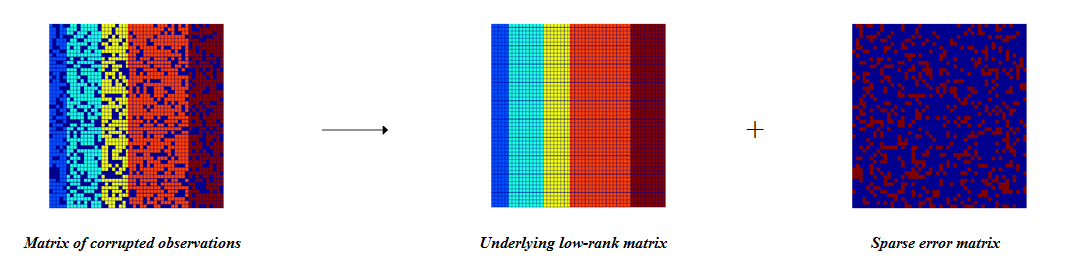
В связи с тематикой «Мегамозга» в своих статьях мы с вами несколько отошли от хардкорной IT тематики, но это не значит, что мы стали меньше этим интересоваться. Поэтому я решил разбавить сложившуюся атмосферу небольшой околонаучной статьей. Под катом будет несколько формул, прошу не пугаться.
В общем и целом это краткий перевод
статьи, размещенной на сайте
Корнелльского университета, с некоторыми моими вставками.
Аннотация

Интернет стал играть более важную роль в жизни людей с момента появления
Web 2.0. Взаимодействие между пользователями, дало им возможность свободно обмениваться информацией через социальные сети, форумы, блоги, википодобные сайты и другие интерактивные совместно разрабатываемые медиаресурсы.
С другой стороны, налицо все недостатки концепции второго веба. Контент-ориентированность стала самым важным плюсом и минусом сети одновременно. Вопросы надежности и достоверности информации в полный рост стоят перед владельцами и пользователями интерактивных сообществ. Как и в реальной жизни, в процессе общения через сеть иногда возникают ситуации, когда некоторые пользователи нарушают правила общепринятого
«сетевого» этикета. Фактически, чтобы сохранить нормальную атмосферу ресурса, владельцы вынуждены вводить искусственные правила взаимодействия и следить за их соблюдением.