
Это расшифровка выступления на DevOps-40 2020-03-18:
Начиная со второго коммита любой код становится legacy, т.к. изначальные задумки начинают расходиться с суровой реальностью. Это не хорошо и не плохо, это данность с которой сложно спорить и необходимо уживаться. Частью этого процесса является рефакторинг. Рефакторинг Infrastructure as Code. Да начнется история как отрефакторить Ansible за год и не слететь с катушек.
Зарождение Legacy
День № 1: Нулевой пациент
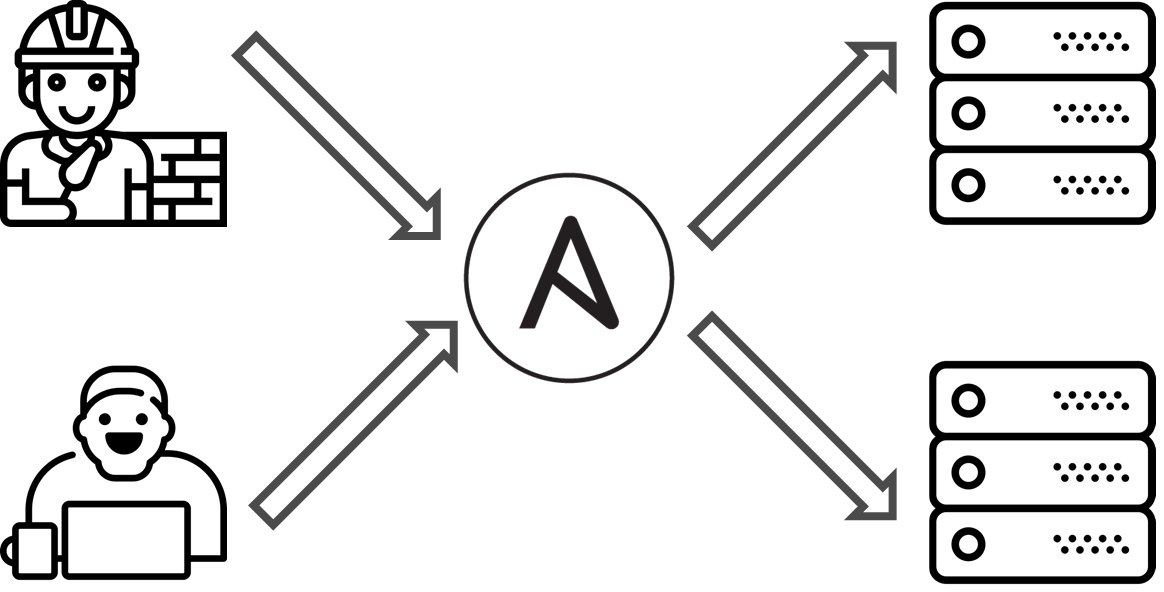
Жил был условный проект. На нем была Dev команда разработки и Ops инженеры. Они решали одну и ту же задачу: как развернуть сервера и запустить приложение. Проблема была в том, что каждая команда решала эту задачу по своему. На проекте было принято решение использовать Ansible для синхронизации знаний между командами Dev и Ops.
День № 89: Зарождение Legacy

Сами того не заметив, хотели сделать как можно лучше, а получилось legacy. Как так получается?
- У нас тут срочная таска, сделаем грязный хак — потом исправим.
- Документацию можно не писать и так всё понятно что тут происходит.
- Я знаю Ansible / Python / Bash / Terraform! Смотрите как я могу извернуться!
- Я Full Stack Overflow Developer скопировал это со stackoverflow, не знаю как это работает, но выглядит прикольно и решает задачу.
В итоге можно получить код непонятного вида, на который нет документации, непонятно что он делает, нужен ли он, но проблема в том, что вам необходимо его развивать, дорабатывать, добавлять костыли с подпорками, делая ситуацию только еше хуже.
- hosts: localhost tasks: - shell: echo -n Z >> a.txt && cat a.txt register: output delay: 1 retries: 5 until: not output.stdout.find("ZZZ")
День № 109: Осознание проблемы

Изначально задуманная и реализованная модель IaC перестаёт отвечать действительности с запросами пользователей / бизнеса / других команд, время внесение изменений в инфраструктуру перестаёт быть приемлемым. В этот момент приходит понимание, что пора принимать меры.
Рефакторинг IaC
День № 139: А вам точно нужен рефакторинг?
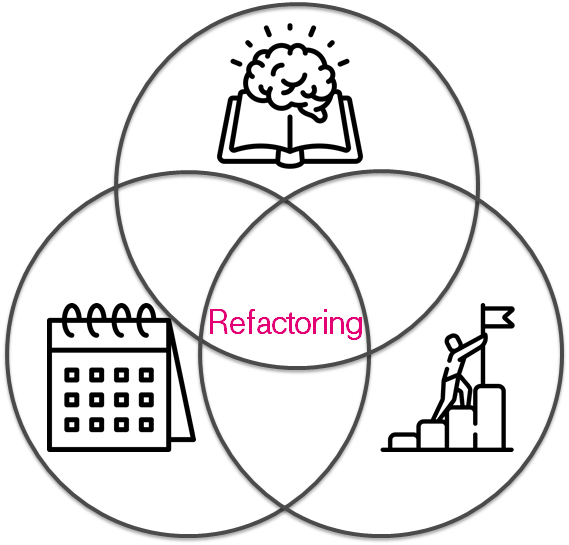
Прежде чем кидаться рефакторить вы должны ответить на ряд важных вопросов:
- Зачем вам всё это?
- Есть ли у вас время?
- Достаточно ли знаний?
Если вы не знаете как ответить на вопросы, то рефакторинг закончится так и не начавшись или может получиться только хуже. Т.к. был опыт( Что я узнал, протестировав 200 000 строк инфраструктурного кода), то от проекта пришел запрос помощи исправить роли и покрыть их тестами.
