Comments 12
Я так и не понял, как используется векторное представление текста. На вход ResNet у нас подается картинка с шумом(или ее проекция во внутреннее пространство?), а как на ее обработку сеткой влияет этэншн и текстовый вектор?
Подмешивает в вектор картинки в латентном пространстве? А в резнет она потом перед подачей разворачивается обратнотв картинку?
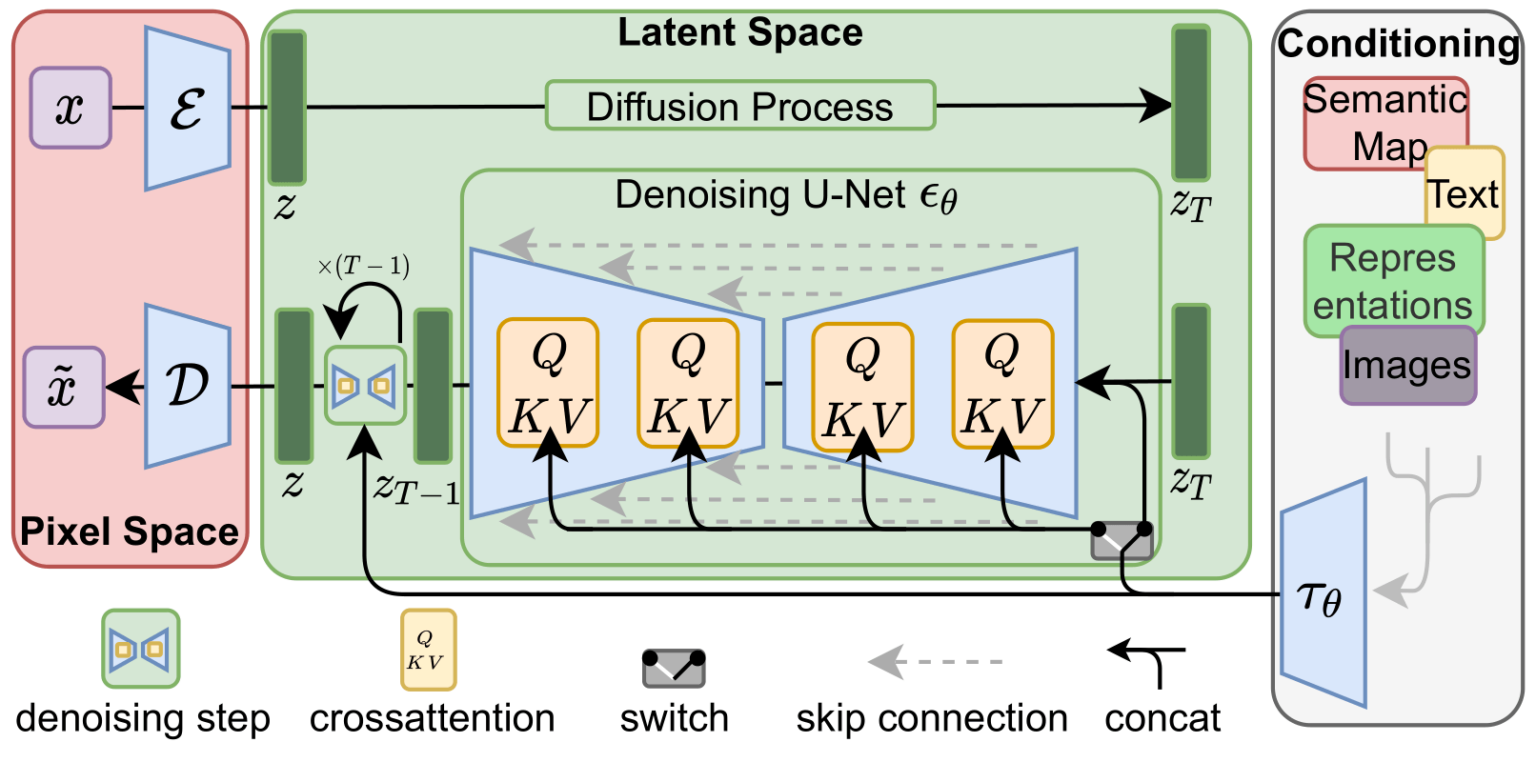
Там u-net для одномерных векторов используется? Не мог в это въехать, спасибо.
77 этт количество векторов из текстового описания, как я понимаю, а юнет вроде для картинок изначально, типа 512х512х3. Видимо этеншн подмешивает в латентное представление сумму из этих 77
Я не спорю, но в статье визуализация входа как матрица 3х3, что отсылает таки к стандартным методам обработки именно изображений. С ваших слов это матрица 77х[размерность датентного пространства] - мне кажется это не логично, и что скорее там тогда одномергый вектор, к которому как раз из 77 векторов текстового представления подмешивается новая информация. Хотелось бы этот момент прояснить.
я так понял, что сначала настраивается такой "удалитель шума", который получает из шума "внутреннего представления" картинки, близкие по тегам исходной картинке
\грубо говоря: "картинка кошки (зашумлятор) -> шум -> (расшумлятор) картинка кошки"\
а потом настраивается, чтобы этот удалитель шума + вектор слов умел делать картинки, в которых потом находятся эти слова
\слово "кошка" (шумлятор из слов в шум) -> шум -> (расшумлятор) картинка кошки\
как именно это делается - то ли вектор слов обучается создавать нужный шум (а он уже распаковывается в кошку в итоге), то ли "удалитель шума" обучается угадывать, что же ему загадал вектор слов - это я тоже не понял ....
UPD: да, и еще там получается, что "удалитель шума" не однопроходной, а итеративный, т.е.
картинка1 (зашумлятор) ->шум1-> (расшумлятор) картинка 2
картинка2 (зашумлятор) ->шум2-> (расшумлятор) картинка3
....
картинка99 (зашумлятор) -> шум99 -> (расшумлятор) картинка 100
при этом
а) "картинка 1" - это тупо шум (НЯЗ используется генератор шума перлина из сида)
б) с каждой итерацией шум на картинке уменьшается
в) "картинка 100" - это на самом деле уже "итоговая картинка без шума"
и поэтому
1) при добавлении вектора слов этот цикл превращается в что-то типа (тут я могу ошибваться)
картинка N (зашумлятор) + слова -> шум N -> (расшумлятор) картинка N+1
2) это позволяет делать "дорисовывание" - т.к. на каждой итерации меняется только та часть, которую дорисовывают (а ту часть рисунка которую не надо менять - не меняют :) )
после того, как эта сеть прогнозирования шума начнёт работать правильно, она, по сути, сможет рисовать картины, удаляя шум на протяжении множества шагов.
Слишком резкий скачок для понимания. (Почему удаление шума равно рисованию (новой?) картины?).
Как работает Stable Diffusion: объяснение в картинках