Балуясь с нейронными сетями и алгоритмами самообучения для них, столкнулся с мыслью, что алгоритм обучения с учителем вполне мог бы быть отнесен к категории самообучения, если бы учителя заменили «эмоциональными» нейронами. Такие нейроны, по сути, являются просто датчиками «хорошо/плохо», а при соединении с обычными нейронами создают определенные связи, гасящие либо возбуждающие в зависимости от типа датчика. Это исключительно поверхностное описание принципа, который не развивался в нейронауке по двум простым причинам.
1. Современные сети не обладают одновременной стабильностью и пластичностью, то есть процесс корректной работы сети не совместим с её обучением. Современные сети, обучаясь новому, успешно забывают старое, поэтому для работы используется неизменяемый слепок нейросети после обучения, которым никак управлять не надо.
2. Специфика наших требований к рабочей сети, даже если она обладает одновременной стабильностью и пластичностью, не позволяет ей допускать ошибки, а ведь избежать этого в обучении невозможно. Зачем спрашивается нам система, которая не только может физически поломаться, но и обладающая чем то, вроде «человеческого фактора»?
Я поставил себе цель создать модель на нейронной сети для управления амебой в плоском пространстве, стремящейся развернутся в сторону цели и добраться до неё. Задача очень тривиальная, но вся проблема была в том, что амеба должна научиться этому сама и без моей помощи. Ведь создавая автоматические системы, мы до сих пор заранее задаем все решения для всего набора условий той конкретной задачи, которую будут выполнять автоматы, а так же не даем возможности системам обучаться в процессе их функционирования. Красивыми словами это можно описать так: «Решение задачи не закладывается в систему управления заранее, мы перекладываем на систему не только выполнение задачи, но и нахождение решения этой задачи».
Мы настолько привыкли заранее закладывать решения в автоматические системы, что сложно представить абстрактную модель самообучающейся и самостоятельно находящей решения автоматической системы. Не надо наступать на те же грабли, думая, что в финале нам надо просто сообщить в какой либо форме как решать задачу. Автомат когда-нибудь и сможет понять получаемую от нас информацию и использовать чужой опыт, но в действительности мы должны будем начинать работать с системой, которая не обладает еще никакими навыками кроме возможности обучаться, воспринимать окружающую среду и воздействовать на неё. Получается из обычной автоматической системы нужно сразу выкинуть заранее вложенное решение, и положить в нее вычислительную подсистему, в которой реализовано что-то вроде наших мозгов. Поэтому я и использую нейронную сеть, как ближайшее подобие мозга.
Но после первой встречи с таким автоматом вы поймёте, что он полный аутист, пофигист и окружающий мир ему глубоко безразличен. А нам все же нужно, что бы он смог тоже, что и до того как мы выкинули наше вложенное решение. Я упустил одну важную вещь, забыл поставить перед системой условие решения нашей задачи. Системе нужно дать понять, когда ее действия удовлетворяют условиям решения нашей задачи и наоборот. Центральным словом здесь является слово «понять», причем именно нейросеть должна «понять», что мы от неё хотим. Ничего особенного здесь выдумывать не нужно, всего лишь примитивно повторить уже существующий, и да, заранее заложенный в нас «язык эмоций». Я сейчас особо не буду распространяться про единственный общий «язык эмоций». Скажу только, что все мы не только чувствуем эмоции, но и одинаково реагируем на них, показывая языком тела, что мы чувствуем. То, что мы будем использовать – метод кнута и пряника, ведь он работает даже с простейшими животными, подразумевает наличие эмоциональных чувств приятного и неприятного (боли). Мы же наделены большим набором эмоций, чем эти чувства, но такого набора вполне достаточно для модели амебы и нашей задачи. Добавлением датчиков поворота к цели, движения к цели и наоборот, а также добавляя эмоциональную окраску к ним, мы объясняем задачу и мотивируем нейросеть решить нашу задачу.
