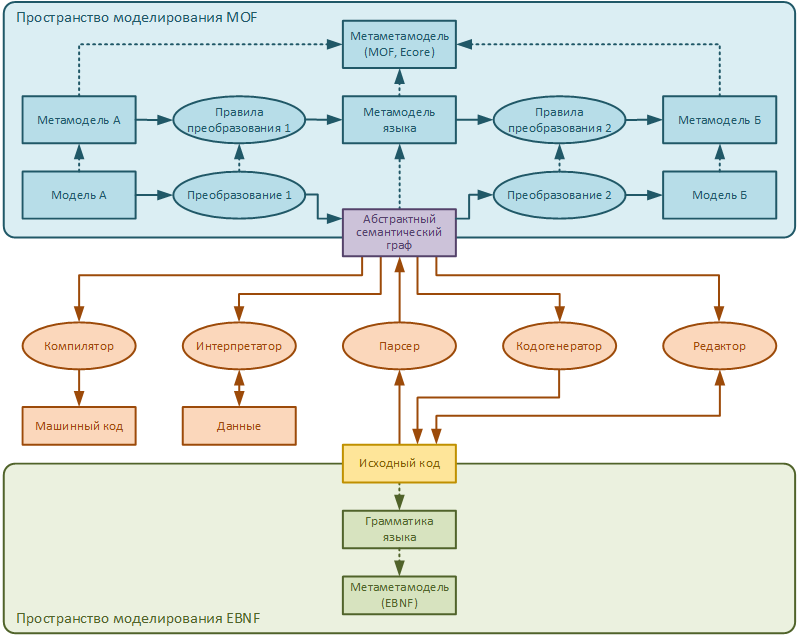
А парсинг или генерацию кода мы вообще не реализуем, это делается автоматически средствами EMFText (статья 1, статья 2).
Вот, мозговыносная картинка из статьи, как оно у нас работает. Прямой путь — по стрелкам от модели А до исходного кода. И обратный — по стрелкам от исходного кода до модели Б. Парсер и кодогенератор мы не пишем, генерим их с помощью EMFText. А «преобразование 1» и «преобразование 2» пишем на QVTo.
Drag — and — Drop
Stateful лучше писать в одно слово с одной буквой l.
Приглашаем на технологическую конференцию Сбербанка «Продвижение» 3 июня 2017г. в DI Telegraph (Москва, ул. Тверская 7).
В программе выступления по актуальным темам разработки и архитектуры, мастер-классы и демонстрация передовых разработок на основе технологий искусственного интеллекта, биометрии, дополненной и виртуальной реальности.
Вход свободный по предварительной регистрации https://ufs-programm.timepad.ru/event/490838/
Актуальная программа и новости мероприятия в группе https://www.facebook.com/groups/433394900345631/
В программе выступления по актуальным темам разработки и архитектуры, мастер-классы и демонстрация передовых разработок на основе технологий искусственного интеллекта, биометрии, дополненной и виртуальной реальности.
Вход свободный по предварительной регистрации https://ufs-programm.timepad.ru/event/490838/
Актуальная программа и новости мероприятия в группе https://www.facebook.com/groups/433394900345631/
Sign up to leave a comment.
Про технику безопасности, ядерную физику и любовь: о противоречиях современной ИТ-архитектуры фронтальных решений