
Как только я заинтересовался lock-free алгоритмами, меня стал мучить вопрос – а откуда взялась необходимость в барьерах памяти, в «наведении порядка» в коде?
Конечно, прочитав несколько тысяч страниц руководств по конкретной архитектуре, мы найдем ответ. Но этот ответ будет годен для этой конкретной архитектуры. Есть ли общий? В конце концов, мы же хотим, чтобы наш код был портабелен. Да и модель памяти C++11 не заточена под конкретный процессор.
Наиболее приемлемый общий ответ дал мне мистер Paul McKenney в своей статье 2010 года Memory Barriers: a Hardware View of Software Hackers. Ценность его статьи – в общности: он построил некоторую упрощенную абстрактную архитектуру, на примере которой и разбирает, что такое барьер памяти и зачем он был введен.
Вообще, Paul McKenney – известная личность. Он является разработчиком и активным пропагандистом технологии RCU, которая активно используется в ядре Linux, а также реализована в последней версии libcds в качестве ещё одного подхода к безопасному освобождению памяти (вообще, о RCU я хотел бы рассказать отдельно). Также принимал участие в работе над моделью памяти C++11.
Статья большая, я даю перевод только первой половины. Я позволил себе добавить некоторые комментарии, [которые выделены в тексте так].
Memory Barriers: a Hardware View of Software Hackers
Что подвигло дизайнеров CPU ввести барьеры памяти и тем самым подложить свинью разработчикам? Короткий ответ таков: переупорядочение обращений к памяти позволяет достичь лучшей производительности, а барьеры памяти нужны для «наведения порядка» в вещах типа примитивов синхронизации [и lock-free алгоритмов, естественно], где корректность примитива зависит как раз от порядка обращений к памяти.
Детальный ответ требует хорошего понимания того, как работает кэш CPU, и что требуется для ещё лучшей его работы. Поэтому далее мы:
- рассмотрим структуру кэша;
- опишем, как протокол когерентности кэша обеспечивает видимость каждой ячейки памяти для разных процессоров;
- рассмотрим, как буферы записи (store buffers) и очереди инвалидаций (invalidate queues) помогают кэшу достичь максимальной производительности.
Мы увидим, что барьеры памяти есть необходимое зло, требующееся для достижения высокой производительности и масштабируемости. Корнем этого зла является тот факт, что CPU на порядки быстрее, чем память и интерфейс процессора с памятью.
Структура кэша
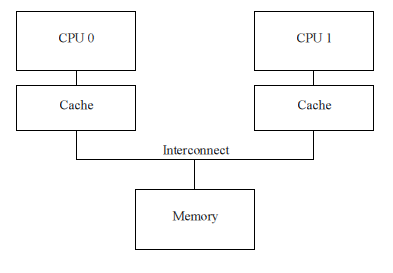
Современные CPU намного быстрее подсистемы памяти. Процессор образца 2006 года мог выполнять 10 инструкций в наносекунду, но требовалось много десятков наносекунд для извлечения данных из основной памяти. Эта диспропорция в скорости (более чем на два порядка!) привела к многомегабайтным кэшам у современных процессоров. Кэши принадлежат процессорам и, как правило, время доступа к ним — несколько тактов.
Примечание
На самом деле, устоявшейся практикой является наличие нескольких уровней кэша. Самый маленький по объему кэш находится ближе всего к процессору и доступен за один такт. Кеш второго уровня имеет время доступа порядка 10 тактов. Наиболее производительные процессоры имеют 3 и даже 4 уровня кэшей
CPU обменивается данными с кэшем блоками, называемыми кэш-линиями (cache line), размер которых обычно является степенью двойки – от 16 до 256 байт (зависит от CPU). Когда к ячейке памяти впервые обращается процессор, ячейка отсутствует в кэше, — эта ситуация называется промахом (cache miss или, более точно, “startup” или “warmup” cache miss). Промах означает, что CPU должен ждать (stalled) сотни тактов, пока данные не будут извлечены из памяти. Наконец данные будут загружены в кэш, и последующие обращения по данному адресу найдут данные в кэше, так что CPU будет работать на полной скорости.
Спустя некоторое время кэш заполнится, и промахи будут приводить к вытеснению данных из кэша, чтобы дать место новым запрашиваемым данным. Такие промахи называются промахами по переполнению (capacity miss). Более того, вытеснение может произойти даже тогда, когда кэш не полон, так как он организован в железе в виде хеш-таблицы с фиксированным размером bucket’а (или набора, как его зовут разработчики CPU).
