Это расшифровка выступления на DevopsConf 2019-10-01 и SPbLUG 2019-09-25.
Это история проекта, на котором использовалась самописная система управления конфигурациями и почему переезд на Ansible затянулся на 18 месяцев.
День № -ХХХ: Before the beginning

Изначально инфраструктура представляла собой множество отдельно стоящих хостов под управлением Hyper-V. Создание виртуальной машины требовало множество действий: положить диски в нужное место, прописать DNS, зарезервировать DHCP, положить конфигурацию ВМ в git репозиторий. Этот процесс был частично механизирован, но например ВМ распределялись между хостами руками. Но, например, разработчики могли поправив конфигурацию ВМ в git применить её перезагрузив ВМ.
Custom Configuration Management Solution

Изначальная идею, подозреваю, задумывали как IaC: множество stateless ВМ, которые при перезагрузке обнуляли своё состояние. Что из себя представляло управление конфигурациями ВМ? Схематично выглядит просто:
- Для ВМ прибивали статический MAC.
- К ВМ подключали ISO с CoreOS и загрузочный диск.
- CoreOS запускает скрипт кастомизации скачав его с WEB сервера на основании своего IP.
- Скрипт выкачивает через SCP конфигурацию ВМ основываясь на IP адресе.
- Запускается портянка systemd unit файлов и портянка bash скриптов.
У этого решения было множество очевидных проблем:
- ISO в CoreOS было deprecated.
- Множество сложно автоматизированных действий и магии при миграции/создании ВМ.
- Сложность с обновлением и когда необходимо ПО какой-то версии. Еще веселее с модулями ядра.
- ВМ не такие уж без данных получались, т.е. появились ВМ у которых смонтирован диск с пользовательскими данными дополнительно.
- Постоянно кто-то косячил с зависимостями systemd unit и при перезагрузке CoreOS зависала. Имеющимися средствами в CoreOS отловить это было проблемно.
- Управление секретами.
- CM не было считай. Был bash и YML конфиги CoreOS.
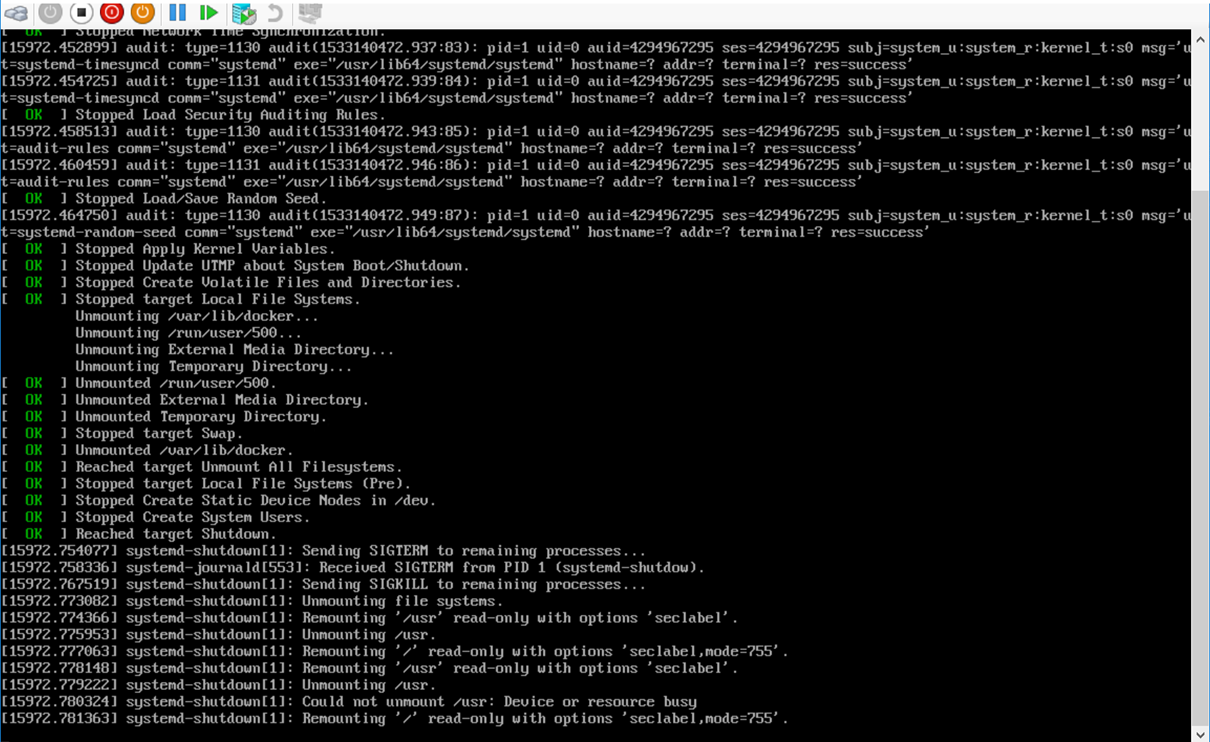
Что бы применить конфигурацию ВМ необходимо ее перезагрузить, но она могла не перезагрузиться. Вроде очевидная проблема, но персистентных дисков нет — логи сохранять некуда. Ну ок, давайте попробуем добавить опции загрузка ядра что бы логи пересылали. Но нет, как это сложно всё.
