Comments 58
На последнем этапе приходит бизнес и резонно говорит, что раз есть готовые решения бизнес-задач, то давайте делать новые продукты без разработки. Будем соединять готовые независимые блоки в новые бизнес-процессы через оркестратор.
Этап 4 — ненаучная фантастика.
Пример, который работает и с которым я работал https://lm-tech.ru/platformeco/
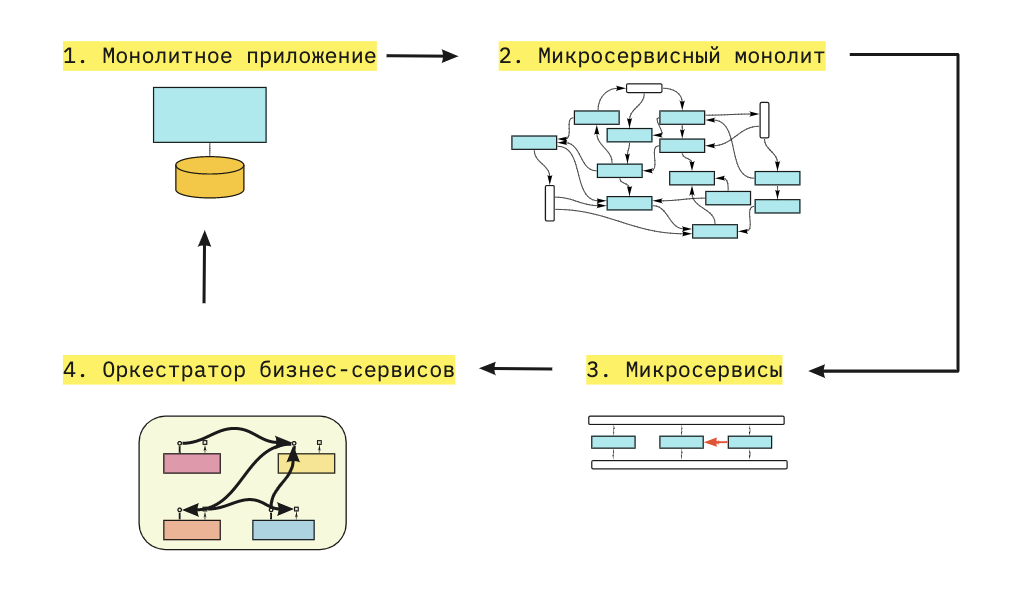
Архитектуру сложно понять и, чем больше сервисов вы добавляете, тем запутанней всё становится. В целом, добавление новых сервисов нелинейно повышает сложность архитектуры.
Добавили gateway, service discovery и чего? Архитектуру все также сложно понять. И от того, что сервисы вызывают друг друга через gateway с использованием service discovery линейности не прибавилось.
Что если на третьем микросервисе запрос завис? Что если там была ошибка? Что если на втором шаге должно было создаться сообщение в очередь, но оно не появилось?
И как нам тут поможет то, что мы делали в п.2.3? Предложенные паттерны (типа Circuit Breaker) могут помочь, но это большая и непростая работа по их внедрению и об этом ни слова.
По поводу внедрения все этого. Это очень сложно и довольно дорого. Переписывание монолита на микросервисы обходится примерно как стоимость самого монолита. При этом есть риск сделать еще хуже, потому что компетенции нужны довольно высокие. Компании идут на этот шаг, если проблемы монолита становятся критичны для их бизнеса.
При работе через API Gateway видно кто и как кого вызывает. Управляемость и наглядность повышаются в сравнении с беспорядочными запросами между микросервисами напрямую.
Порядка в запросах же не прибавилось. Если сервису А нужно вызвать сервис B, получить от него ответ, и в зависимости от ответа вызвать или сервис C или сервис D и опять что-то сделать, то вот вся эта цепочка останется и никуда не денется с гейтвеем или без. Чем тут gateway поможет?
Еще, нужно понимать, что делая gateway, вы создаете бутылочное горлышко по сути и вам его придется масштабировать. И тут уже без инструментов трассировки запросов не обойтись. А если применять инструменты трассировки запросов, то в принципе все равно что отслеживать запросы с гейтвеем что без него.
Да и визуализация межсервисных вызовов- есть широкий ассортимент инструментов трассировки.
