
How to make a parallel book for language learning. Part 1. Python and Colab version
This is a second article on making parallel books. Today we will use the more advanced tool which will bring rich UI functionality. Lingtrain Alignment Studio is a web application written on Vue and Python. The main purpose of it is to extract the parallel corpora from two raw texts and make a bilingual (or even multilingual) parallel book. This is an open-source project and I will be glad to hear all of your bright ideas. Links to the sources and our community contacts can be found below. Los geht's!
Setup
The app is packed into the docker container. It's a simple technology to deploy your stuff anywhere from the server to your local machine. It's available across all the operating systems. So at first, you need a docker installed locally. Then you need to run two simple commands. The first will download the container:
docker pull lingtrain/aligner:v4
And the second one will run the application:
docker run -v C:\app\data:/app/data -v C:\app\img:/app/static/img -p 80:80 lingtrain/aligner:v4
C:\app\data and C:\app\img — your local folders.
The app will be available on the 80th port. Let's open the localhost page in your favorite browser.

We will make three simple steps: Load, Align, Create
Languages
You can choose the languages on the top menu. There are 16 languages are available now. The model itself does not consider such parameters as language because of the common dictionary between all of them. But the choice of it will add language-specific preprocessing which can be critical for the quality of alignment. If you didn't find the needed language try to choose English.
Prepare and load texts
After you choose the languages prepare the two text files for loading. If they have a header, quotes, title, and author you need to add some markup to these lines. The markup language is pretty simple and consists of a list of tags. These tags need to be added to the end of the line. Tagged lines will be extracted and not be considered during the alignment process. They will be useful when will generate the final book.
| Tag | Purpose | Mode |
|---|---|---|
| %%%%%title. | Title | Manual |
| %%%%%author. | Author | Manual |
| %%%%%h1. %%%%%h2. %%%%%h3. %%%%%h4. %%%%%h5. | Headings | Manual |
| %%%%%qtext. | Quote | Manual |
| %%%%%qname. | Text under the quote | Manual |
| %%%%%image. | Image | Manual |
| %%%%%translator. | Переводчик | Manual |
| %%%%%divider. | Divider | Manual |
| %%%%%. | New paragraph | Auto |
Look at the example below. After you add the tags your text files should be something like this:
Arkady and Boris Strugatsky%%%%%author. Monday Begins on Saturday%%%%%title. Fairy tale for primary scientists%%%%%h2. “But what is the strangest, the most incomprehensible of all, is the fact that authors can undertake such themes—I confess this is altogether beyond me, really… No, no, I don’t understand it at all.”%%%%%qtext. N.V. Gogol%%%%%qname. THE FIRST TALE. Run Around a Sofa%%%%%h1. https://habrastorage.org/webt/6l/cn/bc/6lcnbcgdqa6z1jdgfsibnvzxypm.png%%%%%image. Chapter 1%%%%%h2. Teacher: Children, write down the proposition: “The fish was sitting in a tree.”%%%%%qtext. Pupil: But is it true that fish sit in trees?%%%%%qtext. Teacher: Well… it was a crazy fish.%%%%%qtext. School Joke%%%%%qname. I was approaching my destination. All around, pressing up against the very edge of the road, the green of the forest yielded now and then to a meadow overgrown with yellow sedge. The sun had been setting for an hour and still couldn’t make it, hanging low on the horizon. The car rolled along, crunching on a gravel surface. I steered around the bigger rocks, and each maneuver caused the empty canisters to rattle and clang in the trunk. A couple of men came out of the woods on the right and stopped on the shoulder, looking in my direction. One of them raised his hand. I took my foot off the gas, scrutinizing the pair. They seemed to be hunters, young, and maybe a bit older than myself. Deciding I liked their looks, I stopped. The one who had raised his hand stuck his swarthy, hawk-nosed face through the window and asked, grinning, “Could you give us a lift to Solovetz?” ...
All tags except the author and title are optional. If you don't want to see headers and quotes in your book (or parallel corpora) simply remove all of these lines from your files.
Loaded texts will be split into sentences. You will see the lines and all of your markups in the following section. You also need to validate the count of the tags. The amount of them must be equal for loaded texts.

