В пилотной части я рассказал о задаче как можно подробнее. Рассказ получился долгим и беспредметным — в нем не было ни одной строчки кода. Но без понимания задачи очень сложно заниматься оптимизацией. Конечно, некоторые техники можно применять, имея на руках только код. Например, кешировать вычисления, сокращать ветвления. Но мне кажется, что некоторые вещи без понимания задачи просто никогда не сделать. Это и отличает человека от оптимизирующего компилятора. Поэтому ручная оптимизация все еще играет огромную роль: у компилятора есть только код, а у человека есть понимание задачи. Компилятор не может принять решение, что значение "4" достаточно случайно, а человек может.

Напомню, что речь пойдет об оптимизации операции ресайза изображения методом сверток в реально существующей библиотеке Pillow. Я буду рассказывать о тех изменениях, что я делал несколько лет назад. Но это не будет повторение слово-в-слово: оптимизации будут описаны в порядке, удобном для повествования. Для этих статей я сделал в репозитории отдельную ветку от версии 2.6.2 — именно с этого момента и будет идти повествование.
Тестирование
Если вы хотите не просто читать, но и экспериментировать самостоятельно, вам пригодится пакет с тестами pillow-perf.
# Установка нужных для компиляции и тестов пакетов
$ sudo apt-get install -y build-essential ccache \
python-dev libjpeg-dev
$ git clone -b opt/scalar https://github.com/uploadcare/pillow-simd.git
$ git clone --depth 10 https://github.com/python-pillow/pillow-perf.git
$ cd ./pillow-simd/
# Коммит, с которого все начинается
$ git checkout bf1df9a
# Собираем и устанавливаем Pillow
$ CC="ccache cc" python ./setup.py develop
# Наконец-то запускаем тест
$ ../pillow-perf/testsuite/run.py scale -n 3Т. к. Pillow состоит из множества модулей и не умеет компилироваться инкрементально, для существенного ускорения повторных сборок используется утилита ccache. С помощью pillow-perf можно тестировать много операций, но нас интересует scale. -n 3 задает кол-во запусков операции. Пока код медленный, можно взять число поменьше, чтобы не уснуть. На старте производительность такая:
Scale 2560×1600 RGB image
to 320x200 bil 0.08927 s 45.88 Mpx/s
to 320x200 bic 0.13073 s 31.33 Mpx/s
to 320x200 lzs 0.16436 s 24.92 Mpx/s
to 2048x1280 bil 0.40833 s 10.03 Mpx/s
to 2048x1280 bic 0.45507 s 9.00 Mpx/s
to 2048x1280 lzs 0.52855 s 7.75 Mpx/s
to 5478x3424 bil 1.49024 s 2.75 Mpx/s
to 5478x3424 bic 1.84503 s 2.22 Mpx/s
to 5478x3424 lzs 2.04901 s 2.00 Mpx/sРезультат для коммита bf1df9a.
Эти результаты немного отличаются от полученных в официальном бенчмарке для версии 2.6. Тому есть несколько причин:
- В официальном бенчмарке используется 64-битная Ubuntu 16.04 с GCC 5.3. Я же буду использоваться 32-битной Ubuntu 14.04 с GCC 4.8, на которой делал все эти оптимизации впервые. В конце статьи станет понятно, почему.
- В статьях я начинаю рассказ с коммита, в котором исправлен баг, который не относится к оптимизации, но влияет на производительность.
Структура кода
Большая часть кода, который нас интересует, находится в файле Antialias.c, в функции ImagingStretch. Код этой функции можно разделить на три части:
// Пролог
if (imIn->xsize == imOut->xsize) {
// Вертикальный ресайз
} else {
// Горизонтальный ресайз
}Как я говорил ранее, ресайз изображения свертками можно сделать в два прохода: на первом меняется только ширина изображения, на втором — высота, или наоборот. Функция ImagingStretch за один вызов как раз может сделать либо то, либо другое. Тут можно увидеть, что она действительно вызывается дважды во время каждого ресайза. В функции выполняется общий пролог, а дальше, в зависимости от параметров, та или иная операция. Довольно необычный подход к избавлению от повторяющегося кода, коим в данном случае является пролог.