День №0: Признание проблемы
Это была обычная разработческая инфраструктура: jenkins, тестовые окружения, мониторинги, registry. CoreOS задумывалась для хостинга k8s кластеров, т.е. проблема была в том, как использовалась CoreOS. Первым шагом был выбор стэка. Мы остановились на:
- CentOS как базовый дистрибутив, т.к. это наиболее близкий дистрибутив к production окружениям.
- Ansible для управления конфигурациями, т.к. по нему была обширная экспертиза.
- Jenkins как фрэймворк автоматизации существующих процессов, т.к. он уже активно использовался для процессов разработки
- Hyper-V как платформа виртуализации. Есть ряд причин, выходящих за рамки рассказа, но если кратко — мы не можем использовать облака, должны использовать своё железо.
День №30: Фиксируем существующие договоренности — Agreements as Code
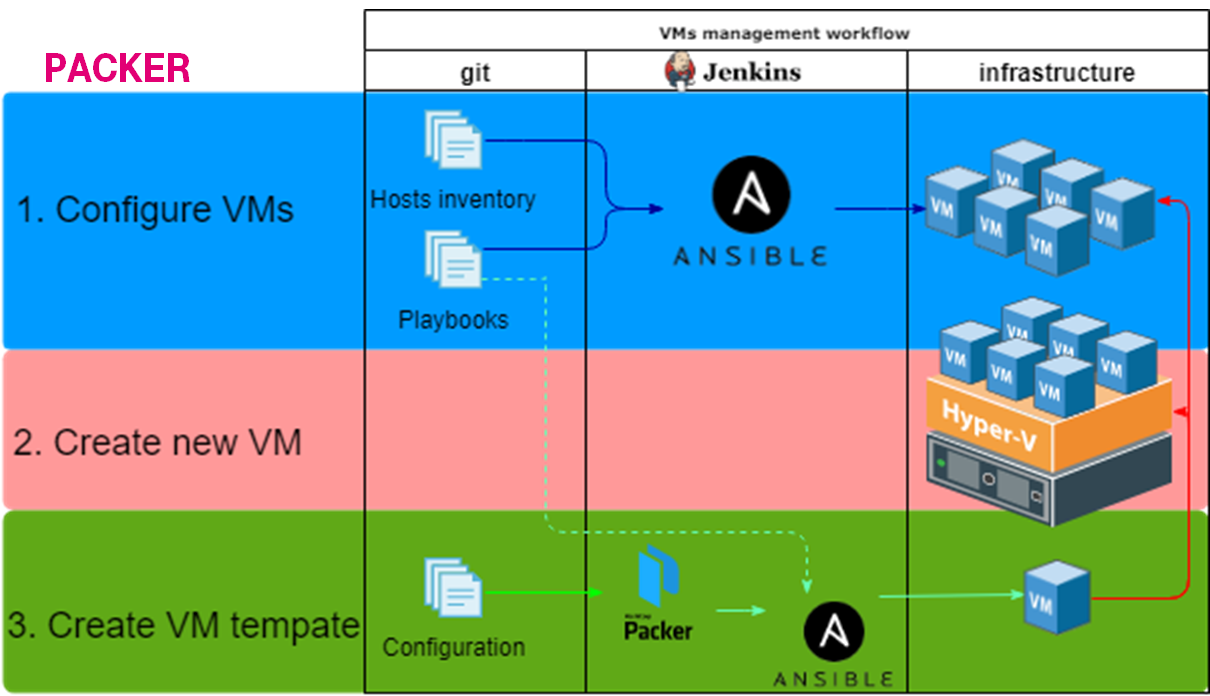
Когда был понятен стэк, началась подготовка к переезду. Фиксирование существующих договоренностей в виде кода (Agreements as Code!). Переход ручной труд -> механизация -> автоматизация.
