Shrinking .NET Console Application
3 min
Translation
Building console application can produce an unexpectedly much larger file than you would think due to implicit references.
What is the problem and how it can be solved?
Building console application can produce an unexpectedly much larger file than you would think due to implicit references.
What is the problem and how it can be solved?

At the very beginning of this year, Apple released the source code for macOS – Big Sur. It includes XNU, the kernel of the macOS operating system. A few years ago, PVS-Studio has already checked the kernel source code. It coincided with the analyzer release on macOS. It's been a while since then. The new kernel source code has been released. A second check? Why not?

Algebra and language (writing) are two different learning tools. When they are combined, we can expect new methods of machine understanding to emerge. To determine the meaning (to understand) is to calculate how the part relates to the whole. Modern search algorithms already perform the task of meaning recognition, and Google’s tensor processors perform matrix multiplications (convolutions) necessary in an algebraic approach. At the same time, semantic analysis mainly uses statistical methods. Using statistics in algebra, for instance, when looking for signs of numbers divisibility, would simply be strange. Algebraic apparatus is also useful for interpreting the calculations results when recognizing the meaning of a text.
Author: Chris Punches (@cmpunches, Silo group). License: "Please feel free to share unmodified".
The following text is an unmodified copy of now removed issue #2250 on rms-open-letter.github.io repository. The text claims multiple violations of different policies, codes of conduct and other documents in creation, content and support of the "Open letter to remove Richard M. Stallman from all leadership positions". The issue has not been addressed.

Reverse engineering might seem so complex, that not everyone has the bravery required to tackle it. But is it really that hard? Today we are gonna dive into the process of learning how to reverse engineer.
First of all, try to answer yourself, what are you hoping to achieve with reverse engineering? Because reverse engineering is a tool. And you should choose the right tool for your task. So when reverse engineering might be useful?

Most influential programmers say that code must be self-documenting. They find comments useful only when working with something uncommon. Our team shares this opinion. Recently we came across a code snippet that perfectly proves it.

By the beginning of 2021, Qrator Labs filtering network expands to 14 scrubbing centers and a total of 3 Tbps filtering bandwidth capacity, with the San Paolo scrubbing facility fully operational in early 2021;
New partner services fully integrated into Qrator Labs infrastructure and customer dashboard throughout 2020: SolidWall WAF and RuGeeks CDN;
Upgraded filtering logic allows Qrator Labs to serve even bigger infrastructures with full-scale cybersecurity protection and DDoS attacks mitigation;
The newest AMD processors are now widely used by Qrator Labs in packet processing.
DDoS attacks were on the rise during 2020, with the most relentless attacks described as short and overwhelmingly intensive.
However, BGP incidents were an area where it was evident that some change was and still is needed, as there was a significant amount of devastating hijacks and route leaks.
In 2020, we began providing our services in Singapore under a new partnership and opened a new scrubbing center in Dubai, where our fully functioning branch is staffed by the best professionals to serve local customers.
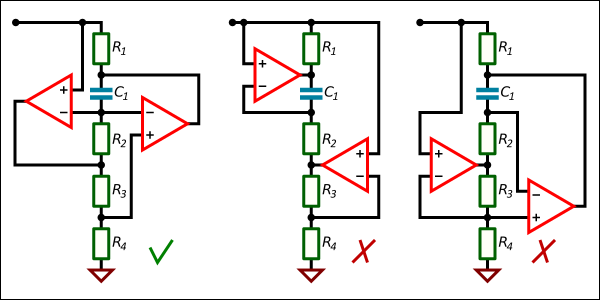

Users sometimes ask how new diagnostics appear in the PVS-Studio static analyzer. We answer that we draw inspiration from a variety of sources: books, coding standards, our own mistakes, our users' emails, and others. Recently we came up with an interesting idea of a new diagnostic. Today we decided to tell the story of how it happened.