Не обязательно вводить доп.нагрузку и точку отказа для этого.
В остальном — судя потому куда ветер дует сейчас — в service mesh — это в некотором смысле происходит «под капотом».
Четвертый этап, который тут описан — это давно известный SOA, который провалился чуть менее, чем везде.
1) Бизнес схемы. Сама механика использования бизнес схем — имхо, неудачная. Это выглядит красиво только на простых задачах, но превращается в ад, когда количество блоков в схеме приближается к 100, добавляются условные операторы, подобие циклов. Ни на один монитор это не влезает, поэтому начинают придумывать «группы блоков», которые можно свернуть/развернуть — но даже с ними быстро понять «код» — непросто. В классическом программировании уже давно этот вопрос решен: разделением на функции/классы ООП.
2) сама идея «программирования не-айтишниками». О нее уже многие набили шишки. Для не-айтишников приходится максимально упрощать апи, а для этого часто в жертву приходится принести производительность. Причем речь часто идет о потере производительности на порядки. А это быстро сводит на ноль идею масштабирования — ибо масштабированием мы пытаемся повысить производительность, а повышать ее перед этим убив в 10-100 раз — так себе идея.
3) отладка. В монолите мы ставим точку останова и смотрим, что передается. Легко по шагам проходим. Подобных инструментов для микросервисов пока не придумано. В микросервисах, я так понимаю, мы откатываемся назад в развитии средств отладки — по сути до «отладки принтом» — т.е. анализом километров избыточных логов, да еще и разбросанных по разным сервисам.
А еще лучше писать тестируемый код, грамотно декомпозировать и писать качественные логи — тогда и отладчик будет не нужен.
Я лично практически не пользуюсь отладчиков — мне вполне достаточно логов.
Реальность же чаще такова, что есть код какого-то уровня легаси, часть из него вообще нельзя менять и где-то там произошел затык. И надо бы определить где и почему. И у меня стойкое ощущение, что с отладчиком это в разы быстрее, чем по логам. Просто потому, что (очень условно) отладчик позволяет «детализировать/обощать» информацию вплоть до функции. А с логами чаще всего в проектах лишь одна настройка уровня логов на весь проект. Бывает, что у каждого компонента своя настройка уровня логов, но я ни разу не видел возможностей задать для каждой функции свой уровень логов.
У вас потоки есть в монолите? Или всё в один ствол?
Принципиально, нет никакой разницы, монолит у вас с сообщениями между потоками или сервисы.
Что там, что там, дебажить что-то сложное будет одинаково трудно.
Что логи, что дебаггер будут влиять на поведение компонента, притом, логи в гораздо меньшей степени. Я вижу возможности делать разную детализацию логов для разных модулей даже в самописных логгерах, зачем гранулярность до функций — непонятно.
что в монолите можно пользоваться отладчиком,
В микросервисах можно точно также пользоваться отладчиком. В худшем случае брейкпоинты будут в разных сервисах
Отладчик на продакшене — ну-ну. А вот в тестовой среде отлаживать можно, только вот поведение может быть не то. Именно поэтому становятся популярны всяческие решения типа APM/tracing — они позволяют именно на продакшене отлавливать проблемы.
т.е. чтобы дойти до бага, нужно пройти 3-4 сервиса на разных стеках.
2) Вопрос производительности имеет место быть, но он решаем при грамотном проектировании.
3) Да, в монолите в этом плане намного проще :) Микросервисы добавляют сложности, как я написал, в обнаружении проблем и понимании как проходит запрос и какие события при этом создаются.
3). Не особо вижу отличий микро-сервисов от многопоточности в монолите. Если у вас в монолите асинхронное взаимодействие — ваши потоки фактически становятся сервисами. Да, разница может быть в том, что можно всех одновременно убить при ошибке, а так — одно и то же. Разве что, отладчику чуть проще работать в одном процессе, но это очень зависит.
Понимание логики и событий нужно и в случае монолита, при этом, как я уже писал, ошибка в его случае стоит гораздо больше, чем в случае микросервиса.
Как будто монолит (с костылями и велосипедами) не умеет работать в распределенном режиме......
Ценность масштабирования сильно преувеличена — как примеры:
- упираемся в БД — как будем масштабироваться? Надо сначала корневую причину ограничения в БД решить (шардирование, репликация и пр. — что достаточно серьезно)
- разворачиваемся на своем железе — все равно прыгнуть выше головы не сможем и задействовать ресурсы, которых нет.