День № 149: Подготовка рефакторинга
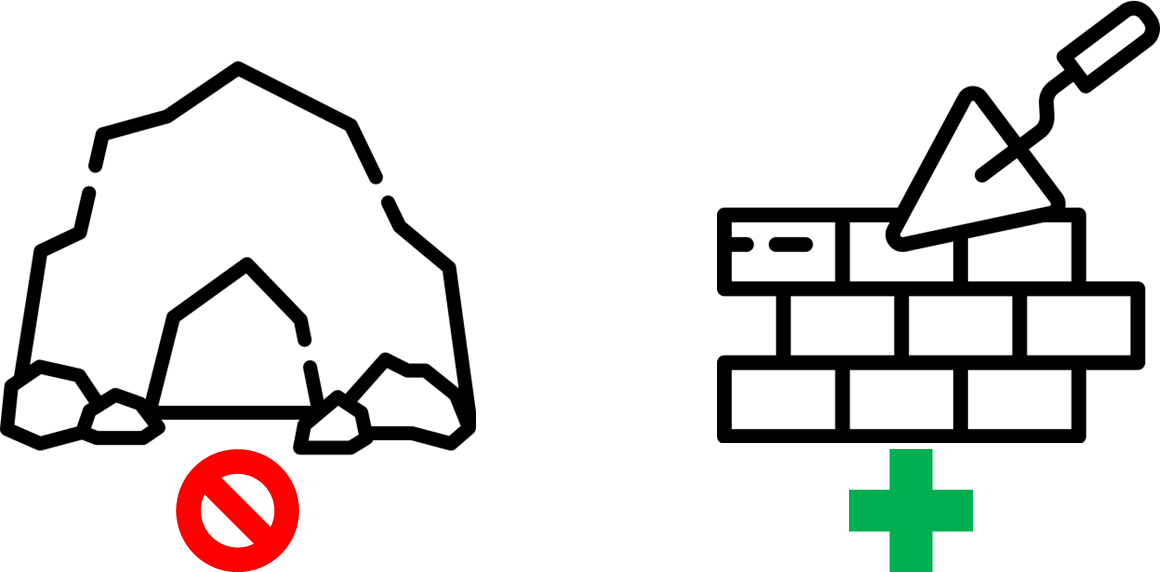
Первоочерeдное это надо подготовиться. Определиться что будем делать. Для этого общаемся, находим проблемные точки и прикидываем пути их решения. Полученные концепты как-то фиксируем, например статья в confluence, что бы при появление вопроса "как лучше?" или "как правильнее?" мы не сбились с курса. В нашем случае мы придерживались идеи разделяй и властвуй: дробим инфраструктуру на маленькие кусочки / кирпичики. Такой подход позволяет взять изолированный кусок инфраструктуры, понять что он делает, покрыть его тестами и изменить не побоявшись что-нибудь сломать.
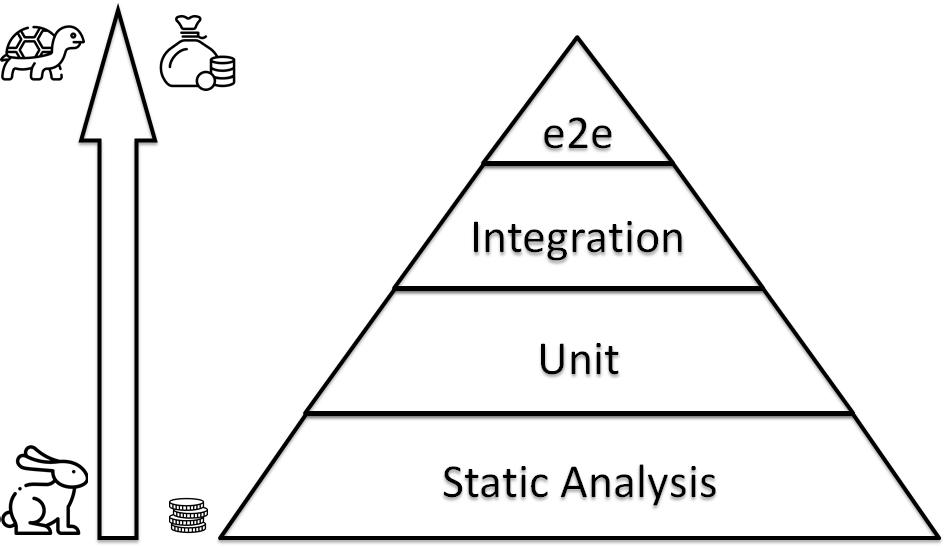
Получается, что тестирование инфраструктуры становится краеугольным камнем и тут стоит упомянуть пирамиду тестирования инфраструктуры. Ровно таже идея, что в разработке, но для инфраструктуры: идем от дешевых быстрых тестов которые проверяют простые вещи, например отступы, к дорогим полноценным тестами разворачивающих цельную инфраструктуру.
Попытки тестирования Ansible
Прежде чем пойдем описывать как покрывали тестами Ansible на проекте, опишу попытки и подходы которые довелось использовать ранее, что бы понять контекст принимаемых решений.
День № -997: SDS provision
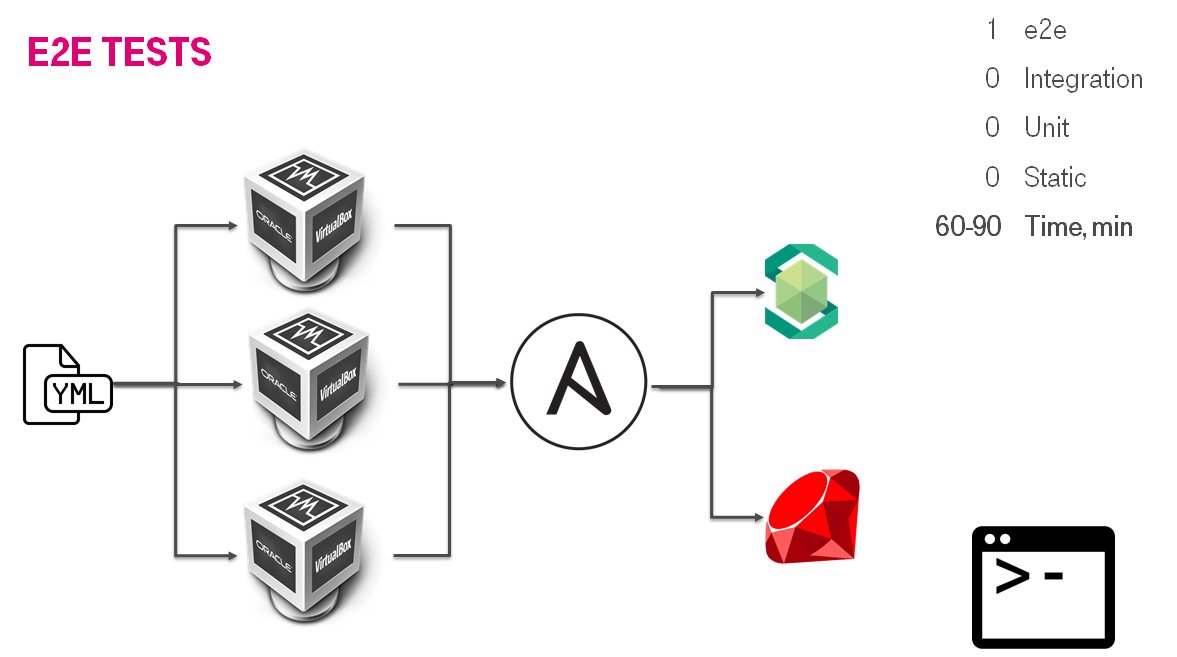
Первый раз тестировать Ansible довелось на проекте по разработке SDS (Software Defined Storage). Есть отдельная статья на эту тему
Как наломать велосипедов поверх костылей при тестировании своего дистрибутива, но если кратко, то у нас получилась перевернутая пирамида тестирования и тестирование мы тратили 60-90 минут на одну роль, что есть долго. Основа была e2e тесты, т.е. мы разворачивали полноценную инсталляцию, и потом ее тестировали. Еще отягчающим было изобретение своего велосипеда. Но надо признаться это решение работало и позволяло стабильно релизиться.