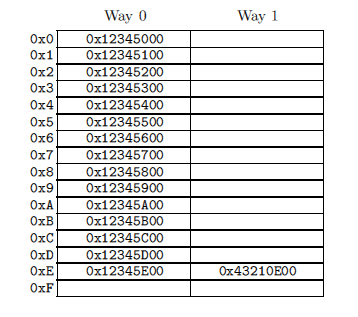
На рисунке справа представлен 2-ассоциативный (2-way) кэш с cache line размером 256 байт. Линия может быть пустой, что соответствует пустой ячейке таблицы. Числа слева – это адреса, данные которых может содержать ячейка. Так как линии выравнены по 256 байтам, младшие 8 бит адреса равны нулю, и хеш-функция выбирает следующие 4 бита в качестве индекса в хеш-таблице. Предположим, код программы расположен по адресам 0x43210E00 – 0x43210EFF, а сама программа последовательно обращается к данным по адресам 0x12345000 – 0x12345EFF. Пусть теперь она обращается к адресу 0x12345F00. Этот адрес хешируется на линию 0xF и обе ячейки (ways) этой линии пусты, так что 256 байт данных можно поместить в одну из них. Если программа обращается по адресу 0x1233000, хеш которой равен 0x0, то соответствующие 256-байтные данные могут быть помещены в ячейку 1 (way 1) линии 0x0. Если же программа обращается по адресу 0x1233E00 (хеш = 0xE), то одна из линий (ways) должна быть вытолкнута из кэша, чтобы освободить место под новые 256 байт данных. Если позже потребуется доступ к этим вытолкнутым данным, — получаем ситуацию промаха. Такой промах называется associativity miss.
Все это относится к чтению данных, а что будет при записи? Все CPU должны быть согласованы по данным, так что перед тем как записать, нужно удалить (invalidate) данные из кэшей других CPU. Только после того, как инвалидация завершится, процессор может безопасно записать данные. Если данные находятся в кэше CPU, но являются read-only, это называется промахом записи (write miss). Только после того, как CPU инвалидирует такие данные в кэшах других процессоров, CPU может повторно записать (и прочитать) эти данные. Далее, если какой-то CPU попытается обратиться к данным в то время, как другой CPU их инвалидировал для записи, — он получит промах, зовущийся communication miss, так как такая ситуация возникает, когда данные используются для взаимодействия (communication), как, например, мьютекс или spin-lock [имеется в виду сам мьютекс, а не данные, которые он защищает; мьютекс – это какой-то флаг].
Как видно, большие усилия должны быть приложены для того, чтобы управлять когерентностью данных для всех CPU. Со всеми этими чтением/инвалидацией/записью легко вообразить, что данные будут потеряны или (что ещё хуже) у разных CPU будут разные данные в их кэшах. Эти проблемы решает протокол когерентности данных (cache-coherency protocol)
Cache coherency protocol
Протокол управляет состоянием линий кэша, обеспечивая целостность и запрещая потерю данных. Такие протоколы могут быть очень сложными, с десятками состояний, но для наших целей достаточно рассмотреть протокол MESI, имеющий 4 состояния.
Состояния MESI
MESI – это 4 возможных состояния кэш-линии: Modified-Exclusive-Shared-Invalid. Для поддержки этого протокола каждая линия, помимо собственно данных, должна иметь двухбитовый тег, хранящий её состояние.
Состояние Modified означает, что данные в кэш-линии только что записаны процессором-владельцем кэша, и гарантируется, что изменение ещё не появилось в кэшах других CPU. Можно сказать, что данными владеет один CPU. Так как данные в такой линии свежайшие, линия кэша готова к записи в память (или в кэш следующего уровня), и запись должна быть произведена прежде, чем линию можно будет заполнить другими данными.
Состояние Exclusive весьма похоже на Modified, за исключением того, что данные ещё не изменены процессором-владельцем кэша. Это, в свою очередь, означает, что линия содержит наисвежайшие данные, согласованные с памятью. CPU-владелец может писать в эту кэш-линию в любое время без оповещения других CPU, равно как и вытеснить её без какой-либо записи обратно в память.
Состояние Shared говорит, что линия продублирована по крайней мере в ещё одном кэше другого CPU. CPU-владелец такой линии не может писать в неё без предварительного согласования с другими CPU. Как и для состояния Exclusive, линия согласована с памятью, и может быть вытеснена без оповещения других CPU и без записи обратно в память.
Линия кэша в состоянии Invalid пуста, то есть не содержит никаких данных (или содержит мусор). Когда в кэш требуется подгрузить новые данные, они по возможности помещаются в Invalid-линию.
Так как все CPU должны поддерживать когерентность кэшей системы в целом, протокол описывает сообщения, с помощью которых координируются изменения состояния линий кэша всех процессоров.
