
Обработка данных и применение основных видов регрессий для решения задач на Kaggle, на примере соревнования "Предсказание оттока пользователей" от DeepLearningSchool МФТИ.

Инженер
Обработка данных и применение основных видов регрессий для решения задач на Kaggle, на примере соревнования "Предсказание оттока пользователей" от DeepLearningSchool МФТИ.

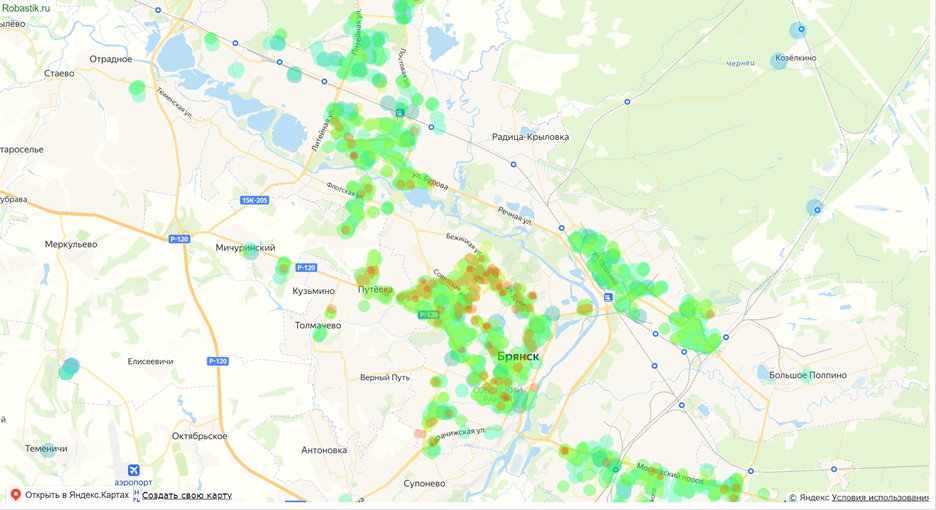
В продолжение рассказов о Big Data для простых смертных предлагаем попробовать себя в решении жилищного вопроса: как отличаются цены за квадратный метр на разных этажах. Житейская польза от этой заметки заключается в получении без особых усилий и без специальных навыков достоверных знаний об ожиданиях на рынке недвижимости. Государство скрывает цены реальных сделок, но иметь адекватное представление о настроениях продавцов можно и без знакомого опытного риелтора, сына маминой подруги.
Статья представляет собой пошаговую иллюстрированную инструкцию по решению задачи анализа этажности городской застройки, в т.ч. расчет скидок за первый и последний этажи. В качестве модельного города принят Брянск. Расчетный файл прилагается и его листы пронумерованы в последовательности выполненных операций. Шаблон расчета легко адаптировать для другого города и вида недвижимости.
Изложенный подход призван аргументировать представление о том, что Big Data не является прерогативой дата сатанистов, но в известной степени доступен неспециалистам. Материал может быть интересен всем, кроме работающих с данными профессионально. Приведенные приемы будут востребованы в работе с данными для риелторов и оценщиков без навыков программирования. Технохардкор в данном случае заключается не в инсайтах применения фреймворков типа MapReduce, а в реализации всего пайплайна средствами общеизвестного офисного приложения.
Инструкция состоит из двух частей. В первой части изложен порядок подготовки, первичного ознакомления с данными и уточнения цели исследования. Во второй части будет сделан расчет скидки за этаж.

После начала работы космической обсерватории «Джеймса Уэбба» астрофотографии вошли в тренды. Самое крутое что сейчас можно запечатлеть находится в космосе. История помнит только два случая, когда умные парни становились популярными. Первый - изобретение кубика Рубика в 1973 году сделало королями дискотеки знатоков теории групп. Второй - астрономы любители покоряют социальные сети прямо сейчас.
Но если вам в детстве не дарили телескопы на каждый день рождения, а заглянуть в тайны космоса хочется, придется выбрать стартовый набор астрофотографа с минимальным порогом вхождения. Рассмотрим четыре варианта начальных наборов юного (по уму) астронома.