The step has been made. Not sure where to, but for sure from the point of no return. Keep calm and keep walking. It is about time to look around and understand the smelly and slippery route before you. And what are those noisy creatures swarming around our fishy “innovative” design we called Mandelbrot blueprint? You don't get a buzzing noise like that, just buzzing and buzzing, without its meaning something.
In microservice world the problem of high load is exteremely big especially when we have a REST API which is accessed quite extensively. Why do we need throttling? The main answer is to decrease the load of the service at the moment.
Different frameworks have different solutions, mostly some additional libraries. Also there is a Guava RateLimiter and Bucket4J . What is interesting Spring MVC being one of the most popular solutions for building REST APIs (thank you Spring Boot) doesn't have any built in rate limiter. As for external solutions there not that many ways around.
Today, I would like to present a tiny experimental library specific for Spring MVC. It is called SpringRateLimitter. The library is very tiny ,works in runtime. The idea is to annotate entire rest controller or specific method , than count the number of incoming requests for the annotated URI and based on the values check if we exceed the allowed number of calls. In case of exceeding an HTTP error code 429 is thrown and after the throttling period is over , the endpoint is available again.
So How does it look like. As first step Maven dependency must be added
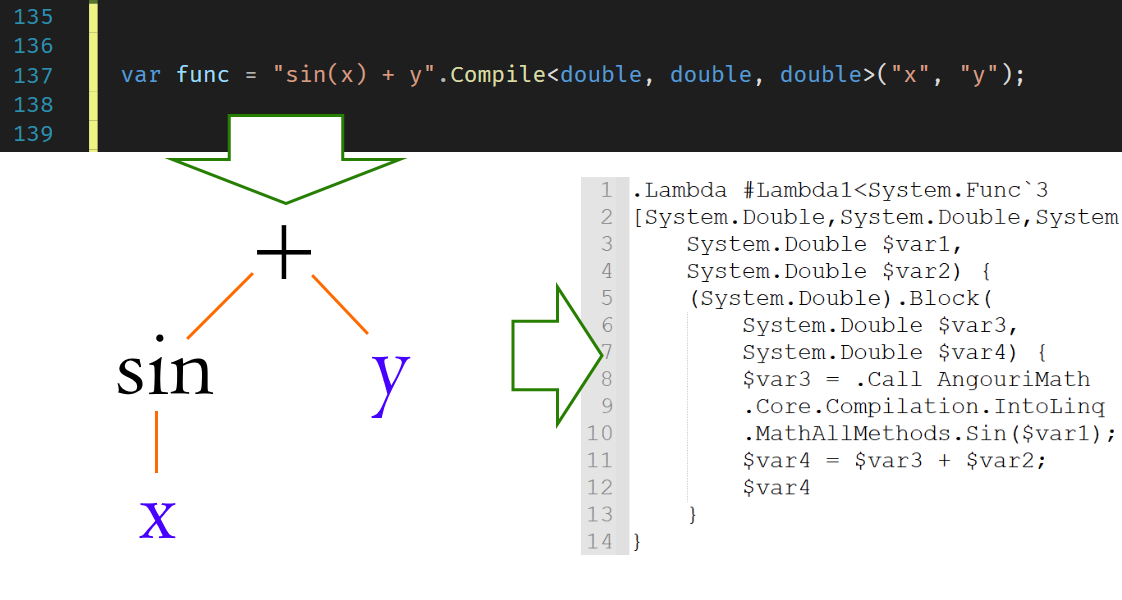
Here I am going to cover my own approach to compilation of mathematical functions into Linq.Expression. What we are going to have implemented at the end:
1. Arithmetical operations, trigonometry, and other numerical functions
2. Boolean algebra (logic), less/greater and other operators
3. Arbitrary types as the function's input, output, and those intermediate
Hope it's going to be interesting!
Architect. This word sounds so mysterious. So mysterious that to understand it you are almost forced to add something. Like “System Architect” or “Program Architect”. Such an addition does not make it clearer, but for sure adds weight to the title. Now you know – that’s some serious guy! I prefer to make undoubtful and around 10 years ago added to my email signature “Enterprise Architect of Information Systems”. It’s a powerful perk. Like “Chosen One”. With architects it is always the matter of naming, you know. Maybe that is why the only way to become an architect is to be named as one by others. Like with vampires. One of them has to byte you! That is probably the easiest way to earn the title as there is no degree or school to grant you one. And if there’s a troubling title, somebody’s making a trouble, and the only reason for making a trouble that I know of is because you’re an Enterprise. Huge old and complex multinational corporation. Like a one-legged pirate. Strong and scary, but not a good runner. You own your ship, you had good days, you have some gold, you need new ways.
To get to new treasures and avoid losing the second leg to piranha regulators and local business sharks swarming waters near every enterprise ship – every pirate has a map. A map is a list of major features and requirements in desired order and priority.