1. Configure VMs
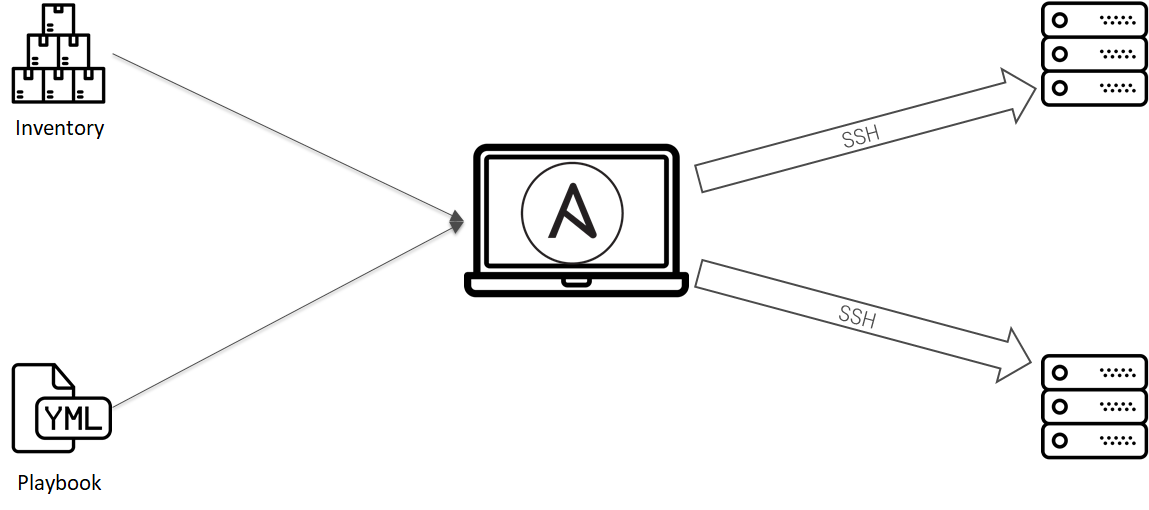
Ansible отлично справляется с этой задачей. С минимум телодвижений можно взять под управление конфигурациями ВМ:
- Создаем git репозиторий.
- Складываем список ВМ в inventory, конфигурации в плэйбуки и роли.
- Настраиваем специальный jenkins slave с которого можно будет запускать ansible.
- Создаем job, настраиваем Jenkins.
Первый процесс готов. Договорённости зафиксированы.
2. Create new VM
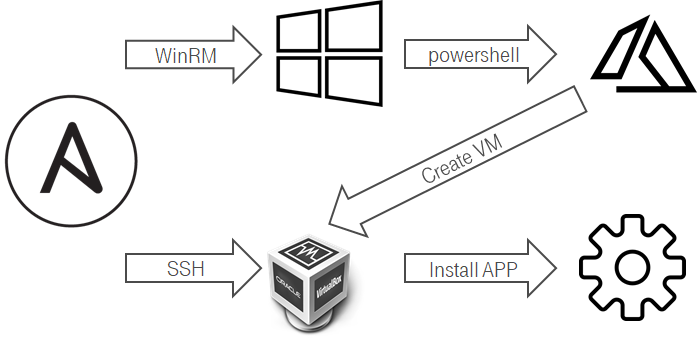
Здесь все не очень удобно было. Из линукс не очень удобно создавать ВМ на Hyper-V. Одной из попыток механизировать это процесс было:
- Ansbile подключается через WinRM к windows хосту.
- Ansible запускает powershell скрипт.
- Powershell скрипт создает новую ВМ.
- Средствами Hyper-V/ScVMM при создании вм в гостевой ОС настраивается hostname.
- ВМ при обновление DHCP lease отсылает свой hostname.
- Штатная интеграция ddns & dhcp на стороне Domain Controller настраивает DNS запись.
- Можно добавлять ВМ в инвентори и настраивать ее Ansible.