Всем привет, меня зовут Вячеслав Зотов, я аналитик в студии Whalekit. В этом тексте я расскажу про статистические тесты и сравнение воронок, а также мы попробуем разобраться, что объединяет χ²-тесты, какова область их применения и подробно исследуем применимость χ²-тестов к анализу воронок. И все это с примерами на Python.
Тест χ² — очень полезный аналитический инструмент, который тем не менее часто вызывает у аналитиков недопонимание и путаницу. Прежде всего это происходит из-за того, что существует целое семейство тестов χ², имеющих разные области применения. Дополнительную путаницу создает то, что тесты χ² часто рекомендуют применять для анализа продуктовых и маркетинговых воронок, а это обычно приводит к ошибочному использованию тестов.

Все чаще объектами статистического анализа становятся не массивы (таблицы) значений, а временные ряды. Такие ряды формируются при наблюдениях за природными процессами и явлениями, изучении социологических или макроэкономических показателей, при промышленном производстве и сбыте продукции. Главное, что отличает временной ряд от других типов данных – это то, что номер (время) наблюдения имеет значение. То есть, важен не только результат измерения, но и тот момент времени, когда оно выполнено. К сожалению, при применении статистических методов на этот нюанс часто не обращают внимания. Однако, именно эта "мелочь" приводит к очень серьезным и нетривиальным следствиям с точки зрения обработки таких сигналов. Самые обычные формулы, описанные во всех учебниках, внезапно отказываются работать. А попытки их применения "в лоб" иногда дают, мягко говоря, весьма неожиданные результаты. Например, статистическая связь между числом пиратов и глобальным потеплением оказывается не просто "значимой", а "практически достоверной". Что удивительно, столкнувшись с такой ситуацией, даже достаточно грамотные исследователи не всегда понимают, где же тут "порылась собака" . Данные вроде бы правильные, математика (как и жена Цезаря) – точно вне подозрений. А результат – ни в какие ворота... А Вы твердо уверены, что всегда правильно оцениваете значимость таких корреляций?
Считается, что Data Mining — это магическое снадобье из SQL, Python, Power BI и других волшебных компонент. Мало кто знает, что при правильном подходе с Data Mining может совладать офисный планктон с помощью одного лишь Excel.
Если вы абсолютно далеки от Data Mining, но хотите причаститься его таинств, это руководство в картинках по шагам сделано для вас. Особенно полезно тем, кто никогда бы даже не подумал сделать подобное самостоятельно.
Если вы владеете специальными инструментами для работы с данными, то будет интересно узнать ваше мнение о решениях без "рокет сайнс" (как о явлении в целом, так и о данном кейсе).

*фарм — (от англ. farming) — долгое и занудное повторение определенных игровых действий с определенной целью (получение опыта, добыча ресурсов и др.).
Недавно (1 октября) стартовала новая сессия прекрасного курса по DS/ML (очень рекомендую в качестве начального курса всем, кто хочет, как это теперь называется, "войти" в DS). И, как обычно, после окончания любого курса у выпускников возникает вопрос — а где теперь получить практический опыт, чтобы закрепить пока еще сырые теоретические знания. Если вы зададите этот вопрос на любом профильном форуме, то ответ, скорее всего, будет один — иди решай Kaggle. Kaggle — это да, но с чего начать и как наиболее эффективно использовать эту платформу для прокачки практических навыков? В данной статье автор постарается на своем опыте дать ответы на эти вопросы, а также описать расположение основных грабель на поле соревновательного DS, чтобы ускорить процесс прокачки и получать от этого фан.


Узнал я о линейной регрессии после того, как встретил деревья, нейронные сети. Когда мы с другом повторно изобретали велосипед, обучая с нуля word2vec и использовали логистическую регрессию с векторами из обученной модели для задачи NER – я активно кричал о том, что линейная регрессия – прошлый век, никому она уже совсем не нужна.
Да, проблема была в том, что я совсем не разобрался в вопросе и полез в бой. Но практику в универе нужно было как-то закрывать.
После семестра мат. статистики ко мне пришло прозрение.