Это ключевой момент для нейронной сети, так как мы вводим систему мотивации и общения (по крайней мере мы сможем «обращаться» к амебе). Поведение нашей амебы у внешнего наблюдателя будет вызывать стойкую ассоциацию с мотивированным поведением и с присутствием эмоционального восприятия у неё.
Далее собственно описание устройства нейронов, датчиков и нейросети в целом, коротко, но довольно сложно из-за отсутствия объяснений, почему так. К прочтению не обязательно. Можно прочитать выводы.
Основные свойства модели нейронов, которые я использую.
Нейроны в моей сети делятся на несколько типов
Сеть представляет собой двухмерное пространство, в котором задается положение нейронов координатами, из-за ограниченного радиуса ответственности связи устанавливаются только между близкорасположенными нейронами. В самом начале между нейронами связей нет вообще. Эффекторы произвольно активируются пока не установятся первые связи. Связи устанавливаются тем быстрее, чем ближе и чаще нейроны одновременно активны (правило Хебба). В финале топология выглядит так.
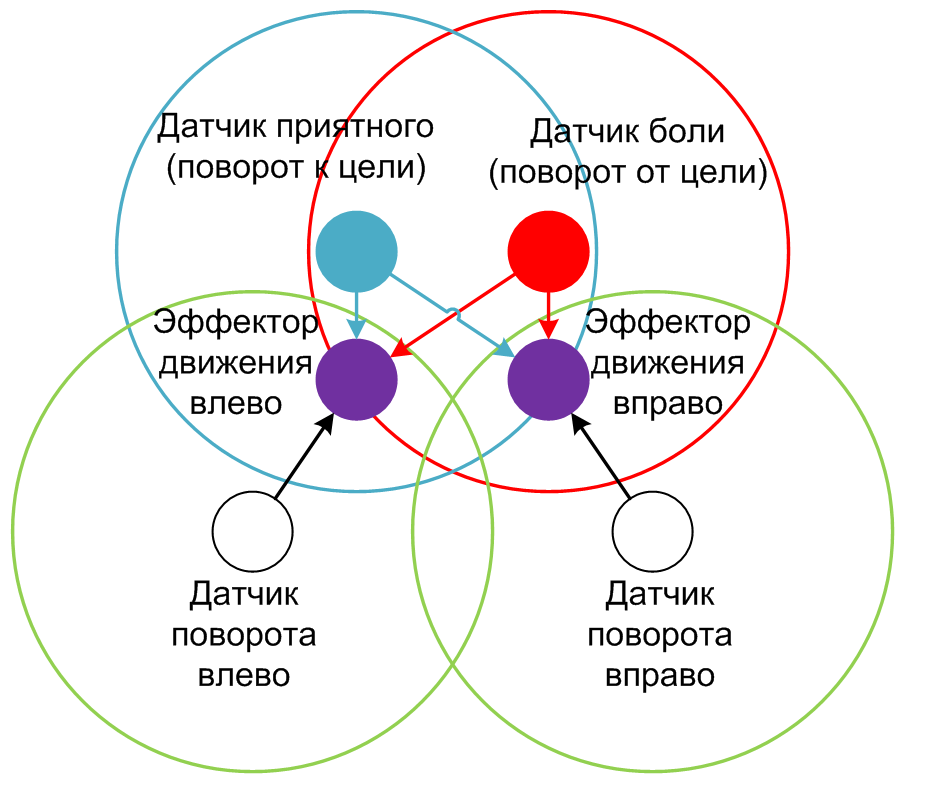
Рис 1. Топология участка нейросети отвечающего за повороты
Кругами обозначены зоны ответственности нейронов. Такую же топологию имеет и часть нейросети отвечающая за перемещение к цели. Обе части сети не соединены.