Align
On the second tab, we will choose the loaded documents and see how much the number of lines in the documents differs. If it's below 10% or so, then it's probably fine, because of the style of the exact translator or because of the specific language.
If the number of lines differs more than 10% you need to check that both texts are complete. In other words, there are no lost chapters or other parts.
So, choose the texts and create the alignment. After that will appear the settings of the newly created project — the number of batches, shift, and window.
Settings
Amount of batches. The alignment is an iterative process. Batches with a default size of 200 for the first text and proportionally amount of lines from the second one will be aligned together. You can run batch processing in parallel.
Window. You can adjust the overlap of the batches so that the correct options can be found by the alignment algorithm for sure.
Shift. If the number of sentences between texts differs too much in some area, then the correct options may not get into the window and the model will produce random matches. These breaks will be visible on the visualization and you can either enlarge the window or adjust the flow by shifting the second text forward or backward.
Visualization
After the initial alignment, a visualization panel will be shown. Here you can see how our model has worked.
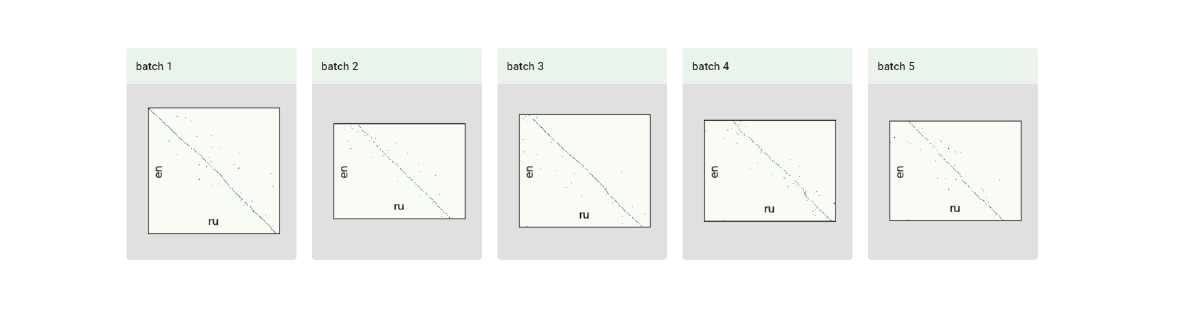
Conflicts
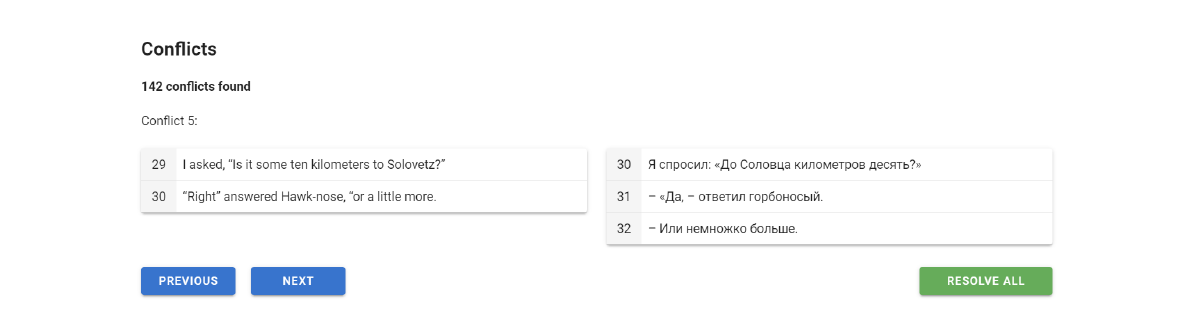
During the initial alignment, the model is selecting the best match for each sentence based on the embedding similarity. But since the number of options varies, there are conflicts that can be found in the corresponding section. After that, you can automatically resolve them.