День № -701: Ansible и test kitchen
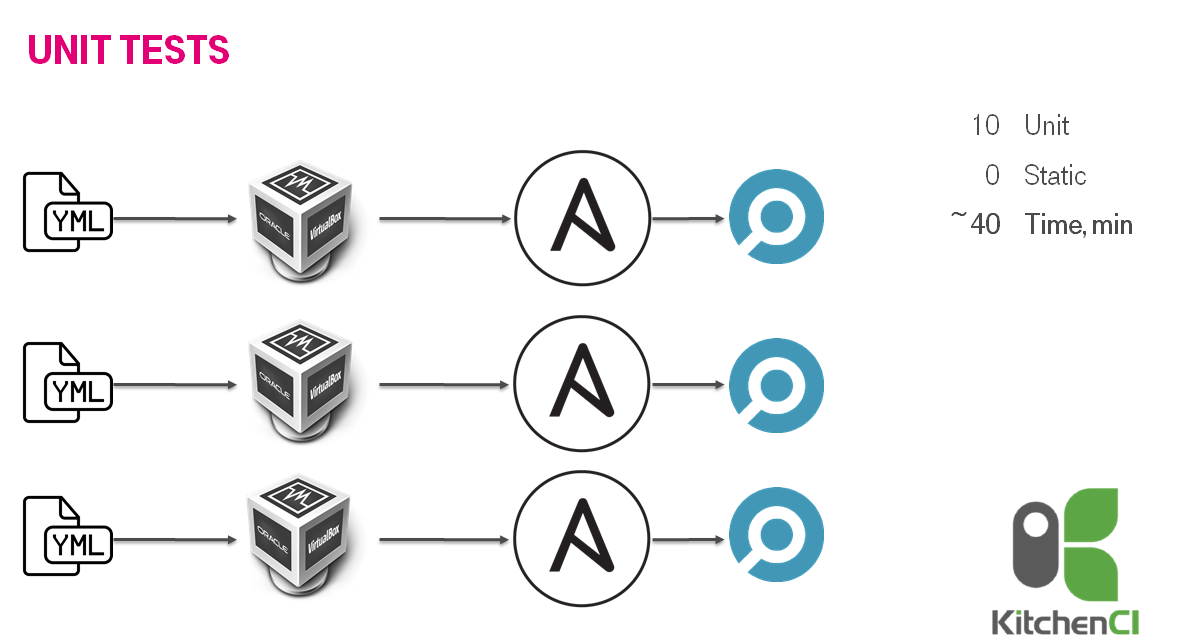
Развитием идеи тестирования Ansible стало использование готовых инструментов, а именно test kitchen / kitchen-ci и inspec. Выбор был обусловен знанием Ruby ( подробней в статье на хабре: Мечтают ли YML программисты о тестировании ansible?) работало быстрее порядка 40 минут на 10 ролей. Мы создавали пачку виртуальных машин и внутри гоняли тесты.
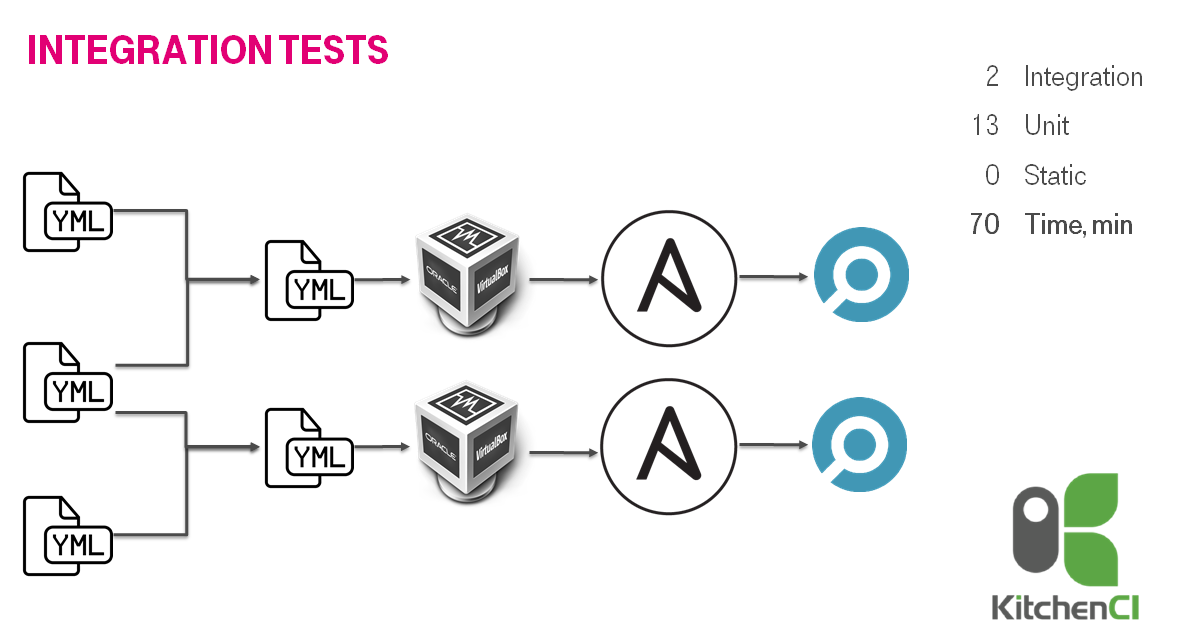
В целом решение работало, но был осадочек из-за неоднородности. Когда же увеличили количество тестируемых до 13 базовых ролей и 2 мета ролей комбинирующие более мелкие роли, то вдруг тесты стали бежать 70 минут, что почти в 2 раза дольше. Об XP (extreme programming) практиках было сложно говорить т.к. никто не захочет ждать 70 минут. Это стало подоводом для изменения подхода
День № -601: Ansible и molecule
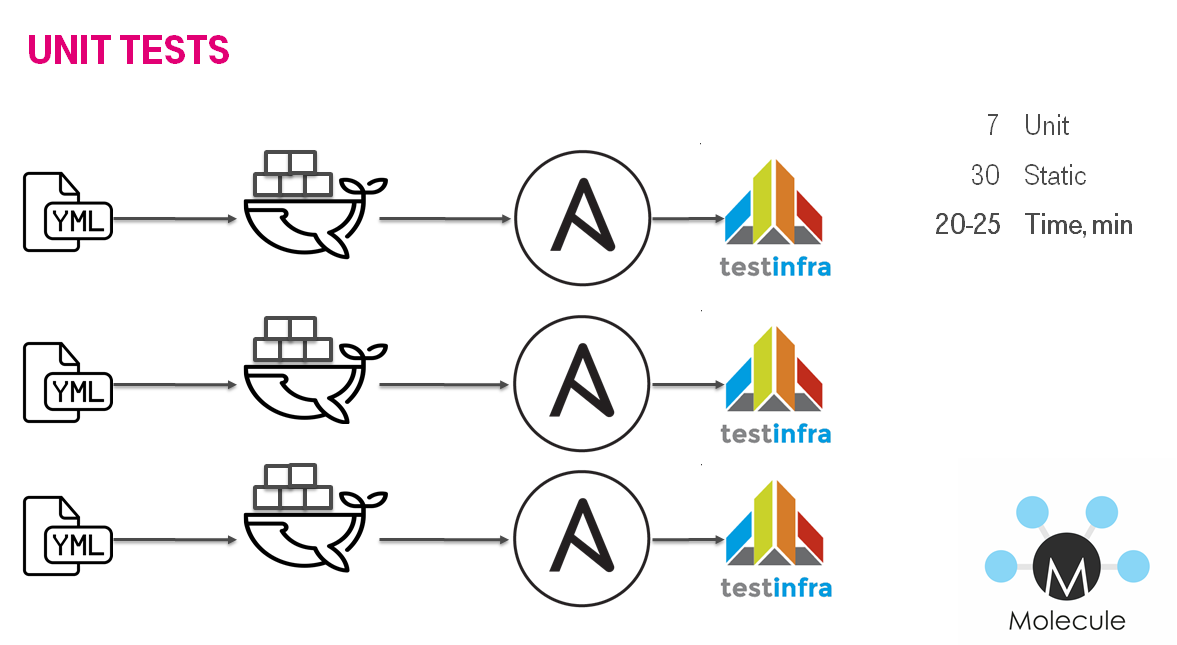
Концептуально это похоже на testkitchen, только мы перевели тестирование ролей в docker и сменили стэк. Итогом, время сократилось до стабильных 20-25 минут для 7 ролей.