Сообщения протокола MESI
Многие из переходов из одного состояния в другое требуют взаимодействия между CPU. Если все CPU подсоединены к единой разделяемой шине, достаточно следующих сообщений:
- Read (Чтение): это сообщение содержит физический адрес читаемой кэш-линии
- Read Response (Ответ на чтение): содержит данные, запрошенные предыдущим сообщением Read. Read Response может прийти от подсистемы памяти или от другого кэша. Например, если данные уже находятся в каком-либо кэше в состоянии “modified”, то такой кэш может ответить на Read
- Invalidate (Инвалидация): содержит физический адрес кэш-линии, которую требуется инвалидировать. Все прочие кэши должны удалить данные и ответить на это сообщение.
- Invalidate Acknowledge (Подтверждение инвалидации): CPU, получивший Invalidate, должен удалить требуемые данные и подтвердить это сообщением Invalidate Acknowledge
- Read Invalidate (Чтение с инвалидацией): это сообщение содержит физический адрес читаемой кэш-линии. В то же время оно диктует другим кэшам удалить эти данные. По сути, это комбинация сообщений Read и Invalidate. Это сообщение требует ответа Read Response и множества Invalidate Acknowledge
- Writeback (Запись в память): содержит адрес и собственно данные для записи в память. Разрешает кэшам очистить соответствующую линию в состоянии Modified
Как видите, мультипроцессорная машина – это система передачи сообщений, по сути компьютер под крышкой процессора.
Вопрос-ответ
Что произойдет, если два процессора будут инвалидировать одну и ту же кэш-линию одновременно?
Один из них (“победитель”) получит доступ к разделяемой шине первым. Другие CPU должны инвалидировать свои копии этой кэш-линии и ответить подтверждением “invalidate acknowledge”. Конечно, “проигравший” CPU может тут же инициировать транзакцию “read invalidate”, так что победа может оказаться эфемерной.
Если сообщение “invalidate” появится в большой многопроцессорной системе, все CPU должны ответить “invalidate acknowledge”. Не приведет ли взрывной поток таких ответов к полной остановке системы?
Да, может привести, если большая (large-scale) система построена таким образом. Но такие системы, как, например, NUMA, обычно используют directory-based [directory в NUMA – узел, node] протокол поддержки когерентности кэшей как раз для предотвращения таких случаев.
Один из них (“победитель”) получит доступ к разделяемой шине первым. Другие CPU должны инвалидировать свои копии этой кэш-линии и ответить подтверждением “invalidate acknowledge”. Конечно, “проигравший” CPU может тут же инициировать транзакцию “read invalidate”, так что победа может оказаться эфемерной.
Если сообщение “invalidate” появится в большой многопроцессорной системе, все CPU должны ответить “invalidate acknowledge”. Не приведет ли взрывной поток таких ответов к полной остановке системы?
Да, может привести, если большая (large-scale) система построена таким образом. Но такие системы, как, например, NUMA, обычно используют directory-based [directory в NUMA – узел, node] протокол поддержки когерентности кэшей как раз для предотвращения таких случаев.
Диаграмма состояний MESI

Переходы на рисунке справа имеют следующее значение:
- Переход a (M -> E): Кэш-линия записана обратно в память, но CPU оставил её в кэше и имеет право изменять её. Этот переход требует сообщения “writeback”.
- Переход b (E -> M): CPU пишет в кэш-линию, к которой имеет эксклюзивный доступ. Этот переход не требует каких-либо сообщений.
- Переход c (M -> I): CPU получает сообщение “read invalidate” кэш-линии в состоянии “Modified”. CPU должен удалить свою локальную копию и ответить сообщениями “read response” и “invalidate acknowledge”. Тем самым CPU отправляет данные и показывает, что более не имеет их копии у себя
- Переход d (I -> M): CPU производит read-modify-write (RMW) операцию над данными, не находящимися в кэше. Он издает “read invalidate” сигнал, получая данные в “read response”. CPU завершает переход только когда получит все ответы “invalidate acknowledge”
- Переход e (S -> M): CPU производит read-modify-write (RMW) операцию над данными, которые были read-only. Он должен инициировать “invalidate” сигнал и ждать, пока не получит полный набор ответов “invalidate acknowledge”
- Переход f (M -> S): Какой-то другой процессор читает данные, и эти данные находятся в кэше нашего CPU. В результате данные становятся read-only, что может привести к записи в память. Этот переход инициируется приемом сигнала “read”. CPU отвечает сообщением “read response”, содержащим запрашиваемые данные
- Переход g (E -> S): Какой-то другой процессор читает данные, и эти данные находятся в кэше нашего CPU. Данные становятся разделяемыми и, следовательно, read-only. Переход инициируется приемом сигнала “read”. CPU отвечает сообщением “read response”, содержащим запрашиваемые данные
- Переход h (S -> E): CPU решает, что ему надо записать данные в кэш-линию, и поэтому посылает “invalidate” сообщение. Переход не завершается, пока CPU не получит полный набор ответов “invalidate acknowledge”. Другие CPU выкидывают кэш-линию из своих кэшей сообщением “writeback”, так что наш CPU становится единственным, кэширующим эти данные
- Переход i (E -> I): Другой CPU выполняет RMW-операцию с данными, которыми владеет наш CPU, так что наш процессор инвалидирует кэш-линию. Переход начинается с сообщения “read invalidate”, наш CPU отвечает сообщениями “read response” и “invalidate acknowledge”.