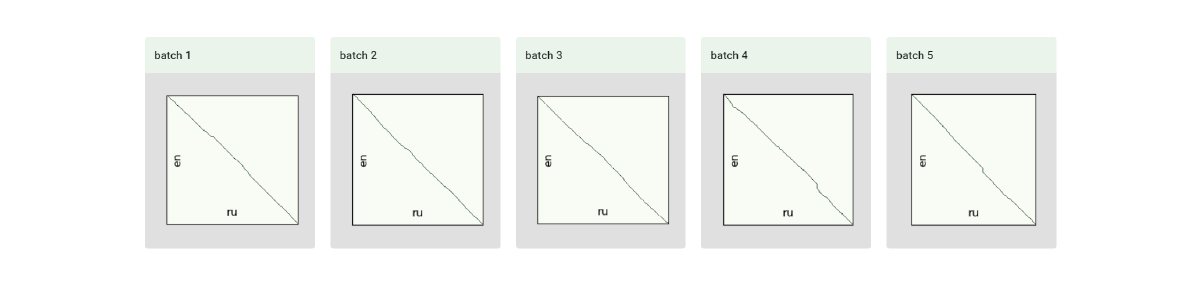
The visualization will also be updated.
Editor
The editor is the most complicated part of this application. Here you can edit a parallel corpus (this is what we did in the previous stages), add and delete lines, merge them together, and edit. At the same time, the row IDs are saved, which will allow us to keep the binding to the source lines. You can also resolve the conflicts by your hand in the editor if they haven't been resolved correctly. It may be at the ends of the alignment because the system focuses on good alignment chains, which may not be at the beginning and at the end.
Here is the editor:
