Summary: Пост рассказывает о том, что такое снапшоты в облаке, как их использовать, и как они устроены.
Одна из самых заметных новых фич в облаке, появившаяся в этом году — снапшоты. Всё, что мы делаем, делится на три категории — то, что полезно нам (биллинг, сервисные утилиты и т. д.), то, что полезно клиентам, но визуально не заметно (например, СХД, смена версий гипервизора, уже ранее запущенных серверов), и то, что полезно клиентам и визуально заметно — и вот снапшоты как раз из этой третьей категории).
Хочу предупредить, что статья будет очень сложная. Я сначала расскажу про простые вещи — как с этим работать и какая от этого польза, а потом расскажу как это устроено внутри. И если с удобством и понятностью на «пользовательском» уровне мы, я надеюсь, справились, то вот с описанием устройства… Так сказать, мужайтесь или пропускайте.
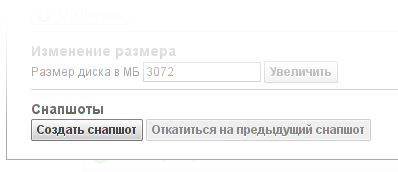
Снапшот может быть выполнен в любой момент времени, на включенной или выключенной машине. В момент выполнения снапшотов дисковая активность машины слегка приостанавливается (речь идёт о чём-то порядка секунды), после чего продолжается «как ни в чём ни бывало». Методов сделать снапшот два: в свойствах диска на странице с виртуальными машинами (там же есть кнопка «откатиться на предыдущий снапшот») и в списке снапшотов на странице с дисками. Там же есть список всех снапшотов диска. Заметим, для виртуальной машины мы обычно не даём возможности создать снапшот во время установки. Особопронырли внимательные клиенты могут найти, что кнопка «создать снапшот» на странице дисков всё-таки активна (и работает). Ничего интересного (кроме полу-установившегося линукса) в таком снапшоте не будет, но мы решили не забирать у людей возможность стрелять себе в ногу делать то, что они хотят со своими машинами.
Итак, созданный снапшот содержит в себе копию диска на момент создания. По размеру он чаще всего значительно меньше, чем диск. Если кому-то интересно, как высчитывается размер снапшота — смотрите вторую часть. Снапшоты образуют цепочку (если снапшоты делаются подряд) или дерево (как такое получается — см. раздел про откат на снапшот). Если удалить снапшот, то он начинает «растворяться» — объединяться с соседними (при этом общий объём снапшотов уменьшается). Процесс довольно быстрый (несколько минут — и снапшота нет).
Самой «вкусной» функцией снапшотов лично я считаю возможность подключить снапшот как диск. Подключается он в режиме read only (только для чтения), и позволяет посмотреть на «предыдущее» состояние диска. Никто не мешает сделать у диска 10 снапшотов и подключить все 10 к одной и той же машине — в этом случае диски будут представлять из себя хронологию «основного» диска.
Более того, снапшот можно подключать к любому количеству машин одновременно. (Сразу отвечаю на вопрос — можно ли грузиться с снапшота — формально, да, фактически файловая система очень нервничает от read only на root'е — мы работаем над этим вопросом).
Второй по важности функцией является откат диска на снапшот, то есть восстановление состояния диска. При этом изменения теряются, так что лучше перед откатом на старый снапшот сделать новый. В этом случае диск можно будет «переключать» между снапшотами (откатывать туда/обратно). У процесса отката на снапшот есть некоторые мелкие неудобства — становится недоступна статистика по дисковым операциям и неправильно показывается потребление машины в прошлом. Общее потребление по акаунту при этом высчитывается правильно, но так как образовывается новый VBD (блочное устройство), то данные для VM показываются для нового VBD. (Мы знаем про эту не очень очевидную особенность нашего биллинга и планируем его поменять на более удобную в обозримом времени).