Внутри оба прохода выглядят примерно одинаково, с поправкой на меняющееся направление обработки. Для краткости приведу только один:
for (yy = 0; yy < imOut->ysize; yy++) {
// Подсчёт коэффициентов
if (imIn->image8) {
// Цикл для одного канала 8 бит
} else {
switch(imIn->type) {
case IMAGING_TYPE_UINT8:
// Цикл для нескольких каналов по 8 бит
case IMAGING_TYPE_INT32:
// Цикл для одного канала 32 бита
case IMAGING_TYPE_FLOAT32:
// Цикл для одного канала float
}
}Тут происходит ветвление на несколько форматов представления пикселей, поддерживаемых Pillow: одноканальные 8 бит (оттенки серого), многоканальные 8 бит (RGB, RGBA, LA, CMYK, некоторые другие), одноканальные 32 бита и float. Нас будет интересовать тело цикла для нескольких каналов по 8 бит, так как это наиболее часто встречающийся формат изображений.
Оптимизация 1: эффективно используем кэш
Хоть я и сказал выше, что два прохода похожи, между ними есть очевидное различие. Посмотрите на вертикальный проход:
for (yy = 0; yy < imOut->ysize; yy++) {
// Подсчёт коэффициентов
for (xx = 0; xx < imOut->xsize*4; xx++) {
// Свертка столбца пикселей
// Сохранение пикселя в imOut->image8[yy][xx]
}
}На горизонтальный проход:
for (xx = 0; xx < imOut->xsize; xx++) {
// Подсчёт коэффициентов
for (yy = 0; yy < imOut->ysize; yy++) {
// Свертка строки пикселей
// Сохранение пикселя в imOut->image8[yy][xx]
}
}У вертикального прохода во внутреннем цикле итерируются столбцы конечного изображения, а у горизонтального — строки. Горизонтальный проход представляет серьезную проблему для кеша процессора. На каждом шаге внутреннего цикла происходит обращение на одну строку ниже, а значит запрашивается значение из памяти, лежащее далеко от значения, нужного на предыдущем шаге. Это плохо при небольшом размере свертки. Дело в том, что на современных процессорах линейка кеша, которую процессор может запросить из оперативной памяти, всегда равна 64 байтам. Это значит, что если в свертке участвует меньше 16 пикселей, то часть данных гоняется впустую из оперативной памяти в кеш. А теперь представьте, что циклы поменялись местами и следующий пиксель сворачивается не строкой ниже, а следующий в этой же строке. Тогда большая часть нужных пикселей уже была бы в кеше.
Второй негативный фактор такой организации кода проявляется при длинной строке для свертки (т. е. при сильном уменьшении). Дело в том, что для соседних сверток исходные пиксели довольно значительно пересекаются, и было бы хорошо, если бы эти данные оставались в кеше. Но когда мы движемся сверху вниз, данные для старых сверток постепенно начинают вытесняться из кэша данными для новых. В результате, когда проходит полный внутренний цикл и начинается следующий шаг внешнего, в кеше уже не оказывается верхних строк, они все вытеснены нижними, их нужно снова запрашивать из памяти. А когда дело доходит до нижних, в кеше уже все вытеснено верхними. Получается круговорот, в результате которого в кеше никогда нет нужных данных.
Почему же обход сделан так? В псевдокоде выше видно, что второй строчкой в обоих случаях идет подсчет коэффициентов для свертки. Для вертикального прохода коэффициенты зависят только от строки конечного изображения (от значения yy), а для горизонтального от текущего столбца (от значения xx). Т. е. в горизонтальном проходе нельзя просто поменять местами два цикла — расчет коэффициентов должен быть внутри цикла по xx. Если же начать считать коэффициенты внутри внутреннего цикла, это убьёт всю производительность. Особенно когда для расчета коэффициентов применяется фильтр Ланцоша, в котором есть тригонометрические функции.
Вычислять коэффициенты на каждом шаге нельзя, но тем не менее они одинаковые для всех пикселей одного столбца. Значит можно просчитать все коэффициенты заранее для всех столбцов, а во внутреннем цикле брать уже посчитанное. Давайте так и сделаем.