3. Create VM template
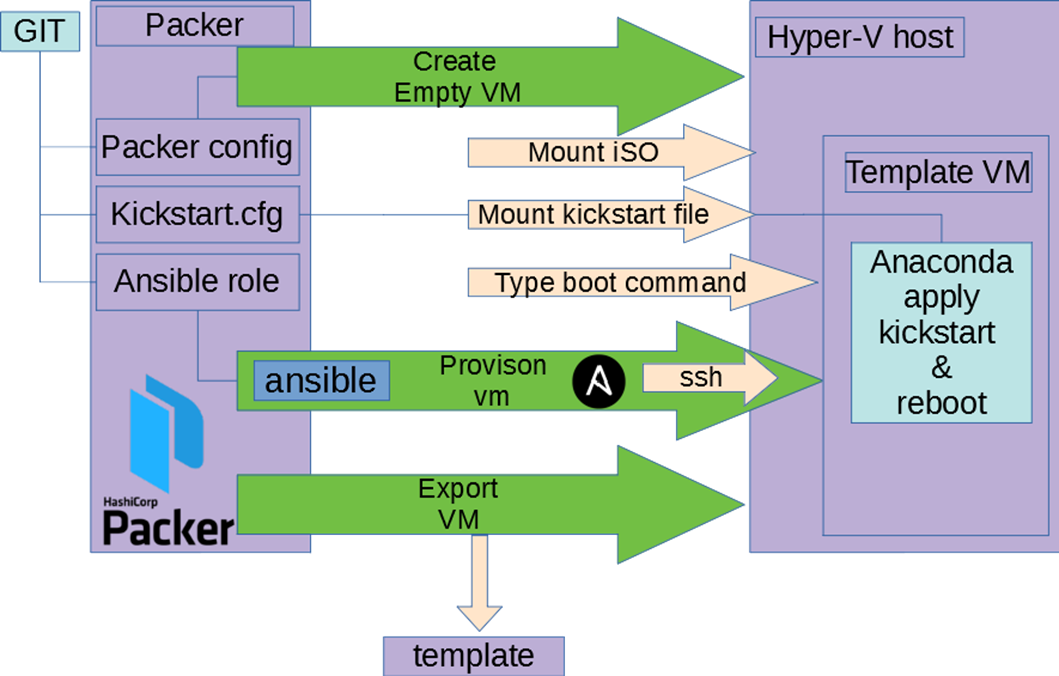
Здесь не стали ничего изобретать — взяли packer.
- В git репозиторий складываем конфиг packer, kickstart.
- Настраиваем специальный jenkins slave с hyper-v и Packer.
- Создаем job, настраиваем Jenkins.
Как работает эта связка:
- Packer создает пустую ВМ, подцепляет ISO.
- ВМ загружается, Packer вводит в загрзучик команду использовать наш kickstart файл с дискеты или http.
- Запускается anaconda с нашим конфигом, делается первичная настройка ОС.
- Packer дожидается доступности ВМ.
- Packer внутри ВМ запускает ansible в локальном режиме.
- Ansible используя ровно те же роли что в шаге №1 отрабатывает.
- Packer экспортирует шаблон ВМ.
День №75: Рефакторим договоренности не ломая = Test ansible + Testkitchen
Зафиксировать договоренности в коде может быть недостаточно. Ведь если в подноготной процессе ты захочешь что-то поменять — ты можешь что-то сломать. Поэтому в случае инфраструктуру появляется тестирование этой самой инфраструктуры. Что бы синхронизировать знания в рамках команды стали тестировать Ansible роли. Не буду углублять т.к. есть статья описывающие события в тот момент времени Протестируй меня если сможешь или мечтают ли YML программисты о тестирование ansible?(спойлер это был не финальный вариант и позже все стало сложнее Как начать тестировать Ansible, отрефакторить проект за год и не слететь с катушек).
День №130: А может CentOS+ansible не нужен? может openshift?
Надо понимать, что процесс внесения инфраструктуры был не единственным и были побочные подпроекты. Например, пришел запрос на запуск нашего приложения в openshift и это вылилось в исследования не на одну неделю Запускаем приложение в Openshift и сравниваем существующий инструментарий что затормозило процесс переезда. Итогом оказалось, что openshift не закрывает всех потребностей, необходимо реальное железо, ну или хотя бы возможность играться с ядром.
День №170: Openshift не подходит, рискнем с Windows Azure Pack?