- Переход j (I -> E): CPU сохраняет данные в новую кэш-линию и передает сообщение “read invalidate”. CPU не может закончить переход, пока не получит “read response” и полный набор “invalidate acknowledge”. Как только запись завершится, кэш-линия переходит в состояние “modified” через переход (b)
- Переход k (I -> S): CPU загружает данные в новую кэш-линию. CPU посылает “read”-сообщение и завершает переход, получив “read response”
- Переход l (S -> I): Другой CPU хочет сохранить данные в кэш-линию, которая имеет статус read-only, так как какой-то третий CPU (или, например, наш) разделяет данные с нами. Переход начинается приемом “invalidate”, и наш CPU отвечает “invalidate acknowledge”
Вопрос-ответ
Как железо обрабатывает такие тяжелые переходы, требующие многочисленных задержек?
Обычно – введением дополнительных состояний. Но такие состояния не требуется сохранять в кэш-линиях, то есть они не являются состояниями кэш-линии. В каждый момент времени только несколько кэш-линий могут находиться в переходном состоянии. Именно наличие тяжелых, распределенных во времени переходов является причиной того, что реальные протоколы поддержки когерентности кэша намного сложнее, чем упрощенный MESI, описываемый здесь.
Обычно – введением дополнительных состояний. Но такие состояния не требуется сохранять в кэш-линиях, то есть они не являются состояниями кэш-линии. В каждый момент времени только несколько кэш-линий могут находиться в переходном состоянии. Именно наличие тяжелых, распределенных во времени переходов является причиной того, что реальные протоколы поддержки когерентности кэша намного сложнее, чем упрощенный MESI, описываемый здесь.
Пример протокола MESI
Давайте посмотрим, как работает MESI с точки зрения кэш-линии, на примере 4-процессороной системы с прямым отображением памяти в кэш. Данные находятся в памяти по адресу 0. Следующая таблица иллюстрирует изменение данных. Первая колонка – это последовательный номер операции, вторая – номер процессора, выполняющего операцию, третья – какая операция выполняется, следующие четыре колонки – состояние кэш-линии каждого CPU (в виде адрес памяти/состояние), заключительные две колонки – содержит ли память корректные данные (V) или нет (I).
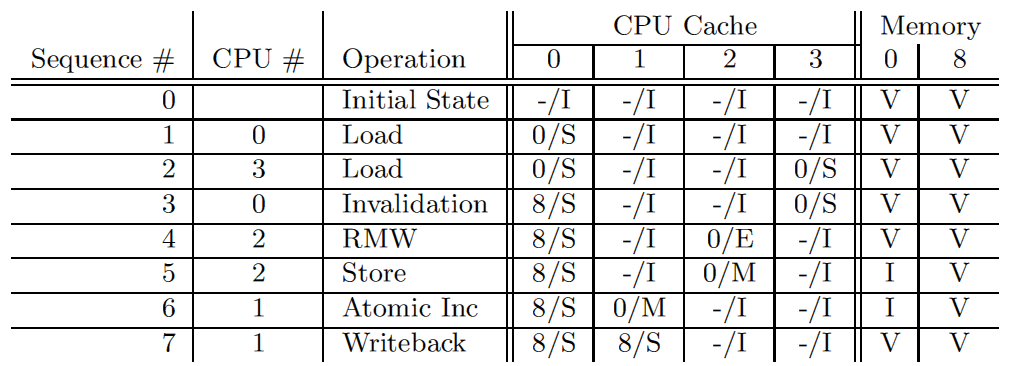
Сначала линии кэша CPU находятся в состоянии “invalid”, а память содержит корректные данные. Когда CPU 0 читает данные по адресу 0, кэш-линия CPU 0 переходит в состояние “shared” и согласована с памятью. CPU 3 также читает данные по адресу 0, так что кэш-линии переходят в состояние “shared” в кэшах обоих CPU, но по-прежнему согласованы с памятью. Далее CPU 0 загружает данные по адресу 8, что приводит к вытеснению кэш-линии и помещению в неё новых данных (прочитанных по адресу 8). Далее, CPU 2 читает данные по адресу 0, но затем понимает, что ему необходимо записать их (RMW-операция), так что он использует сигнал “read invalidate”, чтобы убедиться, что он имеет эксклюзивную копию данных. Сигнал “read invalidate” инвалидирует кэш-линию CPU 3 (хотя его данные пока остаются согласованными с памятью). Затем CPU 2 выполняет запись, являющуюся составной частью RMW-операции, что переводит кэш-линию в состояние “Modified”. Данные в памяти теперь устаревшие. CPU 1 выполняет атомарный инкремент и использует сигнал “read invalidate”, чтобы получить данные. Данные он получает из кэша CPU 2, а в самом CPU 2 данные инвалидируются. В результате данные находятся в кэш-линии CPU 1 в состоянии “modified” и по-прежнему не согласованы с памятью. Наконец, CPU 1 читает данные по адресу 8, что приводит к сбросу кэш-линии в память (используется сообщение “writeback”).