Обошелся без запоминающих обычных нейронов, в задаче думать не надо, она решается на уровне возникающих условных рефлексов, поэтому здесь я их не использую. Центральную роль в решении задачи сыграла топология сети, то как размещены нейроны и датчики. Очень важно то, как вы подготовите нейросеть, фактически зададите задачу для решения. Далее амеба делает попытки двигаться, устанавливаются связи между одновременно активными нейронами, в финале эмоции боли и приятного направляют ее к цели.
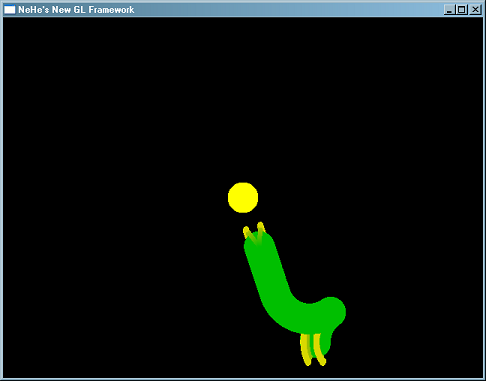
Рис 2. Путь амебы.
Она разворачивается и ползет к цели.
Рис 3. Скриншот.
А так это выглядит с отключенной трассировкой.
1. Современные сети не обладают одновременной стабильностью и пластичностью, то есть процесс корректной работы сети не совместим с её обучением. Современные сети, обучаясь новому, успешно забывают старое, поэтому для работы используется неизменяемый слепок нейросети после обучения, которым никак управлять не надо.
2. Специфика наших требований к рабочей сети, даже если она обладает одновременной стабильностью и пластичностью, не позволяет ей допускать ошибки, а ведь избежать этого в обучении невозможно. Зачем спрашивается нам система, которая не только может физически поломаться, но и обладающая чем то, вроде «человеческого фактора»?
Я поставил себе цель создать модель на нейронной сети для управления амебой в плоском пространстве, стремящейся развернутся в сторону цели и добраться до неё. Задача очень тривиальная, но вся проблема была в том, что амеба должна научиться этому сама и без моей помощи. Ведь создавая автоматические системы, мы до сих пор заранее задаем все решения для всего набора условий той конкретной задачи, которую будут выполнять автоматы, а так же не даем возможности системам обучаться в процессе их функционирования. Красивыми словами это можно описать так: «Решение задачи не закладывается в систему управления заранее, мы перекладываем на систему не только выполнение задачи, но и нахождение решения этой задачи».
Мы настолько привыкли заранее закладывать решения в автоматические системы, что сложно представить абстрактную модель самообучающейся и самостоятельно находящей решения автоматической системы. Не надо наступать на те же грабли, думая, что в финале нам надо просто сообщить в какой либо форме как решать задачу. Автомат когда-нибудь и сможет понять получаемую от нас информацию и использовать чужой опыт, но в действительности мы должны будем начинать работать с системой, которая не обладает еще никакими навыками кроме возможности обучаться, воспринимать окружающую среду и воздействовать на неё. Получается из обычной автоматической системы нужно сразу выкинуть заранее вложенное решение, и положить в нее вычислительную подсистему, в которой реализовано что-то вроде наших мозгов. Поэтому я и использую нейронную сеть, как ближайшее подобие мозга.
Но после первой встречи с таким автоматом вы поймёте, что он полный аутист, пофигист и окружающий мир ему глубоко безразличен. А нам все же нужно, что бы он смог тоже, что и до того как мы выкинули наше вложенное решение. Я упустил одну важную вещь, забыл поставить перед системой условие решения нашей задачи. Системе нужно дать понять, когда ее действия удовлетворяют условиям решения нашей задачи и наоборот. Центральным словом здесь является слово «понять», причем именно нейросеть должна «понять», что мы от неё хотим. Ничего особенного здесь выдумывать не нужно, всего лишь примитивно повторить уже существующий, и да, заранее заложенный в нас «язык эмоций». Я сейчас особо не буду распространяться про единственный общий «язык эмоций». Скажу только, что все мы не только чувствуем эмоции, но и одинаково реагируем на них, показывая языком тела, что мы чувствуем. То, что мы будем использовать – метод кнута и пряника, ведь он работает даже с простейшими животными, подразумевает наличие эмоциональных чувств приятного и неприятного (боли). Мы же наделены большим набором эмоций, чем эти чувства, но такого набора вполне достаточно для модели амебы и нашей задачи. Добавлением датчиков поворота к цели, движения к цели и наоборот, а также добавляя эмоциональную окраску к ним, мы объясняем задачу и мотивируем нейросеть решить нашу задачу.
