Сбалансированное дерево поиска является фундаментом для многих современных алгоритмов. На страницах книг по Computer Science вы найдете описания красно-черных, AVL-, B- и многих других сбалансированных деревьев. Но является ли перманентная сбалансированность тем Святым Граалем, за которым следует гоняться?
Представим, что мы уже построили дерево на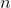 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 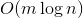 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 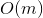 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
Сегодня я расскажу о splay-деревьях. Эти деревья не являются перманентно сбалансированными и на отдельных запросах могут работать даже линейное время. Однако, после каждого запроса они меняют свою структуру, что позволяет очень эффективно обрабатывать часто повторяющиеся запросы. Более того, амортизационная стоимость обработки одного запроса у них , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
Представим, что мы уже построили дерево на
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то запросов могут отнять времени. Здравый смысл подсказывает, что оценку можно оптимизировать до , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.Сегодня я расскажу о splay-деревьях. Эти деревья не являются перманентно сбалансированными и на отдельных запросах могут работать даже линейное время. Однако, после каждого запроса они меняют свою структуру, что позволяет очень эффективно обрабатывать часто повторяющиеся запросы. Более того, амортизационная стоимость обработки одного запроса у них
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев. В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.