”Вопрос-ответ”
Кэш содержит некоторые данные, когда мы остановили наш пример. А какая последовательность операций должна быть, чтобы перевести линии кэша всех CPU в состояние “invalidate”?
Такой последовательности не существует, разве что CPU поддерживает специальную инструкцию сброса кэша (“flush my cache”). У большинства процессоров такая инструкция есть
Такой последовательности не существует, разве что CPU поддерживает специальную инструкцию сброса кэша (“flush my cache”). У большинства процессоров такая инструкция есть
Нежелательные простои при записи
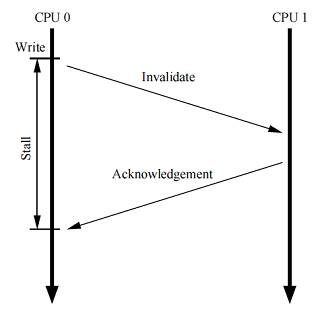
Хотя структура кэша, рассмотренная нами ранее, обеспечивает хорошую производительность чтения/записи данных для CPU, владеющего этими данными, производительность первой записи в конкретную кэш-линию очень плоха. Чтобы увидеть это, рассмотрим рисунок справа.
Рисунок демонстрирует задержку записи процессором 0 кэш-линии, которая находится в кэше CPU 1. CPU 0 должен ждать довольно продолжительный период времени, пока кэш-линия станет доступна для записи, — перейдет из кэша CPU 1 во владение CPU 0. Время, необходимое для переноса кэш-линии от одного CPU к другому, обычно на порядки выше, чем длительность инструкции, работающей с регистрами.
Но для CPU 0 нет причин ждать так долго: независимо от данных, переданных CPU 1, CPU 0 безусловно перезапишет их.
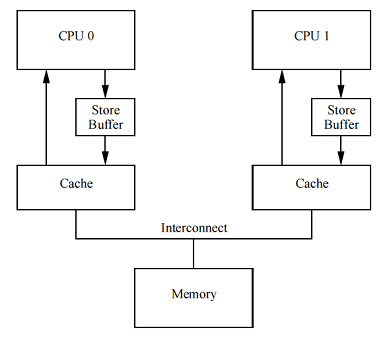
Store buffers
Один из методов борьбы с нежелательными простоями – добавить буфер записи (store buffer) между каждым CPU и его кэшем, как показано на рисунке справа. С таким буфером CPU 0 может просто записать write-операцию в свой store buffer и продолжать работу. После необходимого обмена сообщениями, когда кэш-линия наконец перейдет от CPU 1 к CPU 0, данные могут быть перемещены из store buffer в кэш-линию процессора 0.
Однако такое решение приводит к дополнительным проблемам, которые мы и рассмотрим в следующих двух разделах.
Store Forwarding
Чтобы увидеть первую проблему, называемую нарушением собственной целостности (self-consistency), рассмотрим следующий код:
1 a = 1; 2 b = a + 1; 3 assert( b == 2 );
Переменные «a» и «b» имеют начальное значение 0. Переменная «a» находится в кэше процессора 1, а переменная «b» — в кэше процессора 0.
Казалось бы, как вообще может сработать этот
assert? Однако, если бы кто-нибудь реализовал процессор с архитектурой как на рисунке, он был бы удивлен. Такая система могла бы потенциально выдать следующую последовательность событий:- 1. CPU 0 начинает выполнять
a = 1 - 2. CPU 0 смотрит, находится ли “a” в его кэше, и видит, что нет, — промах
- 3. Поэтому CPU 0 посылает сигнал “read invalidate”, чтобы получить исключительные права на кэш-линию с “a”
- 4. CPU 0 записывает “a” в свой store buffer
- . CPU 1 получает “read invalidate”-сообщение и отвечает на него, посылая кэш-линию с “a” и удаляя (invalidate) свою кэш-линию
- 6. CPU 0 начинает выполнять
b = a + 1 - 7. CPU 0 получает ответ от CPU 1, который ещё содержит старое, нулевое значение “a”, и помещает линию в свой кэш
- 8. CPU 0 загружает “a” из своего кэша, — загружается значение ноль
- 9. CPU 0 выполняет сохраненный в store buffer запрос на запись в кэш, записывая в кэш-линию значение “a” = 1
- 10. CPU 0 добавляет единицу к нулю, прочитанному ранее в качестве “a”, и сохраняет результат в кэш-линии “b” (которая, как мы помним, находится во владении CPU 0)
- 11. CPU 0 выполняет
assert(b == 2)и выдает ошибку —assertсрабатывает
Проблема в том, что мы имеем две копии “a” – одну в кэше и вторую в store buffer.