В коде есть выделение памяти для коэффициентов:
k = malloc(kmax * sizeof(float));Теперь нам понадобится массив таких массивов. Но можно упростить — выделить плоский кусок памяти и эмулировать двумерность адресацией.
kk = malloc(imOut->xsize * kmax * sizeof(float));Еще понадобится где-то хранить xmin и xmax, которые тоже зависят от xx. Под них тоже сделаем массив, чтобы не пересчитывать.
xbounds = malloc(imOut->xsize * 2 * sizeof(float));Также внутри цикла используется некое значение ww, которое нужно для нормализации значения свертки. ww = 1 / ∑k[x]. Его можно вообще не хранить, и нормализовать сами коэффициенты, а не результат свёртки. Т. е. после того, как мы посчитали коэффициенты, нужно пройтись по ним еще раз и поделить их на их же сумму, в результате чего сумма всех коэффициентов станет равна 1:
k = &kk[xx * kmax];
for (x = (int) xmin; x < (int) xmax; x++) {
float w = filterp->filter((x - center + 0.5) * ss);
k[x - (int) xmin] = w;
ww = ww + w;
}
for (x = (int) xmin; x < (int) xmax; x++) {
k[x - (int) xmin] /= ww;
}Вот теперь можно наконец-то развернуть обход пикселей на 90°:
// Подсчёт всех коэффициентов
for (yy = 0; yy < imOut->ysize; yy++) {
for (xx = 0; xx < imOut->xsize; xx++) {
k = &kk[xx * kmax];
xmin = xbounds[xx * 2 + 0];
xmax = xbounds[xx * 2 + 1];
// Свертка строки пикселей
// Сохранение пикселя в imOut->image8[yy][xx]
}
}Scale 2560×1600 RGB image
to 320x200 bil 0.04759 s 86.08 Mpx/s 87.6 %
to 320x200 bic 0.08970 s 45.66 Mpx/s 45.7 %
to 320x200 lzs 0.11604 s 35.30 Mpx/s 41.6 %
to 2048x1280 bil 0.24501 s 16.72 Mpx/s 66.7 %
to 2048x1280 bic 0.30398 s 13.47 Mpx/s 49.7 %
to 2048x1280 lzs 0.37300 s 10.98 Mpx/s 41.7 %
to 5478x3424 bil 1.06362 s 3.85 Mpx/s 40.1 %
to 5478x3424 bic 1.32330 s 3.10 Mpx/s 39.4 %
to 5478x3424 lzs 1.56232 s 2.62 Mpx/s 31.2 %Результат для коммита d35755c.
В четвертом столбце показано ускорение относительно предыдущего варианта, а под таблицей ссылка на коммит, где хорошо видно сделанные изменения.
Оптимизация 2: Ограничение выходных значений
В коде мы в нескольких местах видим такую конструкцию:
if (ss < 0.5)
imOut->image[yy][xx*4+b] = (UINT8) 0;
else if (ss >= 255.0)
imOut->image[yy][xx*4+b] = (UINT8) 255;
else
imOut->image[yy][xx*4+b] = (UINT8) ss;Это ограничение значения пикселя в рамках [0, 255], если результат вычислений выходит за пределы 8 бит. Действительно, сумма всех положительных коэффициентов свертки может быть больше единицы, а сумма всех отрицательных может быть меньше нуля. А значит при определенных исходном изображении можем получить переполнение. Это переполнение является результатом компенсации резких перепадов яркости и не является ошибкой.
Взглянем на код. В нем одна входная переменная ss и ровно одна выходная imOut->image[yy], значение которой присваивается в нескольких местах. Плохо тут то, что сравниваются числа с плавающей точкой. Было бы быстрее преобразовать все в целые и потом уже сравнивать, раз уж все равно в конце нам нужен целый результат. Итого получается вот такая функция:
static inline UINT8
clip8(float in) {
int out = (int) in;
if (out >= 255)
return 255;
if (out <= 0)
return 0;
return (UINT8) out;
}Использование:
imOut->image[yy][xx*4+b] = clip8(ss);Это тоже дает прирост производительности, хоть и небольшой.
Scale 2560×1600 RGB image
to 320x200 bil 0.04644 s 88.20 Mpx/s 2.5 %
to 320x200 bic 0.08157 s 50.21 Mpx/s 10.0 %
to 320x200 lzs 0.11131 s 36.80 Mpx/s 4.2 %
to 2048x1280 bil 0.22348 s 18.33 Mpx/s 9.6 %
to 2048x1280 bic 0.28599 s 14.32 Mpx/s 6.3 %
to 2048x1280 lzs 0.35462 s 11.55 Mpx/s 5.2 %
to 5478x3424 bil 0.94587 s 4.33 Mpx/s 12.4 %
to 5478x3424 bic 1.18599 s 3.45 Mpx/s 11.6 %
to 5478x3424 lzs 1.45088 s 2.82 Mpx/s 7.7 %Результат для коммита 54d3b9d.