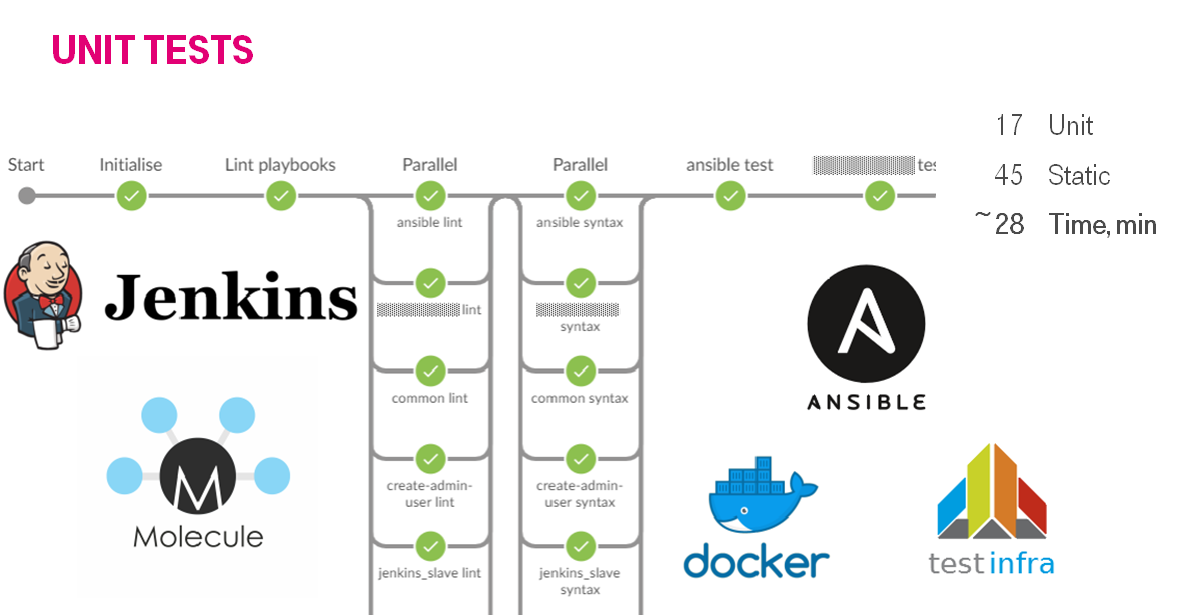
Увеличив количество тестирумых ролей до 17 и линтовку 45 ролей мы прогоняли это за 28 минут на 2 jenkins slave.
День № 167: Добавляем на проект тесты Ansible

С наскоку задачу рефакторинга, скорей всего сделать не получится. Задача должна быть измеримой, что бы вы могли ее разбить на мелкие кусочки и съесть слона по частям чайной ложкой. Должно быть понимание в правильном ли вы направлении идет движение, долго ли еще идти.
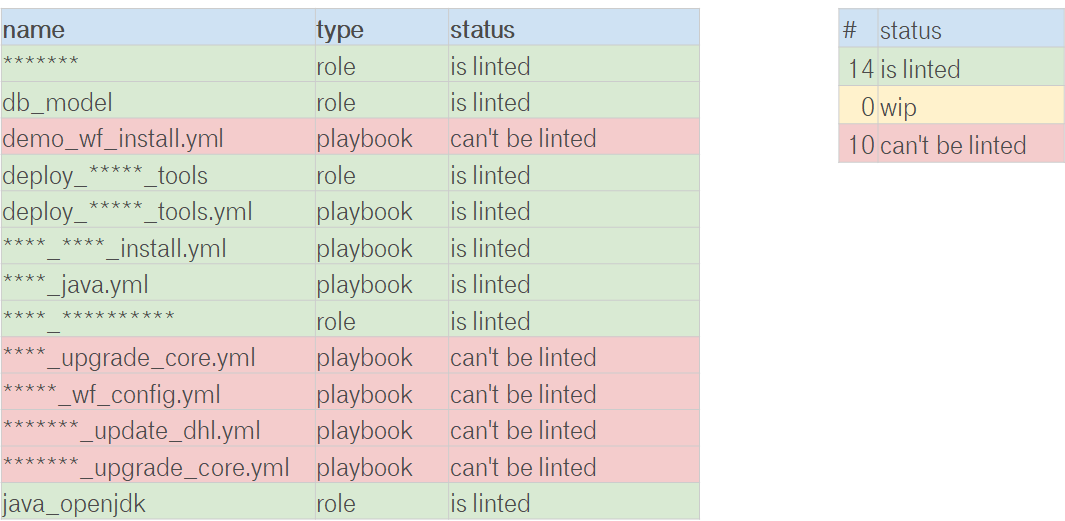
В целом не суть важно как это будет сделано, можно писать на бумажку, можно клеить стикеры на шкаф, можно создавать таски в jira, а можно завести google docs И туда записывать текущий статус. Ноги растут из того, что процесс не сиюминутный, он будет долгий и нудный. Маловероятно, что кто-то хочет, что бы за время рефакторинга вы перегорели идей, устали и забили.
Рефакторинг прост:
- Eat.
- Sleep.
- Code.
- IaC test.
- Repeat
и так повторяем пока не достигнем намеченной цели.
Все сразу начать тестировать может не получится, поэтому у нас первой задачей было начать с линтовки и проверки синтаксиса.
День № 181: Green Build Master
Линтовка это небольшой первый шаг к Green Build Master. Это почти ничего не сломает, но позволит отладить процессы и сделать зелененькие билды в jenkins. Идея в том, что бы выработать привычки у команды:
- Красные тесты плохо.
- Пришёл исправить что-то заодно сделай код чуть лучше, чем он был до тебя.