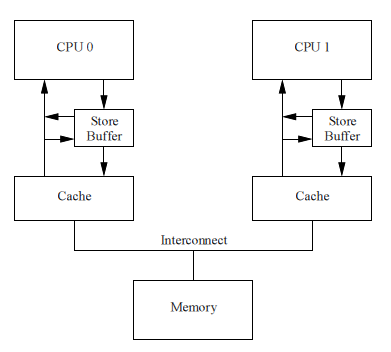
Этот пример нарушает очень важную гарантию: каждый CPU должен всегда выполнять операции в том порядке, как они заданы в программе (так называемый program order). Для программистов эта гарантия является интуитивно понятным требованием, так что hardware-инженеры вынуждены были внедрить store forwarding: каждый CPU читает данные не только из своего кэша, но и обязательно из store buffer. Другими словами, каждая операция записи может прямо передаваться следующей операции чтения через store buffer, без обращения к кэшу.
С store forwarding, шаг 8 в вышеприведенном примере должен прочитать корректное значение 1 переменной “a” из store buffer. В результате значение “b” станет 2, что нам и требуется.
Буферы записи и барьеры памяти
Чтобы увидеть другую проблему, — нарушение глобального порядка памяти (global memory ordering), — рассмотрим следующий пример, в котором переменные “a” и “b” имеют начальное значение 0:
1 void foo() 2 { 3 a = 1; 4 b = 1; 5 } 6 7 void bar() 8 { 9 while ( b == 0 ) continue; 10 assert( a == 1 ); 11 }
Пусть CPU 0 выполняет
foo(), а CPU 1 — bar(). Предположим, что память, содержащая “a”, находится только в кэше CPU 1, а CPU 0 владеет памятью, содержащей “b”. Тогда возможна следующая последовательность действий:- 1. CPU 0 выполняет
a=1. Кэш-линия для “a” не находится в кэше CPU 0, так что CPU 0 помещает новое значение “a” в свой буфер записи и издает сигнал “read invalidate”. - 2. CPU 1 выполняет
while (b==0) continue, но “b” нет в его кэше, так что он посылает сообщение “read” - 3. CPU 0 выполняет
b = 1. Он уже владеет “b” в своем кэше, то есть соответствующая кэш-линия находится в состоянии “exclusive” или “modified”, — так что он имеет полное право сохранить новое значение “b” в своем кэше, никому ничего не сообщая - 4. CPU 0 получает сообщение “read” и передает в ответе кэш-линию со свежайшим значением “b”, попутно переводя эту линию в состояние “shared” у себя в кэше
- 5. CPU 1 получает кэш-линию с “b” и помещает её в свой кэш
- 6. CPU 1 теперь может завершить выполнение
while (b == 0) continue, так как он видит, чтоb == 1, и приступить к выполнению следующей инструкции - 7. CPU 1 выполняет
assert(a == 1). Так как CPU 1 работает со старым значением “a”, условие не выполняется - 8. CPU 1 получает сообщение “read invalidate” и передает кэш-линию с “a” CPU 0, попутно инвалидируя эту линию в своем кэше. Но слишком поздно
- 9. CPU 0 получает кэш-линию с “a” и выполняет запись из буфера (сбрасывает store buffer в свой кэш)
Вопрос-ответ
Почему CPU 0 в шаге 1 вынужден слать сообщение “read invalidate”, а не просто “invalidate”?
Потому что кэш-линия содержит не только значение переменной “a”. Размер кэш-линии довольно большой.
Потому что кэш-линия содержит не только значение переменной “a”. Размер кэш-линии довольно большой.