Security. What does this word mean to you? Nowadays, companies spare no effort to ensure that their product is secured from hacking and all sorts of information leaks. PVS-Studio decided to help its users and expand the functionality in this area. Therefore, one of the main innovations of the upcoming release will be the introduction of analyzer new features which will ensure code safety and security. This article aims to present these features.
Some of the features of your website require message queue integration. It is not a complex task for most developers. If you work with Azure infrastructure, you are able to choose Azure Service Bus as a queue engine. It sounds quite simple: just create Azure Resource, write some code and then be happy! But what would you say if the resources are limited? What will you do if there are several teammates in your team, and all of you have to debug queues at the same time? I try to give you a simple solution.
Most solutions to algorithmic problems can be grouped into a rather small number of patterns. When we start to solve some problem, we need to think about how we would classify them. For example, can we apply fast and slow аlgorithmic pattern or do we need to use cyclic sortpattern? Some of the problems have several solutions based on different patterns. In this series, we discuss the most popular algorithmic patterns that cover more than 90% of the usual problems.
It is different from High-School Algorithms 101 Course, as it is not intended to cover things like Karatsuba algorithm (fast multiplication algorithm) or prove different methods of sorting. Instead, Algorithmic Patterns focused on practical skills needed for the solution of common problems. For example, when we set up a Prometheus alert for high request latency we are dealing with Sliding Window Pattern. Or let say, we organize a team event and need to find an available time slot for every participant. At the first glance, it is not obvious that in this case, we are actually solving an algorithmic problem. Actually, during our day we usually solve a bunch of algorithmic problems without realizing that we dealing with algorithms.
The knowledge about Algorithmic Patterns helps one to classify a problem and then apply the appropriate method.
But probably most importantly learning algorithmic patterns boost general programming skills. It is especially helpful when you are debugging some production code, as it trains you to understand the execution flow.
Patterns covered so far:
Stay tuned :)
<Promo> If you interested to work as a backend engineer, there is an open position in my squad. Prior knowledge of Golang is not required. I am NOT an HR and DO NOT represent the company in any capacity. However, I can share my personal experience as a backend engineer working in the company. </Promo>
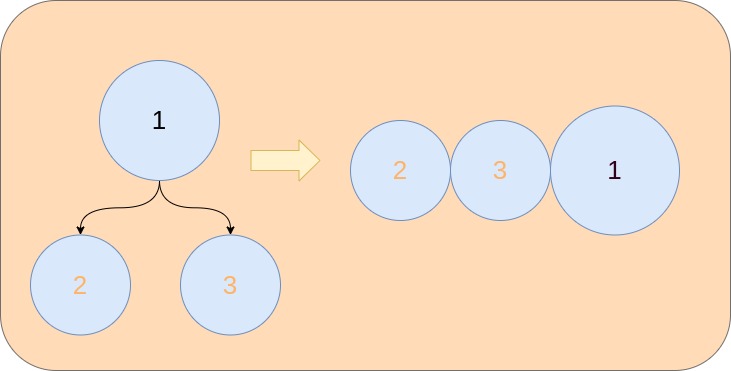
In this article, we discuss the postorder traversal of a binary tree. What does postorder traversal mean? It means that at first, we process the left subtree of the node, then the right subtree of the node, and only after that we process the node itself.
Why would we need to do it in this order? This approach solves an entire class of algorithmic problems related to the binary trees. For example, to find the longest path between two nodes we need to traverse the tree in a postorder manner. In general, postorder traversal is needed when we cannot process the node without processing its children first. In this manner, for example, we can calculate the height of the tree. To know the height of a node, we need to calculate the height of its children and increment it by one.
Let's start with a recursive approach. We need to process the left child, then the right child and finally we can process the node itself. For simplicity, let's just save the values into slice out.
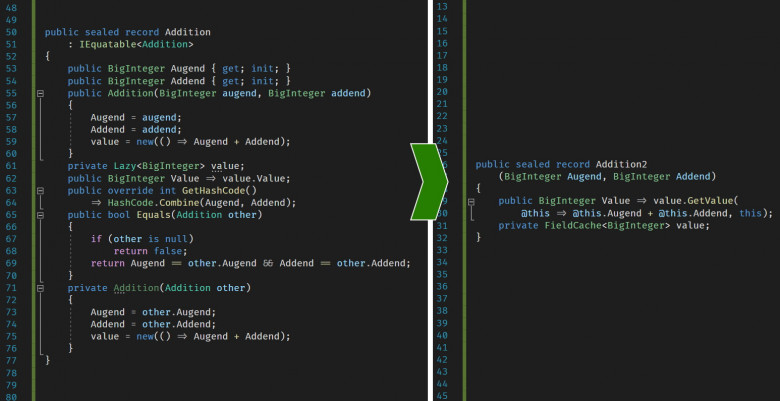
Let me also say a word about properties. I'm going to consider a good use of them for immutable records in C#.
I am a big fan of code design, so in this article I want to cover existing approaches and show what, I think, is a better solution.

Having only programming background, it is impossible to develop software in some areas. Take the difficulties of medical software development as an example. The same is with music software, which will be discussed in this article. Here you need an advice of subject matter experts. However, it's more expensive for software development. That is why developers sometimes save on code quality. The example of the MuseScore project check, described in the article, will show the importance of code quality expertise. Hopefully, programming and musical humor will brighten up the technical text.