Как можно заметить, эта оптимизация дала больший эффект для фильтров с меньшим окном и с большим выходным разрешением (единственное исключение это 320x200 Bilinear, но я не берусь сказать, почему). И действительно, чем меньше окно фильтра и больше конечное разрешение, тем больший вклад в производительность делает обрезание значений, которое мы и оптимизировали.
Оптимизация 3: Разворот циклов c постоянным количеством итераций
Если еще раз присмотреться к горизонтальному шагу, там можно насчитать целых 4 вложенных цикла:
for (yy = 0; yy < imOut->ysize; yy++) {
// ...
for (xx = 0; xx < imOut->xsize; xx++) {
// ...
for (b = 0; b < imIn->bands; b++) {
// ...
for (x = (int) xmin; x < (int) xmax; x++) {
ss = ss + (UINT8) imIn->image[yy][x*4+b] * k[x - (int) xmin];
}
}
}
}Итерируется каждый ряд и каждый столбец выходного изображения (т. е. каждый пиксель), а внутри итерируется каждый пиксель исходного изображения, который нужно свернуть. А вот что такое b? b — это итерирование по каналам изображения. Очевидно, что количество каналов на протяжении работы функции не меняется и никогда не превышает 4 (ввиду способа хранения изображения в Pillow). Следовательно, может быть всего 4 возможных случая. А с учетом того, что одноканальные 8-битные изображения хранятся иным способом, то случаев вовсе три. Соответственно можно сделать три отдельных внутренних цикла: для двух, трех и четырех каналов. И сделать ветвление на нужное количество каналов. Я покажу только код трехканального случая, чтобы не занимать слишком много места.
for (xx = 0; xx < imOut->xsize; xx++) {
if (imIn->bands == 4) {
// Тело для 4 каналов
} else if (imIn->bands == 3) {
ss0 = 0.0;
ss1 = 0.0;
ss2 = 0.0;
for (x = (int) xmin; x < (int) xmax; x++) {
ss0 = ss0 + (UINT8) imIn->image[yy][x*4+0] * k[x - (int) xmin];
ss1 = ss1 + (UINT8) imIn->image[yy][x*4+1] * k[x - (int) xmin];
ss2 = ss2 + (UINT8) imIn->image[yy][x*4+2] * k[x - (int) xmin];
}
ss0 = ss0 * ww + 0.5;
ss1 = ss1 * ww + 0.5;
ss2 = ss2 * ww + 0.5;
imOut->image[yy][xx*4+0] = clip8(ss0);
imOut->image[yy][xx*4+1] = clip8(ss1);
imOut->image[yy][xx*4+2] = clip8(ss2);
} else {
// Тело для двух и одного канала
}
}Можно на этом не останавливаться и переместить ветвление еще на один уровень выше, до цикла по xx:
if (imIn->bands == 4) {
for (xx = 0; xx < imOut->xsize; xx++) {
// Тело для 4 каналов
}
} else if (imIn->bands == 3) {
for (xx = 0; xx < imOut->xsize; xx++) {
// Тело для 3 каналов
}
} else {
for (xx = 0; xx < imOut->xsize; xx++) {
// Тело для двух и одного канала
}
}Scale 2560×1600 RGB image
to 320x200 bil 0.03885 s 105.43 Mpx/s 19.5 %
to 320x200 bic 0.05923 s 69.15 Mpx/s 37.7 %
to 320x200 lzs 0.09176 s 44.64 Mpx/s 21.3 %
to 2048x1280 bil 0.19679 s 20.81 Mpx/s 13.6 %
to 2048x1280 bic 0.24257 s 16.89 Mpx/s 17.9 %
to 2048x1280 lzs 0.30501 s 13.43 Mpx/s 16.3 %
to 5478x3424 bil 0.88552 s 4.63 Mpx/s 6.8 %
to 5478x3424 bic 1.08753 s 3.77 Mpx/s 9.1 %
to 5478x3424 lzs 1.32788 s 3.08 Mpx/s 9.3 %Результат для коммита 95a9e30.