Hardware-инженеры не могут ничем помочь в этом случае, так как процессоры ничего не знают про взаимосвязь переменных в программе. Поэтому инженеры ввели инструкции барьеров памяти, с помощью которых программисты могут выразить в программе подобные связи данных. Фрагмент программы должен быть изменен так:
1 void foo() 2 { 3 a = 1; 4 smp_mb(); 5 b =1; 6 } 7 8 void bar() 9 { 10 while ( b == 0 ) continue; 11 assert( a == 1 ); 12 }
Барьер памяти
smp_mb() [это реальная функция из ядра Linux] говорит процессору сбросить store buffer перед выполнением следующей записи в кэш. CPU может либо просто остановиться, ожидая, пока его store buffer не станет пустым, или может использовать store buffer для последующих записей, пока все записи, уже находящиеся в store buffer, не будут выполнены [тем самым в store buffer наводится некоторый FIFO-порядок].Последовательность выполнения программы с барьером памяти
- 1. CPU 0 выполняет
a=1. Кеш-линия для “a” не находится в кэше CPU 0, так что CPU 0 помещает новое значение “a” в свой буфер записи и издает сигнал “read invalidate”. - 2. CPU 1 выполняет
while (b==0) continue, но “b” нет в его кэше, так что он посылает сообщение “read” - 3. CPU 0 выполняет
smp_mb()и помечает (marked) все элементы в своем store buffer (в том числе иa = 1) - 4. CPU 0 выполняет
b = 1. Он уже владеет “b” (то есть соответствующая кэш-линия находится в состоянии “modified” или “exclusive”), но в буфере записи есть меченые (marked) элементы. Поэтому вместо записи нового значения “b” в свой кэш, он помещает “b” в свой буфер записи, но как неотмеченный (unmarked) элемент - 5. CPU 0 получает “read”-сообщение и передает кэш-линию с начальным значением “b” (=0) процессору 1. Также он меняет состояние кэш-линии на “shared”.
- 6. CPU 1 получает кэш-линию с “b” и помещает её в свой кэш
- 7. CPU 1 теперь мог бы завершить
while (b == 0) continue, но он видит, чтоb=0, так что он вынужден продолжить цикл. Новое значение “b” ещё скрыто в буфере записи CPU 0 - 8. CPU 1 получает сообщение “read invalidate” и предает кэш-линию с “a” процессору 0, инвалидируя свою кэш-линию
- 9. CPU 0 получает кэш-линию с “a” и выполняет ранее буферизованную запись, переводя свою кэш-линию с “a” в состояние “modified”
- 10. Так как запись “a” – единственный помеченный (marked) вызовом
smp_mb()элемент, CPU 0 может также выполнить запись “b”, но кэш-линию с “b” находится в состоянии “shared” - 11. Поэтому CPU 0 посылает сообщение “invalidate” процессору 1
- 12. CPU 1 получает сигнал “invalidate”, инвалидирует кэш-линию с “b” в своем кэше и шлет сигнал “acknowledgment” процессору 0
- 13. CPU 1 выполняет
while (b == 0) continue, но кэш-линии с “b” нет в кэше, поэтому он передает сообщение “read” процессору 0 - 14. CPU 0 получает сообщение “acknowledgment” и переводит кэш-линию с “b” в состояние “exclusive”, затем сохраняет “b” в кэше
- 15. CPU 0 получает сигнал “read” и передает кэш-линию с “b” процессору 1. Попутно кэш-линия с “b” переводится в состояние “shared”
- 16. CPU 1 получает кэш-линию с “b” и записывает её в свой кэш
- 17. CPU 1 теперь может завершить выполнение
while (b == 0) continueи продолжить далее - 18. CPU 1 выполняет
assert(a == 1), но кэш-линии с “a” нет в его кэше. Как только он получит значение “a” от CPU 0, он сможет продолжить выполнение. Значение “a” будет самым свежим иassertне сработает
Как видим, даже интуитивно простые вещи приводят к множеству сложных шагов в кремнии.
Нежелательные простои при последовательности записей
К сожалению, каждый буфер записи должен быть относительно маленьким. Это значит, что если CPU выполняет большую последовательность записей, он полностью заполняет свой store buffer (например, если каждая запись приводит к промаху). В этом случае CPU должен ждать, пока завершаться все инвалидации, чтобы затем он смог сбросить свой буфер в кэш и продолжить выполнение. Такая же ситуация может возникнуть сразу после барьера памяти, когда все последующие инструкции записи должны ждать завершения инвалидаций, вне зависимости от того, приводят ли эти записи к промахам кэша или нет.
Такая ситуация может быть разрулена, если сообщения “invalidate acknowledge” будут обрабатываться быстрее. Один из путей достижения этого – ввести для каждого CPU очередь сообщений “invalidate”, или invalidate queue.
Invalidate queue
Одной из причин, почему сообщения подтверждения инвалидаций (invalidate acknowledge) так тормозят, является то, что CPU должен быть уверен, что соответствующая кэш-линия действительно инвалидирована. Такая инвалидация может быть довольно долгой, если кэш занят, например, если процессор интенсивно читает/пишет данные, которые все находятся в кэше. К тому же, в короткий интервал времени возникает целый поток сообщений инвалидации, CPU может не справляться с ними, что приводит к простою остальных CPU.
Однако CPU не обязательно инвалидировать кэш-линию перед посылкой подтверждения. Он может поместить invalidate-сообщение в очередь, конечно, с полным пониманием того, что это сообщение будет обработано прежде, чем процессор пошлет другие сообщения, касающиеся этой линии кэша.
