The flag of the Netherlands consists of three colors: red, white and blue. Given balls of these three colors arranged randomly in a line (it does not matter how many balls there are), the task is to arrange them such that all balls of the same color are together and their collective color groups are in the correct order.
For simplicity instead of colors red, white, and blue we will be dealing with ones, twos and zeroes.
Let's start with our intuition. We have an array of zeroth, ones, and twos. How would we sort it? Well, we could put aside all zeroes into some bucket, all ones into another bucket, and all twos into the third. Then we can fetch all items from the first bucket, then from the second, and from the last bucket, and restore all the items. This approach is perfectly fine and has a great performance. We touch all the elements when we iterate through the array, and then we iterate through all the elements once more when we "reassamble" the array. So, the overall time complexity is O(n) + O(n) ~= O(n). The space complexity is also O(n) as we need to store all items in the buckets.
Can we do better than that? There is no way to improve our time complexity. However, we can think of a more efficient algorithm in regard to space complexity. How would we solve the problem without the additional buckets?
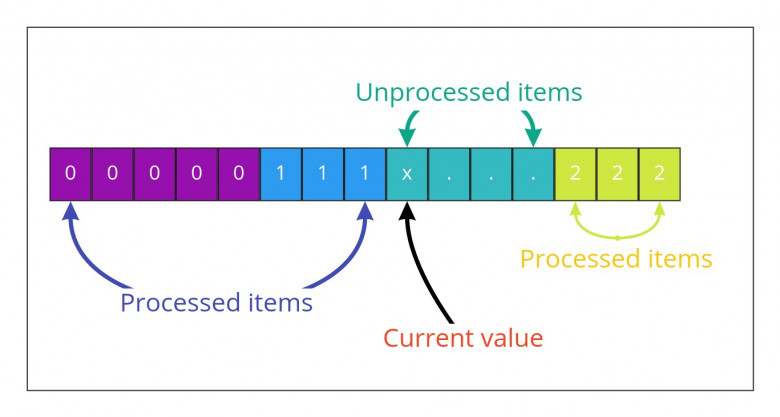
Let's make a leap of faith and pretend that somehow we were able to process a part of the array. We iterate through part of the array and put encountered zeroes and ones at the beginning of the array, and twos at the end of the array. Now, we switched to the next index i with some unprocessed value x. What should we do there?