Что-то похожее можно сделать и для вертикального прохода. Там сейчас такой код:
for (xx = 0; xx < imOut->xsize*4; xx++) {
/* FIXME: skip over unused pixels */
ss = 0.0;
for (y = (int) ymin; y < (int) ymax; y++)
ss = ss + (UINT8) imIn->image[y][xx] * k[y-(int) ymin];
ss = ss * ww + 0.5;
imOut->image[yy][xx] = clip8(ss);
}Тут нет отдельного итерирования по каналам, вместо этого xx итерируется по ширине, умноженной на 4. Т. е. xx проходится по каждому каналу вне зависимости от их количества в изображении. FIXME в комментарии как раз говорит о том, что это нужно исправить. Исправляется точно так же — ветвлением кода для разного количества каналов в исходном изображении. Приводить код здесь не буду, ссылка на коммит ниже.
Scale 2560×1600 RGB image
to 320x200 bil 0.03336 s 122.80 Mpx/s 16.5 %
to 320x200 bic 0.05439 s 75.31 Mpx/s 8.9 %
to 320x200 lzs 0.08317 s 49.25 Mpx/s 10.3 %
to 2048x1280 bil 0.16310 s 25.11 Mpx/s 20.7 %
to 2048x1280 bic 0.19669 s 20.82 Mpx/s 23.3 %
to 2048x1280 lzs 0.24614 s 16.64 Mpx/s 23.9 %
to 5478x3424 bil 0.65588 s 6.25 Mpx/s 35.0 %
to 5478x3424 bic 0.80276 s 5.10 Mpx/s 35.5 %
to 5478x3424 lzs 0.96007 s 4.27 Mpx/s 38.3 %Результат для коммита f227c35.
Как можно заметить, горизонтальный проход дал больше производительности для уменьшения картинки, тогда как вертикальный — для увеличения.
Оптимизация 4: Целочисленные счетчики
for (y = (int) ymin; y < (int) ymax; y++) {
ss0 = ss0 + (UINT8) imIn->image[y][xx*4+0] * k[y-(int) ymin];
ss1 = ss1 + (UINT8) imIn->image[y][xx*4+1] * k[y-(int) ymin];
ss2 = ss2 + (UINT8) imIn->image[y][xx*4+2] * k[y-(int) ymin];
}Если посмотреть в самый внутренний цикл, можно увидеть, что переменные ymin и ymax объявлены как float, но приводятся к целому на каждом шаге. Более того, за пределами цикла для присвоения им значений используются функции floor и ceil. Т. е. по факту в переменных всегда хранятся целые числа, но объявлены они почему-то как float. То же самое касается xmin и xmax. Меняем и замеряем.
Scale 2560×1600 RGB image
to 320x200 bil 0.03009 s 136.10 Mpx/s 10.9 %
to 320x200 bic 0.05187 s 78.97 Mpx/s 4.9 %
to 320x200 lzs 0.08113 s 50.49 Mpx/s 2.5 %
to 2048x1280 bil 0.14017 s 29.22 Mpx/s 16.4 %
to 2048x1280 bic 0.17750 s 23.08 Mpx/s 10.8 %
to 2048x1280 lzs 0.22597 s 18.13 Mpx/s 8.9 %
to 5478x3424 bil 0.58726 s 6.97 Mpx/s 11.7 %
to 5478x3424 bic 0.74648 s 5.49 Mpx/s 7.5 %
to 5478x3424 lzs 0.90867 s 4.51 Mpx/s 5.7 %Результат для коммита 57e8925.
Финал первого акта и босс
Признаюсь, я был очень рад полученным результатам. Удалось разогнать код в среднем в 2,5 раза. Причем для получения этого ускорения пользователю библиотеки не нужно было ставить дополнительное оборудование, ресайз как и раньше идет на одном ядре того же процессора, что и до этого. Нужно было только обновить версию Pillow до версии 2.7.
Но до релиза 2.7 оставалось еще какое-то время, а мне не терпелось проверить новый код на том сервере, на котором он должен был работать. Я перенес код, скомпилировал и сначала подумал, что что-то напутал:
Scale 2560×1600 RGB image
320x200 bil 0.08056 s 50.84 Mpx/s
320x200 bic 0.16054 s 25.51 Mpx/s
320x200 lzs 0.24116 s 16.98 Mpx/s
2048x1280 bil 0.18300 s 22.38 Mpx/s
2048x1280 bic 0.31103 s 13.17 Mpx/s
2048x1280 lzs 0.43999 s 9.31 Mpx/s
5478x3424 bil 0.75046 s 5.46 Mpx/s
5478x3424 bic 1.22468 s 3.34 Mpx/s
5478x3424 lzs 1.70451 s 2.40 Mpx/sРезультат для коммита 57e8925. Получен на другой машине и не участвует в сравнении.