День № 193: От линтовки к unit тестам
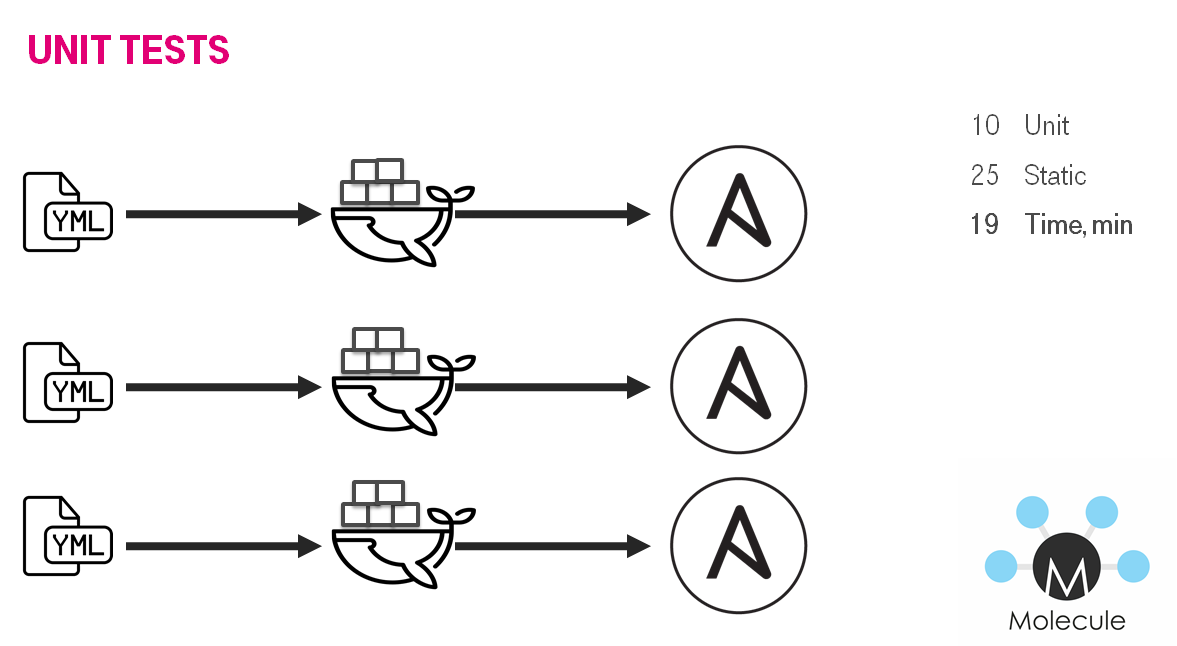
Выстроив процесс попадания кода в мастер можно начинать процесс поэтапного улучшения — заменяя линтовку на запуск ролей, можно даже без идемпотентности. Необходимо понять как применять роли, как они работают.
День № 211: От unit к integration тестам
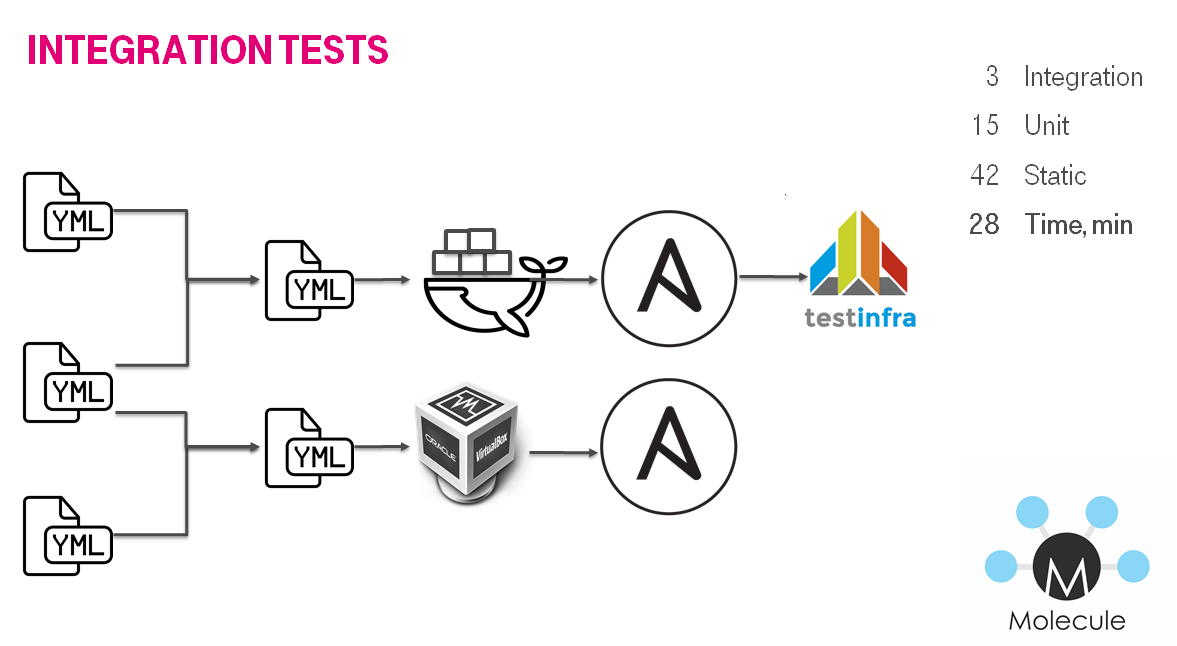
Когда unit тестами покрыто большинство ролей и всё линтуется, можно переходит к добавлению интеграционных тестов. Т.е. тестированию не отдельного кирпичика в инфраструктуре, а их комбинации, например полноценную конфигурацию инстанса.
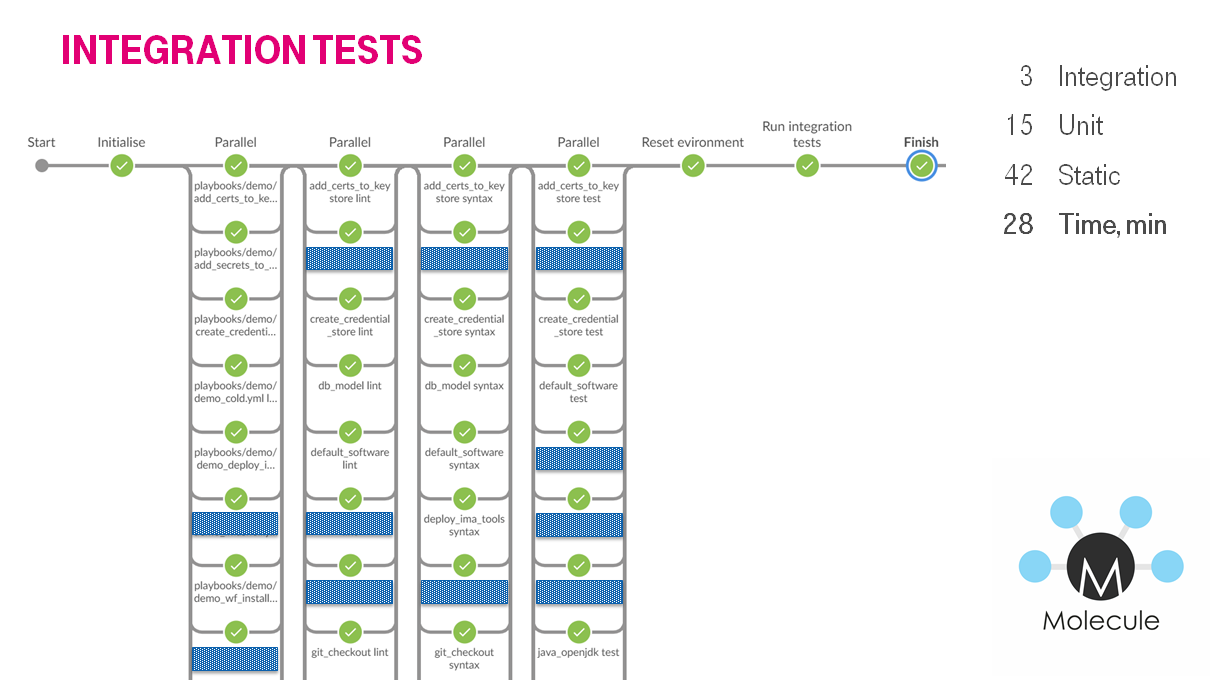
На jenkins мы генерировали множество стадий, которые в параллель линтовали роли / плэйбуки, потом юнит тесты в контейнерах и в конце интеграционные тесты.