Для удобства использования в последние несколько дней перед анонсом мы добавили «последний штрих» — если диск откатывается из снапшота, то у него появляется поле reverted_at (то есть «восстановлен из снапшота»). Мелочь, но полезная. Это поле будет преследовать диск до самой его смерти (и после, хе-хе, мы данные об объектах не удаляем).
Важный момент: каждый раз, когда делается или откатывается снапшот, наблюдается синдром «COW» (copy-on-write) — первая запись будет медленнее последующих. Так что на очень нагруженных серверах с большим количеством записи с созданию снапшотов следует относиться аккуратно.
Если сделать у диска несколько снапшотов, потом откатить диск на снапшот в «середине», потом сделать несколько снапшотов, потом откатить его на другой снапшот, потом снова откатить его, то образуется дерево снапшотов. Мы храним в нашей БД отношения — какой снапшот чьим является. К сожалению, визуализация пока в работе (программисты сильно протестуют, получив задачу «нарисовать дерево на JS», и пусть им будет стыдно при чтении этого поста).
Лимиты. К сожалению, вся эта роскошь не безгранична. Наши ограничения: длина цепочки снапшотов не более 20 дисков, максимальное количество снапшотов в дереве (с учётом ветвлений) — не более 60 шт. По нашим оценкам этого более чем достаточно для нормальной работы.
На странице «дисков» у каждого диска есть вкладка «снапшоты», где приводится список всех снапшотов диска. Снапшоты можно называть и давать им многострочное описание (но все ленивые, да, я тоже люблю, когда эти поля заполнены, но заполнять их обычно очень лень). В любом случае снапшот может быть уникально идентифицирован по абсолютно бесполезному номеру (англ. universally useless ID, uuid) и (частично) по дате создания.
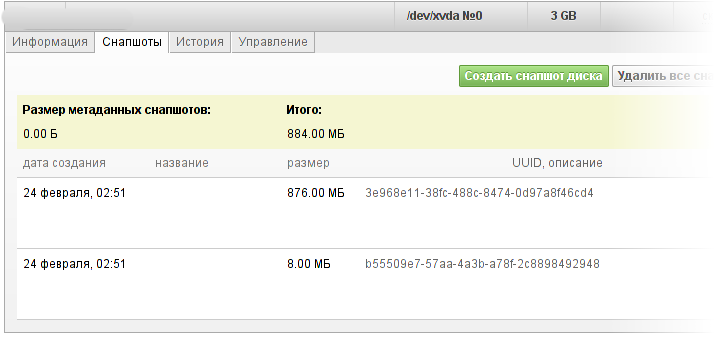
Немного о поле «итого». В силу некоторых особенностей работы системы информация о снапшотах обновляется неравномерно — список снапшотов обновляется сразу после создания снапшотов, а вот поле «итого» может запаздывать некоторое время — до двух минут. В отличие от остальных ресурсов, которые мы обсчитываем в реальном времени, диски и снапшоты учитываются с (примерно) двухминутным интервалом. Поле «итого» высчитывается в момент вычисления объёма потребления, так что «итого» сразу после создания снапшота будет некорректным (но точно придёт в норму к следующему тику списания).
(просьба убрать от экранов несовершеннолетних детей и лиц с повышенной восприимчивостью, сейчас будет хардкор).
Наши снапшоты (как и диски) основываются на VHD-формате, который был придуман microsoft, отдан в публичное пользование и использован citrix. Он поддерживает очень эффективные снапшоты (они много эффективнее, чем снапшоты LVM, которые увеличивают количество записей пропорционально числу снапшотов). Когда выстраивается цепочка снапшотов, там неявным образом подразумевается «нулевой» снапшот, относительно которого фиксируются изменения всех остальных (без этого «нулевого» снапшота становится не понятно — что за «изменения» хранятся в первом снапшоте). Нулевой снапшот, разумеется, не оплачивается (т.к. физически места на диске не занимает).