Лолчто? Результаты почти такие же, как до оптимизации. Я 10 раз все перепроверил, поставил принтов, чтобы убедиться, что работает нужный код. Это не был какой-то сайд-эффект от Pillow или окружения, разница воспроизводилась даже на минимальном примере в 30 строчек. Я задал вопрос на Stack Overflow, и в конце концов удалось найти явную закономерность: код выполнялся медленно, если был скомпилирован с GCC под платформу 64 бита. И именно в этом было различие локальной Убунты и на сервере: локально была 32-битная.
Ну слава Муру, я не сошел с ума, это реальный баг в компиляторе. Причем баг был исправлен в GCC 4.9, но GCC 4.8 входил в актуальную на тот момент Ubuntu 14.04 LTS, т. е. скорее всего был установлен у большинства пользователей библиотеки. Игнорировать это было нельзя: что толку от оптимизации, если она не работает у большинства, в том числе и на продакшене, для которого она делалась. Я обновил вопрос на SO и кинул клич в твитере. На него пришел Вячеслав Егоров, один из разработчиков движка V8 и гений оптимизации, который помог докопаться до сути и нашел решение.
Чтобы понять суть проблемы, нужно углубиться в историю процессоров и их текущую архитектуру. Когда-то давно процессоры x86 не умели работать с числами с плавающей точкой, для них был придуман сопроцессор с набором команд x87. Он исполнял инструкции из того же потока, что и центральный процессор, но устанавливался на материнскую плату как отдельное устройство. Довольно быстро сопроцессор стали встраивать в центральный, и физически это стало одним устройством. Долго ли коротко ли, в третьем Пентиуме появился набор инструкций SSE (Streaming SIMD Extensions). Кстати, про SIMD инструкции будет вторая часть цикла статей. Несмотря на название, SSE содержал не только SIMD-команды для работы с числами с плавающей точкой, но и их эквиваленты для скалярных вычислений. Т. е. SSE содержал набор инструкций, дублирующий набор x87, но закодированный иначе и с немного отличающимся поведением.
Тем не менее, компиляторы не спешили генерировать SSE-код для вычислений с плавающей точкой, а продолжали использовать устаревший набор x87. Ведь наличие SSE в процессоре никто не гарантировал, в отличие от x87, который был встроен с незапамятных времен. Все изменилось с приходом 64-битного режима работы процессора. В 64-битом режиме стало обязательным наличие набора инструкций SSE2. Т. е. если вы пишете 64-битную программу для x86, вам доступны как минимум инструкции SSE2. Чем и пользуются компиляторы, генерируя для вычислений с плавающей точкой в 64-битном режиме SSE-инструкции. Напомню, что это никак не связано с векторизацией, речь об обычных скалярных вычислениях.
Именно это и происходит в нашем случае: используются разные наборы инструкций для 32-битного и 64-битного режима. Но пока это не объясняет, почему более современный SSE-код оказывается в разы медленнее устаревшего набора x87. Для объяснения этого феномена нужно разобраться, как именно процессор выполняет инструкции.
Когда-то процессоры действительно «выполняли» инструкции. Они брали инструкцию, декодировали, выполняли её полностью, клали результат куда сказано. Процессоры были довольно тупы. Современные процессоры намного умнее и сложнее, они состоят из десятков разных подсистем. Даже на одном ядре, без всякой параллельной обработки, процессор в один момент времени, в один такт, выполняет несколько инструкций. Просто выполнение происходит на разных стадиях: какая-то инструкция еще только декодируется, какая-то запрашивает что-то из кеша, какая-то передана в арифметический блок. Каждая подсистема процессора занимается своей частью. Это и называется конвейер.
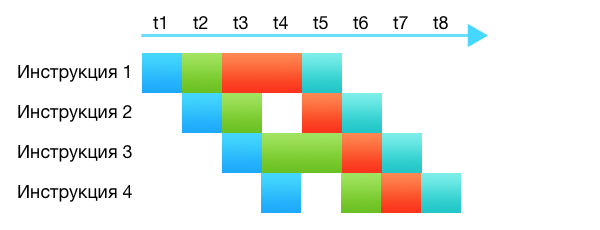
На картинке разные подсистемы обозначены разным цветом. Видно, что хотя команды требует от 4 до 5 тактов на выполнение, благодаря конвейеру каждый такт выбирается одна новая команда и одна завершает свое выполнение.