Конечно, можно двигать в облако… но это реально дорого. И все равно софт к этому должен быть "готов"
разворачиваемся на своем железе — все равно прыгнуть выше головы не сможем и задействовать ресурсы, которых нет
Если нет ресурсов, то тут никакая архитектура не поможет, увы. Но, речь, если что, о горизонтальном масштабировании, которое зачастую дешевле вертикального.
Конечно, можно двигать в облако… но это реально дорого.
Если нет денег на свое железо, про облако можно забыть.
Но, речь, если что, о горизонтальном масштабировании, которое зачастую дешевле вертикального.
Это не так. В смысле — теоретически у вертикального масштабирования сначала цена ниже, потом есть некая точка перегиба и потом только оно становится дороже. А на горизонтальном — всегда есть избыточный оверхед на поддержку этой системы. Единственный плюс горизонтального масштабирования в облаке — возможность отключать неиспользуемые в текущий момент времени инстансы, экономя на этом значительные суммы денег.
Чем в вашем представлении отличается приложение, которое решает одну бизнес-задачу от микросервиса?
Иллюзия дешевизны и простоты испаряется при начале эксплуатации, поиске кадров и координации разработки при выкатке разных версий микросервисов.
Иллюзия дешевизны и простоты
Это ошибочная иллюзия. Если у бизнеса есть цель уйти от проблем монолита, то за это придется платить. Тут дело в том, что если ваши конкуренты смогли перейти на микросервисы и получить ускорение, то вам тоже придется это сделать, потому что захочется не отставать в скорости.
Может обычный decoupling достаточен?
Зачастую продукту и не требуется горизонтальная масштабируемость (нагрузки небольшие) и микросервисы не выгодны как архитектурное решение для поставленной задачи.
В зависимости от взаимодействий отделов, другой отдел вполне может использовать либо коробочное приложение 3-ей фирмы, либо создать другое самодостаточное приложение.
Главное, чтоб решало задачи, выдерживало пиковые нагрузки, интегрировалось и могло прорабоать х лет без серьезных вложений в доработку и обслуживание.
Однако, архитекторы часто на это не идут: не модно и тормозит профессиональный рост.
А бизнесу можно протулить все что угодно, все-равно лохи в современных технологиях.
На случай pushback: 25+ лет использую разные архитектуры для разных задач, включая описанные автором решения.
Суть: разным задачам разная архитектура.
В своей практике делаю два условных слоя: Сервисы и Бизнес логика. Также есть их этапы эволюции:
1. Монолит. Сервисы отвечают за свою предметную область и вначале предоставляют просто CRUD, Бизнес Логика же использует эти сервисы под свои потребности. Если бизнес логика повторяется в нескольких местах, то я оставляю дубликат кода, так как логика может поменять в одном из мест достаточно быстро.
2. Монолит. При формировании уже устойчивой бизнес логики можно анализировать дубликаты кода для определённой предметной области и выносит в соответствующий Сервис. Тем самым мы уменьшаем код в Бизнес Логики и начинаем наращивать сервисы устойчивой логикой уменьшая вариативность их использования.
3. Микросервисы. После формирования Сервисов с решением своей задачи в предметной области(а не CRUD), можно выносит такие Сервисы в отдельные узлы со своими техническими особенностями при необходимости. При этом у нас остаётся оркестрация в виде Бизнес Логики.
Описанный выше подход не использует триггеры и эвенты, Сервисы не общаются между собой никак, вся логика вызовов строится внутри Бизнес Логики, на то это и оркестрация. Если посередине Процесса-1 одного сервиса нужно вызвать Процесс-2 другого сервиса, то Процесс-1 просто разбивается на два отдельных Процесса и Бизнес логика вызывает их по порядку передавая данные между ними.
Также это очень хорошо ложится под паттерн Saga и вопрос с распределёнными транзакциями.
P.S.
В 2012 году наткнулся на блог Александра, даже задавал вопросы по архитектуре, состоял в .net рассылке. Спасибо большое, Вы внесли большой вклад в моё развитие. Рад, что спустя такое количество времени нахожу общие идеи и могу понимать все эти решения.
От микросервисного монолита к оркестратору бизнес-сервисов