Jenkins + Docker + Ansible = Tests
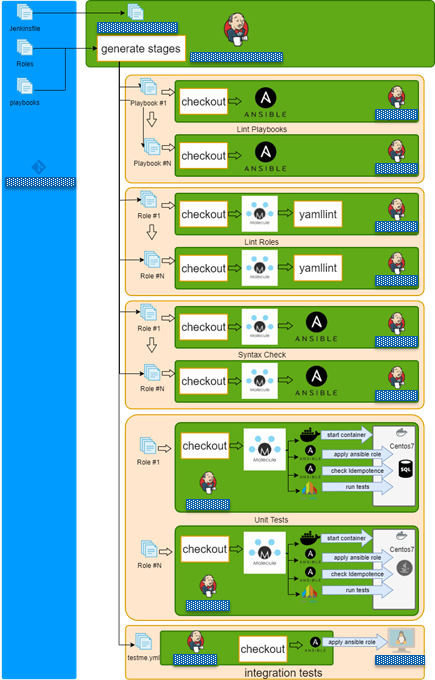
- Checkout repo and generate build stages.
- Run lint playbook stages in parallel.
- Run lint role stages in parallel.
- Run syntax check role stages in parallel.
- Run test role stages in parallel.
- Lint role.
- Check dependency on other roles.
- Check syntax.
- Create docker instance
- Run molecule/default/playbook.yml.
- Check idempotency.
- Run integration tests
- Finish
День № 271: Bus Factor
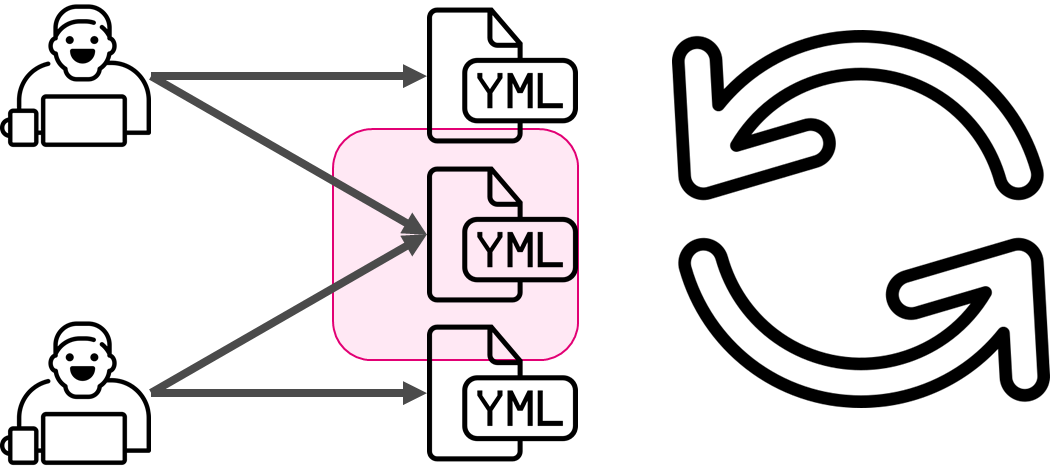
Первое время рефакторингом занималась небольшая группа людей в пару-тройку человек. Они делали ревью кода в мастерe. Со временем в команде вырабатолось знание как писать код и code review способствовало распространению знаний об инфраструктуре и том как она устроена. Изюминкой здесь было, то что ревьюверы выбирались по очереди, по графику, т.е. с некоторой долей вероятности ты залезешь в новый участок инфраструктуры.
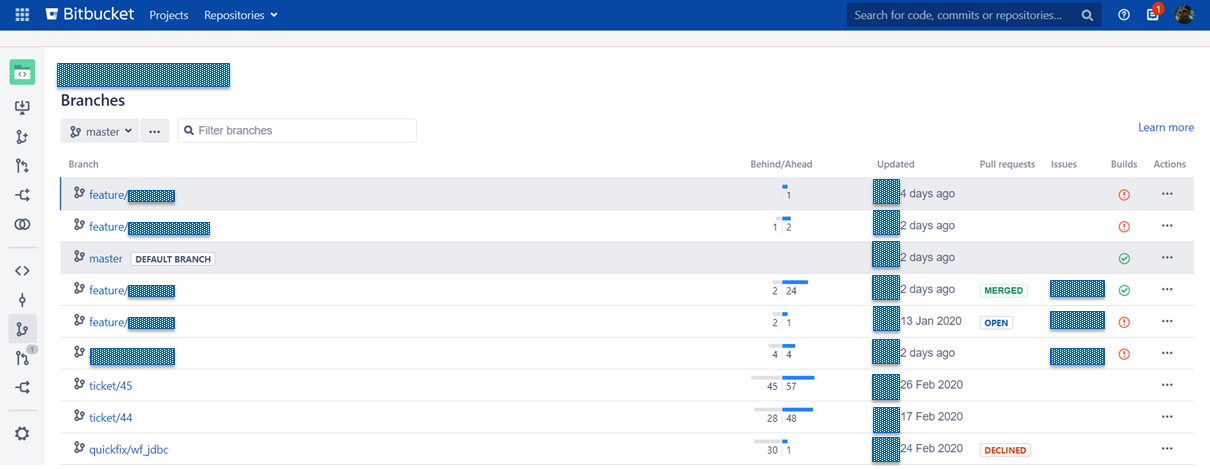
И здесь должно быть удобно. Удобно делать ревью, видеть в рамках какой задачи оно сделано, историю обсуждений. Мы интегрировали jenkins + bitbucket + jira.