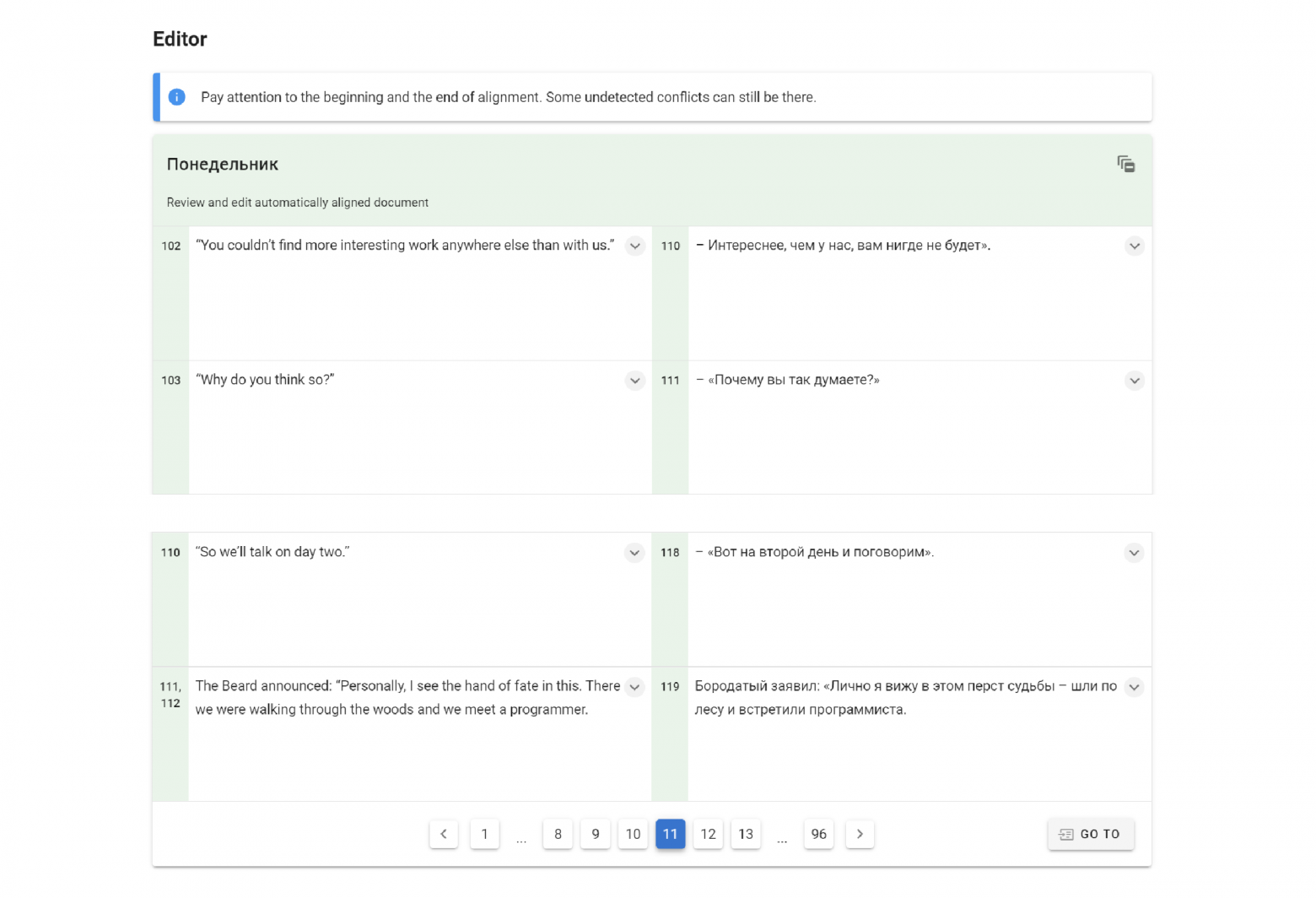
The action buttons appear when you hover over the cell.

You can add an existing row to a cell by selecting it from the list.

Subscript
In the case of working with languages in which you are not proficient, you can add a translation.

To do this, you need to download the text split by sentences, translate it and upload it back. To translate, you can use a life hack — open the text in the browser and translate it through the page translation function. Such a function is available in all modern browsers.
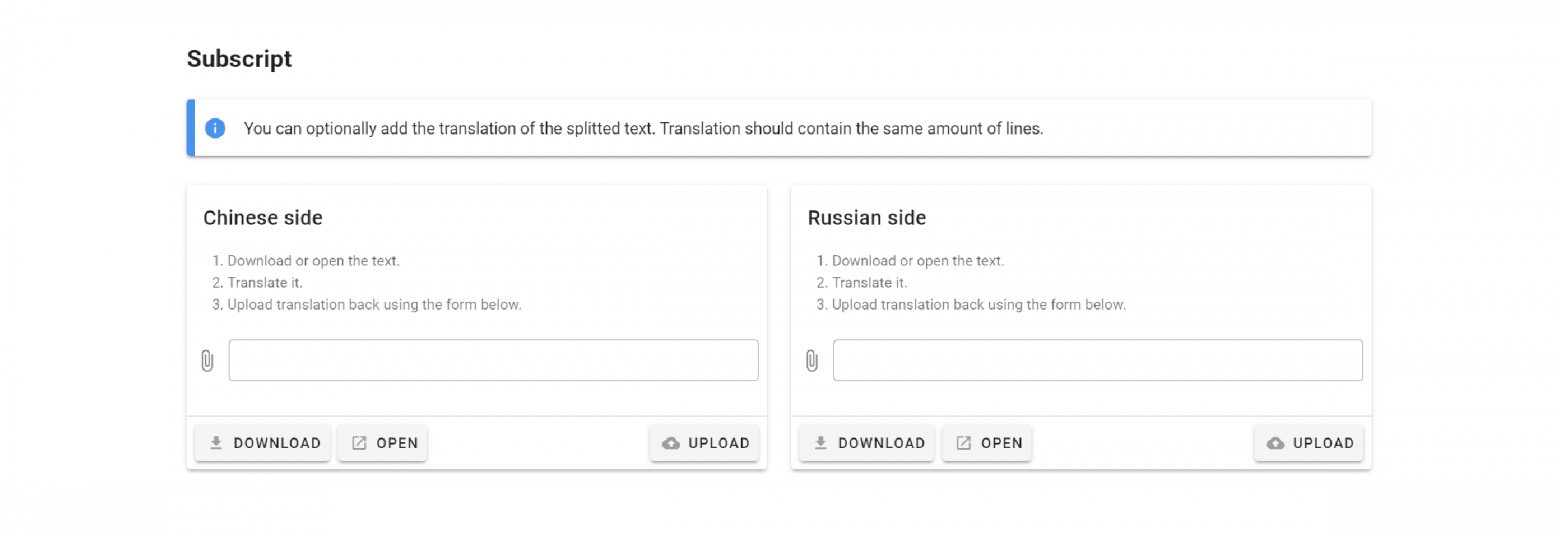
After the editing, you can start creating your book!