При записи в «дырявый» блок этот блок копируется из «старого» снапшота в текущий диск (та часть, которую записали, заменяется, остальное берётся в предыдущей копии). После записи в текущем диске становится на одну дырку меньше и чтение этого места в дальнейшем идёт с «текущего» диска. Дисковые операции для дисков с снапшотами стоят столько же, сколько и обычные дисковые операции (лично я не уверен, насколько операции над снапшотами оказываются тяжелее обычных для наших СХД, так что решили эту область не трогать).
Что происходит при создании снапшота? (Техническая часть).
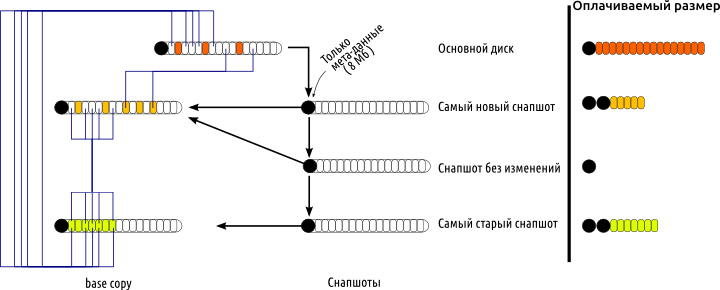
Текущий диск объявляется так называемым 'base copy', то есть read only копией состояния машины. Так как у диска могли быть предшественники в цепочке снапшотов, то base copy ссылается на другие base copy (заметим, base copy всегда ссылается только на base copy). Кроме этого делается ещё «снапшот» — это read/write копия текущего состояния (то есть отличия снапшота от base copy). В общем случае в снапшоты можно писать, но мы это запрещаем, так как в этом случае получится thin provision, а мы не можем его допустить из соображений гарантированности зарезервированного пространства (см раздел ниже). Но даже «незаписанный» снапшот содержит в себе 8Мб мета-данных. Таким образом, каждый снапшот состоит из двух половинок: метаданных (8Мб) и содержимого base copy. Диск ссылается одним видом ссылок на base copy предыдущего снапшота, а вторым видом ссылок на «снапшот». Когда происходит откат диска, то снапшот клонируется (не копируется — отсюда и нюансы с COW), ссылаясь на тот же самый base copy, на который ссылался снапшот, который был клонирован.
Если же кто-то два-три раза подряд сделает снапшот (без изменений данных), то получится одна base copy и три снапшота с мета-данными.
Когда снапшот удаляется (из середины), то происходит следующее: сам снапшот (метаданные) удаляется сразу, а вот base copy начинает расформировываться — данные переносятся либо в «предыдущее» состояние, либо в «будущее», либо вообще выкидываются (если есть альтернативное состояние и в прошлом, и в будущем). Этот процесс и есть «таяние» снапшота, которое происходит не мгновенно. Нужно сказать, что данные фактически не копируются, а всего лишь «перемаркируются» в рамках LVM (LE перекидываются между разными LV), либо удаляются (если в предыдущей копии есть другая версия блока).
Один из вопросов, который нам задают по СХД, связан с thin provision. Что такое thin provision? Это когда потребителю декларируется некоторый объём места, а реально занятое место меньше — и увеличивается по мере фактической записи. Это отлично ложится на нашу модель с снапшотами, COW из «пустого места», да и в XCP реализовано отлично. Фактически, thin provision — это «запись в снапшот», то есть запись в «пустое место», которое от этого начинает занимать место в реальности.
Однако, thin provision опасен. Обратная сторона thin provision — overselling (он же oversubscription). Грубо говоря, есть у нас 100Тб места. Мы разрешили создать на таком хранилище 200 дисков по 1Тб. Фактический размер дисков в начале — гигабайт по 30-50, так что свободного места вволю. Но, вдруг, клиенты начинают писать на диски. Диски-то им уже выделены. Проходит немного времени, и… да, среднее заполнение дисков подползает к 500Гб. А потом… Потом кто-то хочет записать очередной гигабайт, но получает ошибку. Потому что место закончилось.