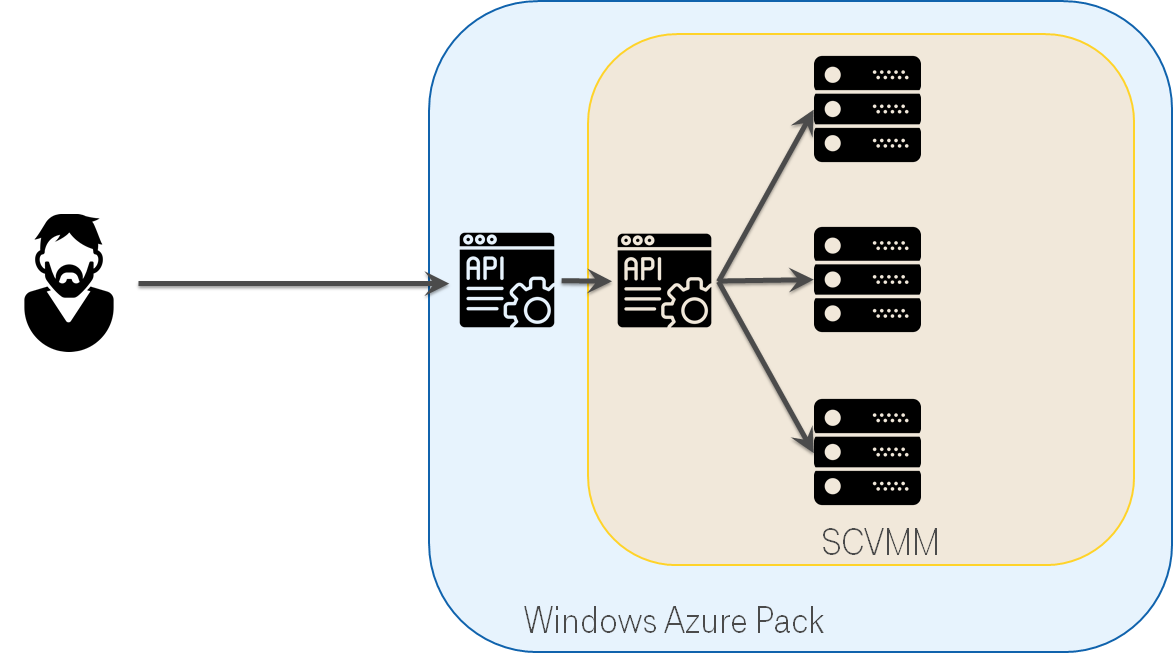
Hyper-V не очень дружелюбен, SCVMM не делает его сильно лучше. Но есть такая штука Windows Azure Pack, которая является надстройкой над SCVMM и мимикрирует под Azure. Но в реальности продукт выглядит заброшенным: документация с битыми ссылками и весьма скудная. Но в рамках исследования вариантов упрощения жизни нашего облака смотрели и на него тоже.
День №250: Windows Azure Pack не очень. Остаемся на SCVMM
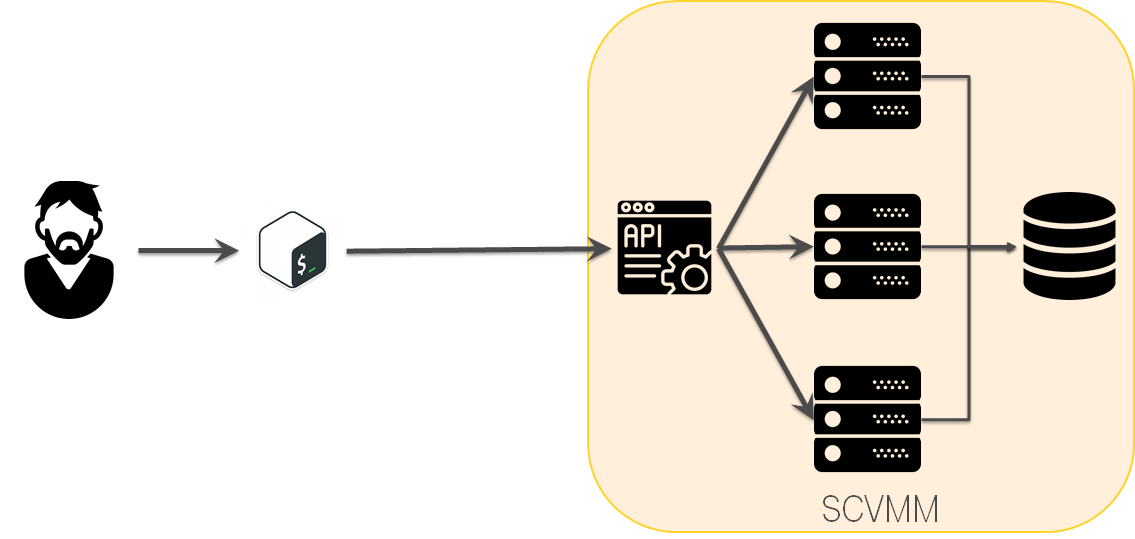
Windows Azure Pack выглядел многообещающим, но было решено не привносить WAP c его сложностями в систему ради ненужных фич и остались на SCVMM.