Create
With the alignment, you can either extract parallel corpora from it (useful for machine learning specialists and linguists) or create a book (for students, teachers, and other language fans).
Book
Before creating a stylized HTML book, you can customize it a little. Choose the side from with we will consider the information about the paragraph structure. Then choose the location of the texts — which one is on the left and which one is on the right. You can also add highlighting of matching sentences by selecting a style, it's my favorite feature.
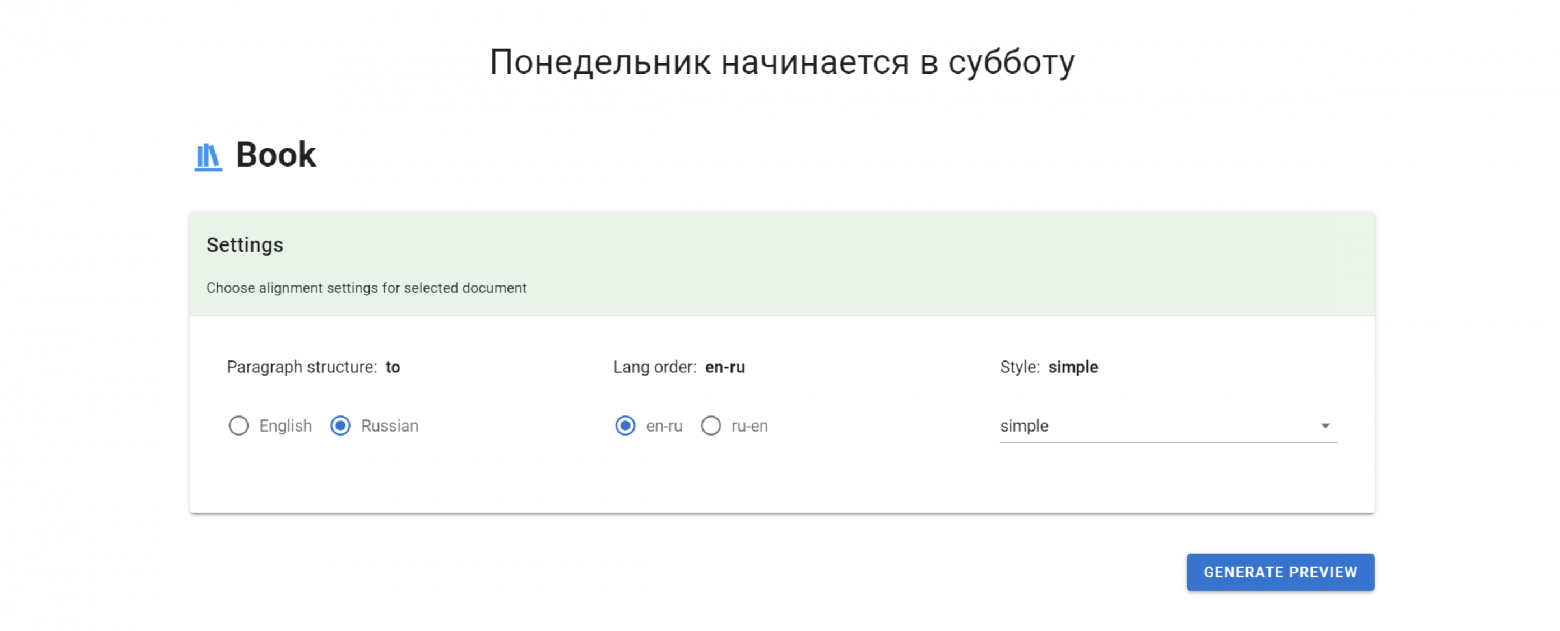
You can generate the beginning of the book right on the page. Stylized headings, separators, quotes, and so on will be created from the tags we have added. The plain text will be combined into paragraphs, according to the automatic markup.