Но как таковое ревью не панацея, как-то, у нас пролез в мастер код, который сделал нам флапающие тесты:
- get_url: url: "{{ actk_certs }}/{{ item.1 }}" dest: "{{ actk_src_tmp }}/" username: "{{ actk_mvn_user }}" password: "{{ actk_mvn_pass }}" with_subelements: - "{{ actk_cert_list }}" - "{{ actk_certs }}" delegate_to: localhost - copy: src: "{{ actk_src_tmp }}/{{ item.1 }}" dest: "{{ actk_dst_tmp }}" with_subelements: - "{{ actk_cert_list }}" - "{{ actk_certs }}"
Потом это исправили, но осадочек остался.
get_url: url: "{{ actk_certs }}/{{ actk_item }}" dest: "{{ actk_src_tmp }}/{{ actk_item }}" username: "{{ actk_mvn_user }}" password: "{{ actk_mvn_pass }}" loop_control: loop_var: actk_item with_items: "{{ actk_cert_list }}" delegate_to: localhost - copy: src: "{{ actk_src_tmp }}/{{ actk_item }}" dest: "{{ actk_dst_tmp }}" loop_control: loop_var: actk_item with_items: "{{ actk_cert_list }}"
День № 311: Ускоряем тесты
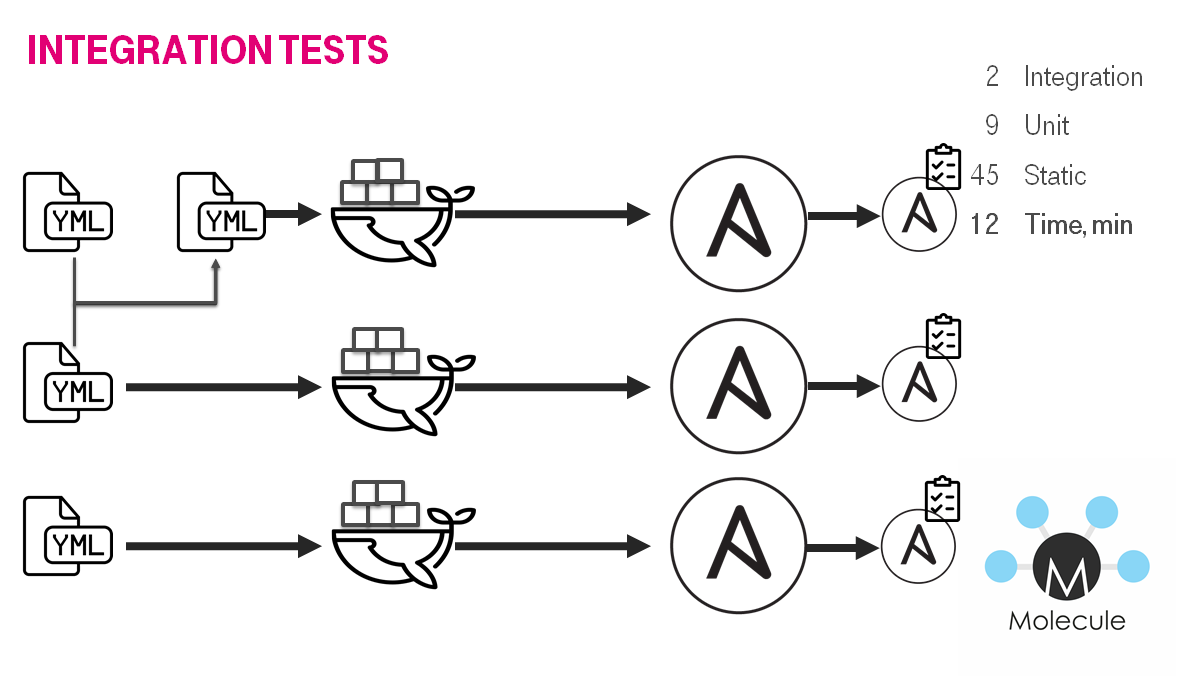
Со вренем тестов становилось больше, билды бежали медленнее до часа в плохом случае. На одном из ретро была фраза по типу "хорошо что есть тесты, но они медленные". В итоге мы отказались от интеграционных тестов на виртуальных машинах и адаптировали под docker, дабы было быстрее. Так же заменили testinfra на ansible verifier что бы уменьшить кол-во используемых инструментов.
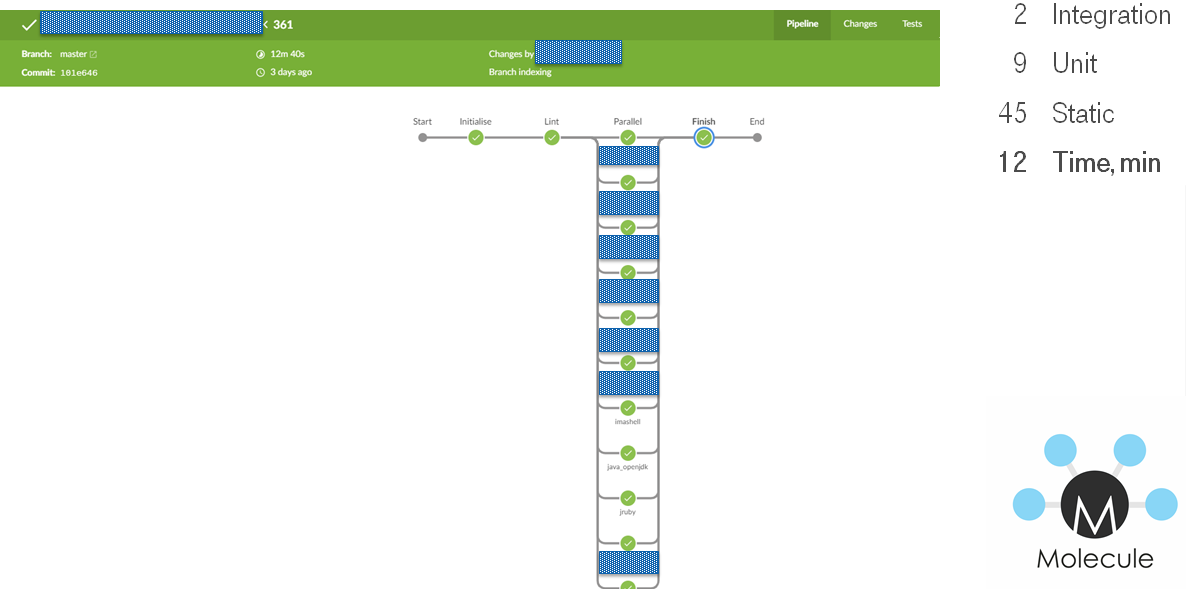
Строго говоря тут был комплекс мер:
- Переход на docker.
- Убрать тестирование ролей, которое дублируется за счет зависимостей.
- Увеличить кол-во слэйвов.
- Порядок запуска тестов.
- Возможность линтовать ВСЁ локально одной командой.
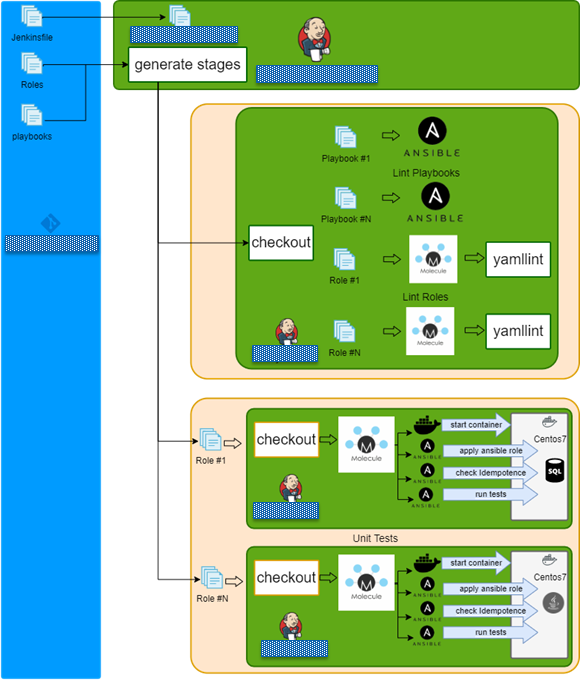
В итоге Pipeline на jenkins тоже унифицировался
- Generate build stages.