День №360: Едим слона по частям
Только спустя год была готова платформа куда переезжать и начался процесс переезда. Для этого была поставлена S.M.A.R.T. задача. Выписали все ВМ и начали по одной разбираться с конфигурацией, описывать ее на Ansible, покрывать тестами.
День №450: Какая система получилась?
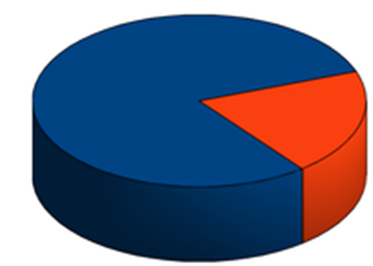
Сам процесс не интересен. Он рутинен, можно отметить, что большинство конфигураций были относительно простыми или изоморфными и по принципу Парето 80% конфигураций вм потребовало 20% времени. По тому же принципу 80% времени ушло на подготовку переезда и только 20% на сам переезд.
День №540: Финал
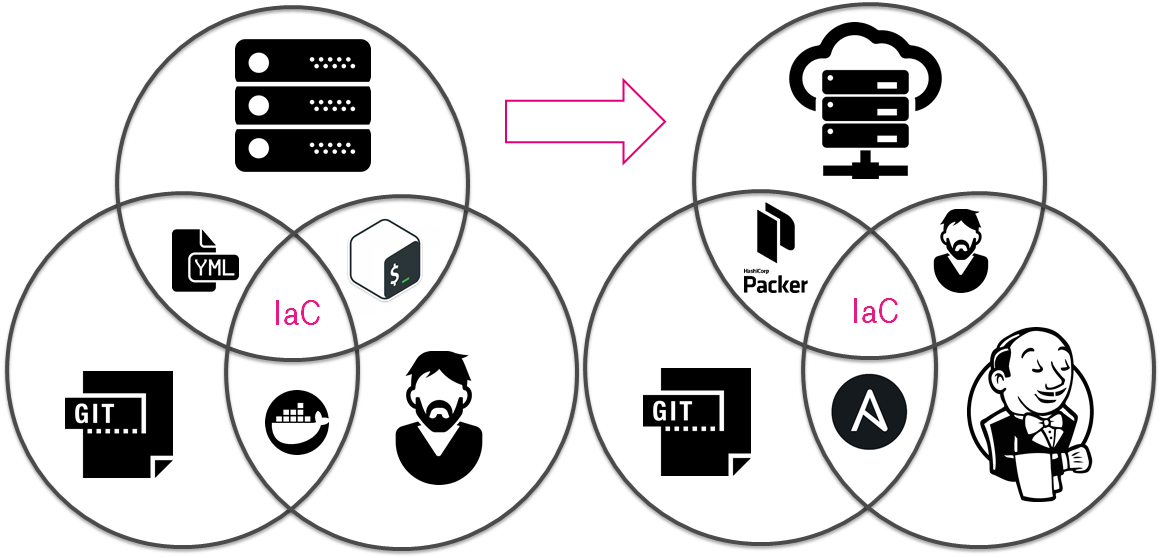
Что же произошло за 18 месяцев?
- Договоренности стали кодом.
- Ручной труд -> Механизация -> Автоматизация.
Links
- Английская версия
- Кросс пост из личного блога
- slides
- Как начать тестировать Ansible, отрефакторить проект за год и не слететь с катушек
- Lessons learned from testiting Over 200 000 lines of Infrastructure Code
- Let us deploy to openshift
- How-to test your own OS distribution
- Test me if you can. Do YML developers Dream of testing ansible?