Мы не властны над дисками клиентов, и если мы им предоставили ресурсы — эти ресурсы их, и не наше дело говорить «сейчас можно, а сейчас нет». Если в отношении других ресурсов может быть компромисс (кому-то 3% процессора не дали, кого-то мигрировали на другой хост, чтобы обеспечить запас производительности), то есть незначительная «недопоставка» просто не ощутима, то в отношении дискового пространства такое не получится. Не дали записать хотя бы один сектор — по всему блочному устройству фиксируется ошибка.
Так что по здравому размышлению мы решили так не делать.
Из-за того, что снапшоты делаются в R/O, а после создания только уменьшаются, мы можем отказать в создании нового снапшота (всякое бывает — может и место внезапно кончиться), но мы точно не откажем в работе уже созданных дисков и снапшотов.
Одна из самых заметных новых фич в облаке, появившаяся в этом году — снапшоты. Всё, что мы делаем, делится на три категории — то, что полезно нам (биллинг, сервисные утилиты и т. д.), то, что полезно клиентам, но визуально не заметно (например, СХД, смена версий гипервизора, уже ранее запущенных серверов), и то, что полезно клиентам и визуально заметно — и вот снапшоты как раз из этой третьей категории).
Хочу предупредить, что статья будет очень сложная. Я сначала расскажу про простые вещи — как с этим работать и какая от этого польза, а потом расскажу как это устроено внутри. И если с удобством и понятностью на «пользовательском» уровне мы, я надеюсь, справились, то вот с описанием устройства… Так сказать, мужайтесь или пропускайте.
Как использовать снапшоты?
Самым типовым применением снапшотов является создание резервных копий на случай ошибки в настройке машины. Сразу хочу предупредить, это важно: снапшоты хранятся там же, где и диски. Это означает, что если на нас упадёт метеорит или придёт другое стихийное бедствие федерального значения, то снапшоты будут утеряны одновременно с дисками, то есть для полноценных резервных копий следует использовать другое, географически от нас удалённое, место хранения. Мы совершенно не планируем терять диски клиентов или допускать стихийные бедствия в серверную, но предупредить я всё-таки обязан.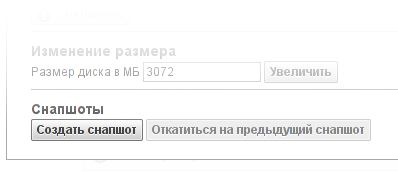
Снапшот может быть выполнен в любой момент времени, на включенной или выключенной машине. В момент выполнения снапшотов дисковая активность машины слегка приостанавливается (речь идёт о чём-то порядка секунды), после чего продолжается «как ни в чём ни бывало». Методов сделать снапшот два: в свойствах диска на странице с виртуальными машинами (там же есть кнопка «откатиться на предыдущий снапшот») и в списке снапшотов на странице с дисками. Там же есть список всех снапшотов диска. Заметим, для виртуальной машины мы обычно не даём возможности создать снапшот во время установки. Особо
Итак, созданный снапшот содержит в себе копию диска на момент создания. По размеру он чаще всего значительно меньше, чем диск. Если кому-то интересно, как высчитывается размер снапшота — смотрите вторую часть. Снапшоты образуют цепочку (если снапшоты делаются подряд) или дерево (как такое получается — см. раздел про откат на снапшот). Если удалить снапшот, то он начинает «растворяться» — объединяться с соседними (при этом общий объём снапшотов уменьшается). Процесс довольно быстрый (несколько минут — и снапшота нет).
Самой «вкусной» функцией снапшотов лично я считаю возможность подключить снапшот как диск. Подключается он в режиме read only (только для чтения), и позволяет посмотреть на «предыдущее» состояние диска. Никто не мешает сделать у диска 10 снапшотов и подключить все 10 к одной и той же машине — в этом случае диски будут представлять из себя хронологию «основного» диска.
Более того, снапшот можно подключать к любому количеству машин одновременно. (Сразу отвечаю на вопрос — можно ли грузиться с снапшота — формально, да, фактически файловая система очень нервничает от read only на root'е — мы работаем над этим вопросом).