Конвейер работает тем эффективнее, чем равномернее он заполнен и чем меньше подсистем простаивает. В процессоре даже есть подсистемы, которые планируют оптимальное заполнение конвейера: меняют местами инструкции, дробят одну инструкцию на несколько, объединяют несколько в одну.
Одна из вещей, которая способна заставить конвейер работать не оптимально — зависимость по данным. Это когда для выполнения какой-то инструкции необходим результат выполнения другой инструкции и многие подсистемы простаивают, ожидая когда будет выполнена предыдущая инструкция.
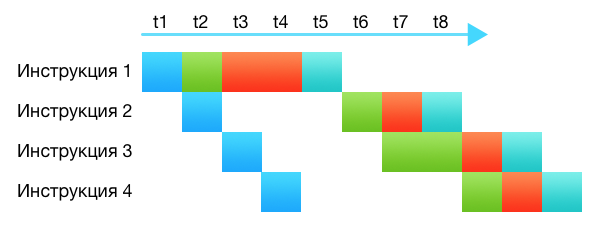
На рисунке видно, что инструкция 2 ждет завершения выполнения инструкции 1. В это время большинство подсистем простаивает. Выполнение всей цепочки команд замедлилось на три такта.
А теперь, вооружившись всеми этими знаниями, давайте посмотрим на псевдокод инструкции, конвертирующей целое число в число с плавающей точкой:
Instruction: cvtsi2ss xmm, r32
dst[31:0] := Convert_Int32_To_FP32(b[31:0])
dst[127:32] := a[127:32]В младшие 32 бита записывается результат конвертации. Дальше хоть и написано, что в dst переносятся биты из какого-то регистра a, по сигнатуре самой инструкции видно, что она работает только с одним xmm регистром, а значит dst и a — это один и тот же регистр, и старшие 96 бит не переносятся, а остаются нетронутыми. Вот тут и происходит зависимость по данным. Инструкция сделана таким образом, что гарантирует сохранность старших битов, а значит для её выполнения нужно дождаться результата от всех остальных операций, работающих с этим регистром. Вот только в реальности мы не пользуемся старшими битами в этих регистрах, все вычисления происходят только в младшем 32-битном float. Нам все равно, какие значения будут в старших битах, на результат работы это не повлияет. Такая зависимость по данным называется ложной.
К счастью, такую зависимость вполне можно разорвать. Компилятор должен непосредственно до инструкции конвертации cvtsi2ss вставить очистку регистра, то есть инструкцию xorps. У меня язык не поворачивается назвать этот фикс интуитивным и даже логичным. Скорее всего, это и не фикс вовсе, а хак, сделанный на уровне декодера команд, который заменяет xorps + cvtsi2ss на какую-то внутреннюю инструкцию со следующим псевдокодом:
dst[31:0] := Convert_Int32_To_FP32(b[31:0])
dst[127:32] := 0К сожалению, фикс для GCC 4.8 достаточно уродливый, он состоит из ассемблерной вставки и кода препроцессора, который проверяет уместность фикса. Приводить его не буду, ссылки на коммит, как обычно, под результатами тестов. Фикс полностью излечивает 64-битный код.
Scale 2560×1600 RGB image
320x200 bil 0.02447 s 167.42 Mpx/s
320x200 bic 0.04624 s 88.58 Mpx/s
320x200 lzs 0.07142 s 57.35 Mpx/s
2048x1280 bil 0.08656 s 47.32 Mpx/s
2048x1280 bic 0.12079 s 33.91 Mpx/s
2048x1280 lzs 0.16484 s 24.85 Mpx/s
5478x3424 bil 0.38566 s 10.62 Mpx/s
5478x3424 bic 0.52408 s 7.82 Mpx/s
5478x3424 lzs 0.65726 s 6.23 Mpx/s Результат для коммита 81fc88e. Получен на другой машине и не участвует в сравнении.
Ситуация, описанная тут, совсем не редка. Код, который переводит целые числа в числа с плавающей точкой, а потом производит достаточно небольшие вычисления, встречается почти в каждой программе. Тот же ImageMagick тоже подвержен этой проблеме: 64-битные версии, скомпилированные GCC 4.9 примерно на 40% быстрее скомпилированных более ранними версиями компилятора. Как по мне, это довольно серьезный прокол в системе команд SSE.
Дальше: Часть 2, SIMD
