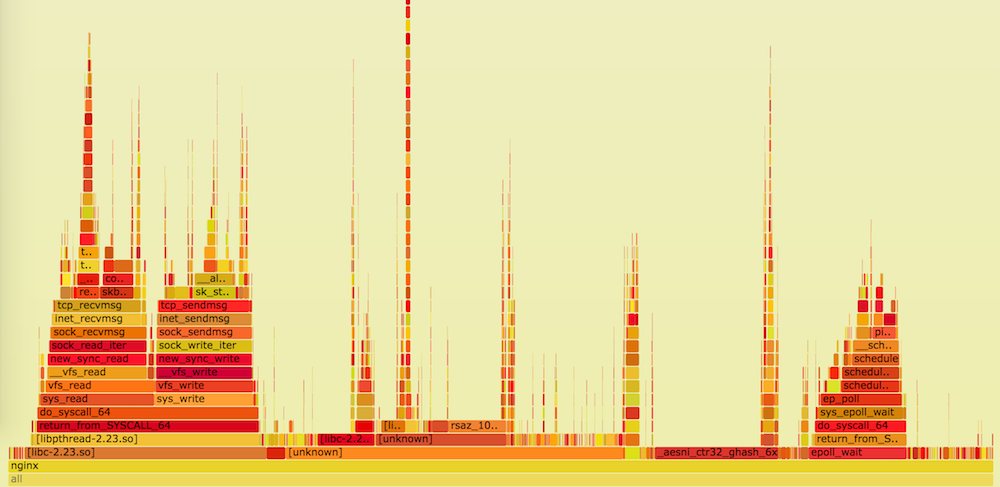
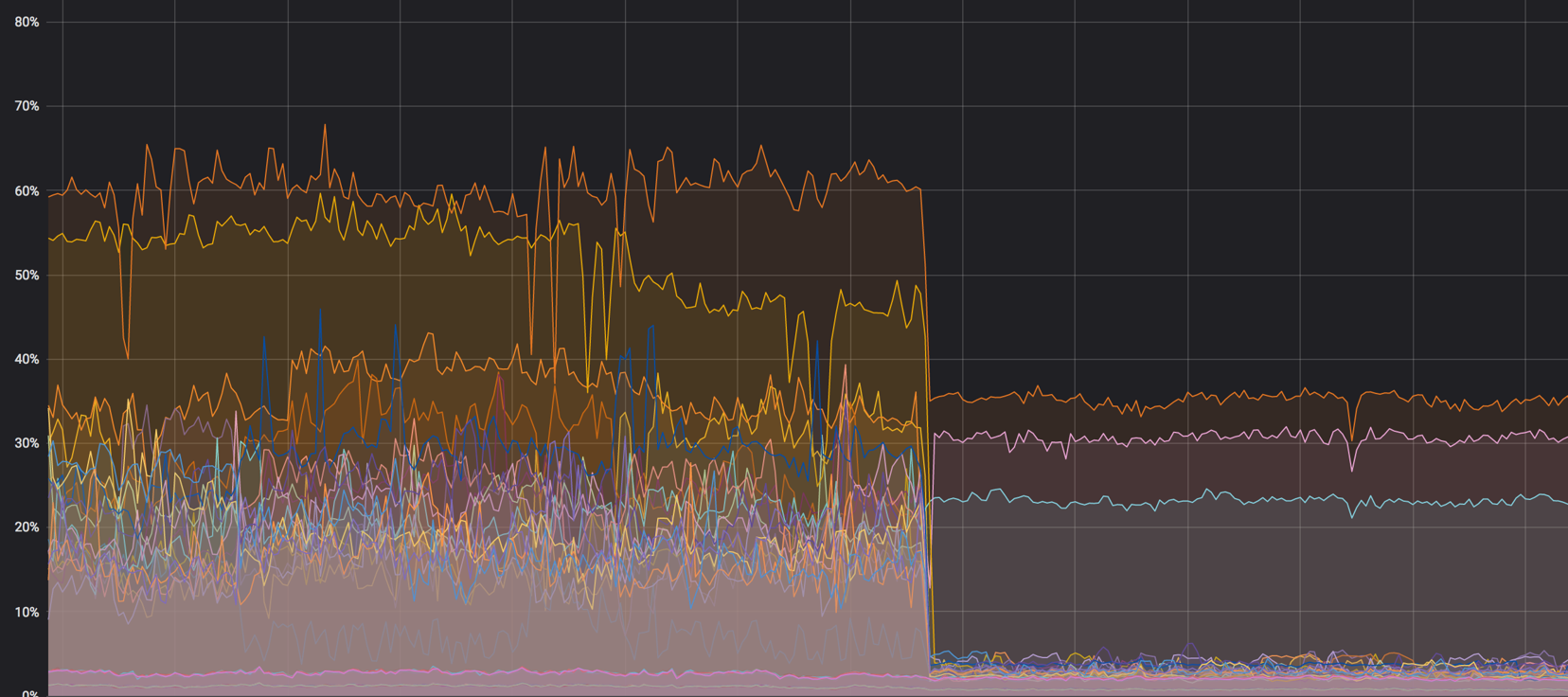
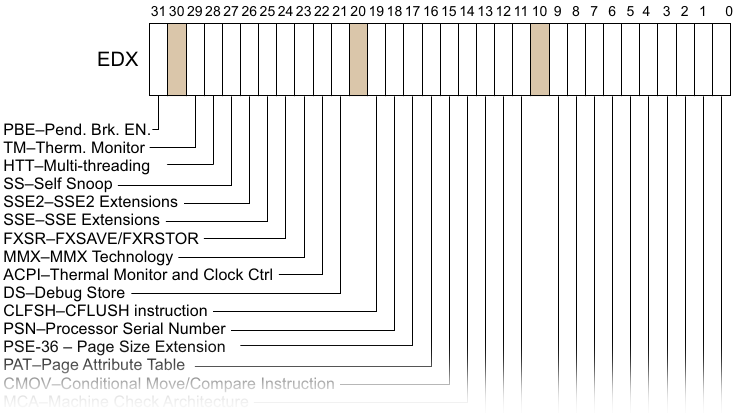
Однажды, на одном интервью меня спросили, что ты будешь делать, если обнаружишь неработающий сервис из-за того, что на диске закончилось место?
Конечно же я ответил, что посмотрю, чем занято это место и если возможно, то почищу место.
Тогда интервьюер спросил, а что если на разделе нет свободного места, но и файлов, которые бы занимали все место, ты тоже не видишь?
На это я сказал, что всегда можно посмотреть открытые файл дескрипторы, например командой lsof и понять какое приложение заняло все доступное место, а дальше можно действовать по обстоятельствам, в зависимости от того, нужны ли данные.
Интервьюер прервал меня на последнем слове, дополнив свой вопрос: «Предположим, что данные нам не нужны, это просто дебаг лог, но приложение не работает из-за того, что не может записать дебаг»?
«окей», — ответил я, «мы можем выключить дебаг в конфиге приложения и перезапустить его».
Интервьюер возразил: «Нет, приложение мы перезапустить не можем, у нас в памяти все еще хранятся важные данные, а к самому сервису подключены важные клиенты, которых мы не можем заставлять переподключаться заново».
«ну хорошо», сказал я, «если мы не можем перезапускать приложение и данные нам не важны, то мы можем просто очистить этот открытый файл через файл дескриптор, даже если мы его не видим в команде ls на файловой системе».
Интервьюер остался доволен, а я нет.
Тогда я подумал, почему человек, проверяющий мои знания, не копает глубже? А что, если данные все-таки важны? Что если мы не можем перезапускать процесс, и при этом этот процесс пишет на файловую систему в раздел, на котором нет свободного места? Что если мы не можем потерять не только уже записанные данные, но и те данные, что этот процесс пишет или пытается записать?









 От переводчика
От переводчика