Второй по важности функцией является откат диска на снапшот, то есть восстановление состояния диска. При этом изменения теряются, так что лучше перед откатом на старый снапшот сделать новый. В этом случае диск можно будет «переключать» между снапшотами (откатывать туда/обратно). У процесса отката на снапшот есть некоторые мелкие неудобства — становится недоступна статистика по дисковым операциям и неправильно показывается потребление машины в прошлом. Общее потребление по акаунту при этом высчитывается правильно, но так как образовывается новый VBD (блочное устройство), то данные для VM показываются для нового VBD. (Мы знаем про эту не очень очевидную особенность нашего биллинга и планируем его поменять на более удобную в обозримом времени).
Для удобства использования в последние несколько дней перед анонсом мы добавили «последний штрих» — если диск откатывается из снапшота, то у него появляется поле reverted_at (то есть «восстановлен из снапшота»). Мелочь, но полезная. Это поле будет преследовать диск до самой его смерти (и после, хе-хе, мы данные об объектах не удаляем).
Важный момент: каждый раз, когда делается или откатывается снапшот, наблюдается синдром «COW» (copy-on-write) — первая запись будет медленнее последующих. Так что на очень нагруженных серверах с большим количеством записи с созданию снапшотов следует относиться аккуратно.
Если сделать у диска несколько снапшотов, потом откатить диск на снапшот в «середине», потом сделать несколько снапшотов, потом откатить его на другой снапшот, потом снова откатить его, то образуется дерево снапшотов. Мы храним в нашей БД отношения — какой снапшот чьим является. К сожалению, визуализация пока в работе (программисты сильно протестуют, получив задачу «нарисовать дерево на JS», и пусть им будет стыдно при чтении этого поста).
Лимиты. К сожалению, вся эта роскошь не безгранична. Наши ограничения: длина цепочки снапшотов не более 20 дисков, максимальное количество снапшотов в дереве (с учётом ветвлений) — не более 60 шт. По нашим оценкам этого более чем достаточно для нормальной работы.
На странице «дисков» у каждого диска есть вкладка «снапшоты», где приводится список всех снапшотов диска. Снапшоты можно называть и давать им многострочное описание (но все ленивые, да, я тоже люблю, когда эти поля заполнены, но заполнять их обычно очень лень). В любом случае снапшот может быть уникально идентифицирован по абсолютно бесполезному номеру (англ. universally useless ID, uuid) и (частично) по дате создания.

Немного о поле «итого». В силу некоторых особенностей работы системы информация о снапшотах обновляется неравномерно — список снапшотов обновляется сразу после создания снапшотов, а вот поле «итого» может запаздывать некоторое время — до двух минут. В отличие от остальных ресурсов, которые мы обсчитываем в реальном времени, диски и снапшоты учитываются с (примерно) двухминутным интервалом. Поле «итого» высчитывается в момент вычисления объёма потребления, так что «итого» сразу после создания снапшота будет некорректным (но точно придёт в норму к следующему тику списания).
Как это устроено?
(просьба убрать от экранов несовершеннолетних детей и лиц с повышенной восприимчивостью, сейчас будет хардкор).
Наши снапшоты (как и диски) основываются на VHD-формате, который был придуман microsoft, отдан в публичное пользование и использован citrix. Он поддерживает очень эффективные снапшоты (они много эффективнее, чем снапшоты LVM, которые увеличивают количество записей пропорционально числу снапшотов). Когда выстраивается цепочка снапшотов, там неявным образом подразумевается «нулевой» снапшот, относительно которого фиксируются изменения всех остальных (без этого «нулевого» снапшота становится не понятно — что за «изменения» хранятся в первом снапшоте). Нулевой снапшот, разумеется, не оплачивается (т.к. физически места на диске не занимает).