Это ключевой момент для нейронной сети, так как мы вводим систему мотивации и общения (по крайней мере мы сможем «обращаться» к амебе). Поведение нашей амебы у внешнего наблюдателя будет вызывать стойкую ассоциацию с мотивированным поведением и с присутствием эмоционального восприятия у неё.
Далее собственно описание устройства нейронов, датчиков и нейросети в целом, коротко, но довольно сложно из-за отсутствия объяснений, почему так. К прочтению не обязательно. Можно прочитать выводы.
Устройство сети
Основные свойства модели нейронов, которые я использую.
- Выдача результата нейроном задерживается на один такт работы сети. Основное преимущество — это возможность соединять нейроны вообще как угодно, потому что это не приносит ошибок в логику сети, сначала вычисляются все значения всех нейронов, а потом обновляются их выходы.
- Я использую только два значения на выходе нейронов «0» и «1».
- Выход нейрона может образовать «негативный» и «позитивный» синапс, так же этот синапс может менять свое состояние с «позитивного» на «негативный» и наоборот.
- Функция активации вычисляется как разница активных позитивных и негативных входов. Если разница положительная, результат «1», если нет, то «0».
- Синапс стремится стать «позитивным» если результат функции активации равен «1», и «негативным»только если сейчас результат «0», а предыдущий результат был «1».
- Нейроны ограничены зоной установления связей, так что начинает играть роль топология сети.
Нейроны в моей сети делятся на несколько типов
- Датчики. Обычные датчики представленные в сети только выходами.
- Эффекторы. Моторные нейроны, выходы управляют мускулами, а в сети представлены только входами.
- Эмоциональные датчики. Тоже что и обычные датчики, но устанавливают неизменяемые связи, только позитивного или негативного характера в зависимости от типа датчика и не могут поменять состояние этих связей.
- Обычные. Я описывал их в первой моей статье. В задаче думать не надо, она решается на уровне как бы «условных рефлексов», поэтому здесь я их не использую.
Сеть представляет собой двухмерное пространство, в котором задается положение нейронов координатами, из-за ограниченного радиуса ответственности связи устанавливаются только между близкорасположенными нейронами. В самом начале между нейронами связей нет вообще. Эффекторы произвольно активируются пока не установятся первые связи. Связи устанавливаются тем быстрее, чем ближе и чаще нейроны одновременно активны (правило Хебба). В финале топология выглядит так.
Рис 1. Топология участка нейросети отвечающего за повороты
Кругами обозначены зоны ответственности нейронов. Такую же топологию имеет и часть нейросети отвечающая за перемещение к цели. Обе части сети не соединены.
Выводы
Обошелся без запоминающих обычных нейронов, в задаче думать не надо, она решается на уровне возникающих условных рефлексов, поэтому здесь я их не использую. Центральную роль в решении задачи сыграла топология сети, то как размещены нейроны и датчики. Очень важно то, как вы подготовите нейросеть, фактически зададите задачу для решения. Далее амеба делает попытки двигаться, устанавливаются связи между одновременно активными нейронами, в финале эмоции боли и приятного направляют ее к цели.
Рис 2. Путь амебы.
Она разворачивается и ползет к цели.
Рис 3. Скриншот.
А так это выглядит с отключенной трассировкой.