- Lint all in parallel.
- Run test role stages in parallel.
- Finish.
Lessons learned
Avoid global variables
Ansible использует глобальные переменные, есть частичный workaround в виде private_role_vars, но это не панацея.
Приведу пример. Пусть у нас есть role_a и role_b
# cat role_a/defaults/main.yml --- msg: a # cat role_a/tasks/main.yml --- - debug: msg: role_a={{ msg }}
# cat role_b/defaults/main.yml --- msg: b # cat role_b/tasks/main.yml --- - set_fact: msg: b - debug: msg: role_b={{ msg }}
- hosts: localhost vars: msg: hello roles: - role: role_a - role: role_b tasks: - debug: msg: play={{msg}}

Забавная вещь, что результат работы плэйбуков будет зависеть от не всегда очевидных вещей, например очередности перечисления ролей. К сожалению это в натуре Ansible и лучшее что можно сделать, то использовать какие-то договоренности, например внутри роли использовать только переменную описанные в этой роли.
BAD: использовать глобальную переменную.
# cat roles/some_role/tasks/main.yml --- debug: var: java_home
GOOD: В defaults определять необходимые переменные и позже использовать только их.
# cat roles/some_role/defaults/main.yml --- r__java_home: "{{ java_home | default('/path') }}" # cat roles/some_role/tasks/main.yml --- debug: var: r__java_home
Prefix role variables
BAD: использовать глобальную переменную.
# cat roles/some_role/defaults/main.yml --- db_port: 5432
GOOD: В роли для переменных использовать переменные с префиксом имени роли, это посмотрев на inventory позволит проще понять что происходит.
# cat roles/some_role/defaults/main.yml --- some_role__db_port: 5432
Use loop control variable
BAD: Использовать в циклах стандартную переменную item, если этот таск/плэйбук будет где-то заинклюдан то это может привести к непредвиденному поведению
--- - hosts: localhost tasks: - debug: msg: "{{ item }}" loop: - item1 - item2
GOOD: Переопределять переменную в цикле через loop_var.
--- - hosts: localhost tasks: - debug: msg: "{{ item_name }}" loop: - item1 - item2 loop_control: loop_var: item_name
Check input variables
Мы договорлись использовать префиксы переменных, не будет лишним проверить что они определены как мы ожидаем и, например, не были перекрыты пустым значением
GOOD: Проверять переменные.
- name: "Verify that required string variables are defined" assert: that: ahs_var is defined and ahs_var | length > 0 and ahs_var != None fail_msg: "{{ ahs_var }} needs to be set for the role to work " success_msg: "Required variables {{ ahs_var }} is defined" loop_control: loop_var: ahs_var with_items: - ahs_item1 - ahs_item2 - ahs_item3
Avoid hashes dictionaries, use flat structure
Если роль ожидает hash/dictionary в одному из параметров, то если мы захотим поправить один из дочерних параметров, нам надо будет переопределять весь hash/dictionary, что повысит сложность конфигурирования.
BAD: Использовать hash/dictionary.
--- user: name: admin group: admin
GOOD: Использовать плоскую структуру переменных.
--- user_name: admin user_group: "{{ user_name }}"
Create idempotent playbooks & roles
Роли и плэйбуки должны быть идемпотентными, т.к. уменьшает configuration drift и страх сломать что-то. Но если вы пользуете molecule, то это поведение по умолчанию.
Avoid using command shell modules
Использование shell модуля приводит к императивной парадигме описания, вместо декларативной, которая является основной Ansible.
Test your roles via molecule
Molecule позволяет весьма гибка штука, давай посмотрим несколько сценариев.
Molecule Multiple instances
В molecule.yml в секции platforms можно описать множество хостов которые разворачивать.
--- driver: name: docker platforms: - name: postgresql-instance hostname: postgresql-instance image: registry.example.com/postgres10:latest pre_build_image: true override_command: false network_mode: host - name: app-instance hostname: app-instance pre_build_image: true image: registry.example.com/docker_centos_ansible_tests network_mode: host
Соответственно эти хосты, можно потом в converge.yml использовать:
--- - name: Converge all hosts: all vars: ansible_user: root roles: - role: some_role - name: Converge db hosts: db-instance roles: - role: some_db_role - name: Converge app hosts: app-instance roles: - role: some_app_role
Ansible verifier
В molecule есть возможность использовать ansible Для проверки того, что инстанс был настроен правильно, более того это по умолчанию с 3 релиза. Это не так гибко как testinfra/inspec, но можно проверять, что содержимое файла соответствует нашим ожиданиям:
--- - name: Verify hosts: all tasks: - name: copy config copy: src: expected_standalone.conf dest: /root/wildfly/bin/standalone.conf mode: "0644" owner: root group: root register: config_copy_result - name: Certify that standalone.conf changed assert: that: not config_copy_result.changed
Или развернуть сервис, дождаться его доступности и сделать smoke test:
--- - name: Verify hosts: solr tasks: - command: /blah/solr/bin/solr start -s /solr_home -p 8983 -force - uri: url: http://127.0.0.1:8983/solr method: GET status_code: 200 register: uri_result until: uri_result is not failed retries: 12 delay: 10 - name: Post documents to solr command: /blah/solr/bin/post -c master /exampledocs/books.csv
Put complex logic into modules & plugins
Ansible проповедует декларативный подход, поэтому когда вы делаете ветвление кода, трансформацию данных, shell модули, то код становится сложно читаемым. Что бы побороться с этим и оставить его простым для понимания, не будет лишним, бороться с этой сложностью путём создания своих модулей.
Summarize Tips & Tricks
- Avoid global variables.
- Prefix role variables.
- Use loop control variable.
- Check input variables.
- Avoid hashes dictionaries, use flat structure.
- Create idempotent playbooks & roles.
- Avoid using command shell modules.
- Test your roles via molecule.
- Put complex logic into modules & plugins.
Заключение
Нельзя просто так взять и отрефакторить инфраструктуру на проекте, даже если у вас IaC. Это долгий процесс требующий терпения, времени и знаний.
Links
- Slides How to test Ansible and don't go nuts
- Video How to test Ansible and don't go nuts
- Что я узнал, протестировав 200 000 строк инфраструктурного кода
- Ansible: Миграция конфигурации 120 VM c Coreos на Centos за 18 месяцев
- Как наломать велосипедов поверх костылей при тестировании своего дистрибутива
- Протестируй меня если сможешь или мечтают ли YML программисты о тестирование ansible?
- A list of awesome IaC testing articles, speeches & links
- кросс пост
- English version
UPD1 2020.05.01 20:30 — Для первичного профилирования плэйбуков можно использовать callback_whitelist = profile_tasks что бы понять что именно долго работает. После чего проходимся по классике ускорения ansible. Можно попробовать mitogen
UPD2 2020.05.03 16:34 — English version