При записи в «дырявый» блок этот блок копируется из «старого» снапшота в текущий диск (та часть, которую записали, заменяется, остальное берётся в предыдущей копии). После записи в текущем диске становится на одну дырку меньше и чтение этого места в дальнейшем идёт с «текущего» диска. Дисковые операции для дисков с снапшотами стоят столько же, сколько и обычные дисковые операции (лично я не уверен, насколько операции над снапшотами оказываются тяжелее обычных для наших СХД, так что решили эту область не трогать).
Что происходит при создании снапшота? (Техническая часть).

Текущий диск объявляется так называемым 'base copy', то есть read only копией состояния машины. Так как у диска могли быть предшественники в цепочке снапшотов, то base copy ссылается на другие base copy (заметим, base copy всегда ссылается только на base copy). Кроме этого делается ещё «снапшот» — это read/write копия текущего состояния (то есть отличия снапшота от base copy). В общем случае в снапшоты можно писать, но мы это запрещаем, так как в этом случае получится thin provision, а мы не можем его допустить из соображений гарантированности зарезервированного пространства (см раздел ниже). Но даже «незаписанный» снапшот содержит в себе 8Мб мета-данных. Таким образом, каждый снапшот состоит из двух половинок: метаданных (8Мб) и содержимого base copy. Диск ссылается одним видом ссылок на base copy предыдущего снапшота, а вторым видом ссылок на «снапшот». Когда происходит откат диска, то снапшот клонируется (не копируется — отсюда и нюансы с COW), ссылаясь на тот же самый base copy, на который ссылался снапшот, который был клонирован.
Если же кто-то два-три раза подряд сделает снапшот (без изменений данных), то получится одна base copy и три снапшота с мета-данными.
Когда снапшот удаляется (из середины), то происходит следующее: сам снапшот (метаданные) удаляется сразу, а вот base copy начинает расформировываться — данные переносятся либо в «предыдущее» состояние, либо в «будущее», либо вообще выкидываются (если есть альтернативное состояние и в прошлом, и в будущем). Этот процесс и есть «таяние» снапшота, которое происходит не мгновенно. Нужно сказать, что данные фактически не копируются, а всего лишь «перемаркируются» в рамках LVM (LE перекидываются между разными LV), либо удаляются (если в предыдущей копии есть другая версия блока).
Немного о thin provision
Один из вопросов, который нам задают по СХД, связан с thin provision. Что такое thin provision? Это когда потребителю декларируется некоторый объём места, а реально занятое место меньше — и увеличивается по мере фактической записи. Это отлично ложится на нашу модель с снапшотами, COW из «пустого места», да и в XCP реализовано отлично. Фактически, thin provision — это «запись в снапшот», то есть запись в «пустое место», которое от этого начинает занимать место в реальности.
Однако, thin provision опасен. Обратная сторона thin provision — overselling (он же oversubscription). Грубо говоря, есть у нас 100Тб места. Мы разрешили создать на таком хранилище 200 дисков по 1Тб. Фактический размер дисков в начале — гигабайт по 30-50, так что свободного места вволю. Но, вдруг, клиенты начинают писать на диски. Диски-то им уже выделены. Проходит немного времени, и… да, среднее заполнение дисков подползает к 500Гб. А потом… Потом кто-то хочет записать очередной гигабайт, но получает ошибку. Потому что место закончилось.
Мы не властны над дисками клиентов, и если мы им предоставили ресурсы — эти ресурсы их, и не наше дело говорить «сейчас можно, а сейчас нет». Если в отношении других ресурсов может быть компромисс (кому-то 3% процессора не дали, кого-то мигрировали на другой хост, чтобы обеспечить запас производительности), то есть незначительная «недопоставка» просто не ощутима, то в отношении дискового пространства такое не получится. Не дали записать хотя бы один сектор — по всему блочному устройству фиксируется ошибка.
Так что по здравому размышлению мы решили так не делать.
Из-за того, что снапшоты делаются в R/O, а после создания только уменьшаются, мы можем отказать в создании нового снапшота (всякое бывает — может и место внезапно кончиться), но мы точно не откажем в работе уже созданных дисков и снапшотов.