Parallel corpora
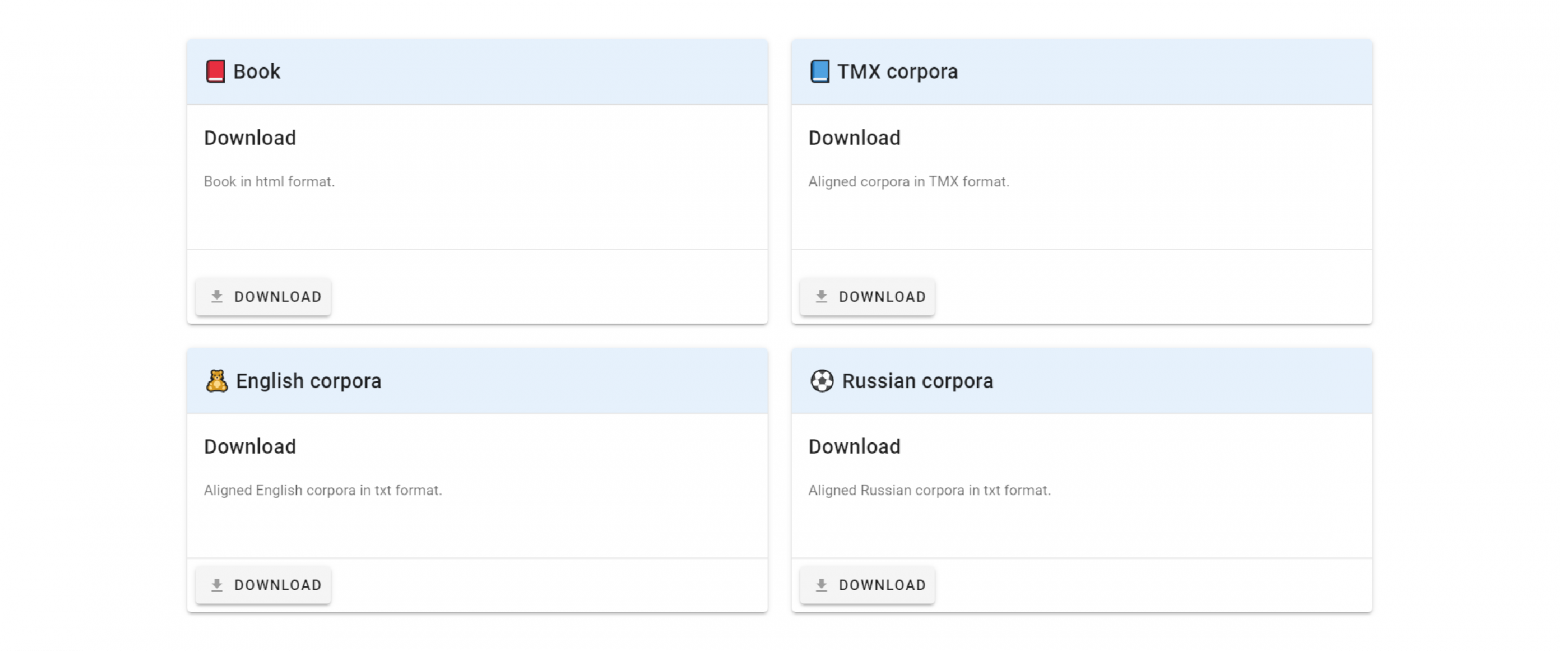
You can extract parallel texts either separately from the alignment as plain texts, or in the TMX format. The corpus can be used in teaching language models and other scientific and applied tasks.

Download
You can download the book and corpora in the final section.
Outro
It's hard to find a good bilingual book especially if your native language is not English. So it's important for me that any language learner will be able to create a parallel book easily. Now you can create it by yourself.
Parallel corpora also have great benefits. Feed it to your awesome neural translation and language models.
To be continued
- It is an open-source project. You can take a part in it and find the code on ours github page.
- Track the last news in our telegram channel — Lingtrain
You can also support the project by making a donation here.
May the Language Force be with you