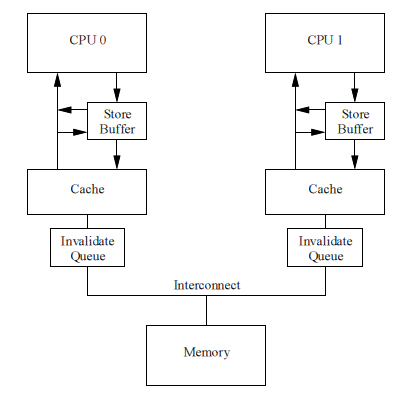
Invalidate Queues и подтверждения инвалидции
Рисунок справа показывает систему с очередью инвалидаций (invalidate queue). Процессор с invalidate queue может подтверждать invalidate-сообщения сразу, как только они будут появляться в очереди, вместо того, чтобы ждать, когда же кэш-линия инвалидируется. Разумеется, CPU должен согласовываться со своей очередью, когда он сам готовится послать invalidate-сообщение: если очередь уже содержит запись об инвалидации этой кэш-линии, процессор не может сразу посылать свое invalidate-сообщение. Вместо этого он должен ждать, пока не обработается соответствующая запись из очереди.
Помещение элемента в invalidate queue – это по сути обещание процессора обработать данное invalidate-сообщение перед тем, как отправлять любой сигнал протокола MESI, относящийся к данной кэш-линии.
Однако буферизация invalidate-сигналов приводит к дополнительной возможности нарушить порядок операций с памятью, что описано далее.
Invalidate queues и барьеры памяти
Предположим, процессоры помещают invalidate-запросы в очередь и отвечают немедленно. Такой подход минимизирует задержку инвалидации кэша, но может нарушить барьер памяти, что мы увидим в следующем примере.
Пусть переменные “a” и “b” изначально равны нулю и “a” находится в кэшах обоих процессоров в состоянии “shared” (то есть read-only), а “b” находится во владении CPU 0 (то есть линия кэша в состоянии “exclusive” или “modified). Предположим, CPU 0 выполняет
foo(), а CPU 1 — bar():1 void foo() 2 { 3 a = 1; 4 smp_mb(); 5 b = 1; 6 } 7 8 void bar() 9 { 10 while (b == 0) continue; 11 assert(a == 1); 12 }
Последовательность операций может быть такой:
- 1. CPU 0 выполняет
a=1. Соответствующая кэш-линия является read-only в кэше CPU 0, поэтому процессор помещает новое значение “a” в свой store buffer и посылает сообщение “invalidate”, чтобы CPU 1 сбросил свою кэш-линию с “a” - 2. CPU 1 выполняет
while(b == 0) continue, но “b” отсутствует в его кэше. Поэтому он посылает сообщение “read” - 3. CPU 1 получает “invalidate” от CPU 0, сохранят его в свое invalidate-очереди и немедленно отвечает
- 4. CPU 0 получает ответ от CPU 1, поэтому он волен выполнить
smp_mb()(строка 4) и поместить новое значение “a” из своего буфера записи в кэш - 5. CPU 0 выполняет
b=1. Он уже владеет кэш-линией с “b”, так что он просто сохраняет новое значение “b” в своем кэше - 6. CPU 0 получает “read”-сигнал и передает кэш-линию с новым значением “b” процессору 1, заодно помечая эту линию как “shared”
- 7. CPU 1 получает кэш-линию с “b” и помещает её в свой кэш
- 8. Теперь CPU 1 может завершить
while(b == 0) continueи перейти к следующей строке программы - 9. CPU 1 выполняет
assert(a == 1). Так как в его кэше находится старое значение “a”,assertсрабатывает и выкидывает исключение - Несмотря на исключение, CPU 1 выполняет помещенное в очередь “invalidate”-сообщение и с опозданием инвалидирует кэш-линию “a”
Вопрос-ответ
Почему на шаге 1 посылается сообщение “invalidate”, а не “read invalidate”? Неужели процессору не нужны другие значения, находящиеся в той же кэш-линии?
У CPU 0 уже есть все эти значения, так как они находятся в разделяемой (shared) read-only кэш-линии вместе с “a”. Поэтому всё, что требуется CPU 0, это оповестить другие процессоры, что им следует уничтожить свои копии данной кэш-линии. Для этого достаточно сообщения “invalidate”
У CPU 0 уже есть все эти значения, так как они находятся в разделяемой (shared) read-only кэш-линии вместе с “a”. Поэтому всё, что требуется CPU 0, это оповестить другие процессоры, что им следует уничтожить свои копии данной кэш-линии. Для этого достаточно сообщения “invalidate”
Итак, в повышении быстродействия ответов на инвалидацию мало пользы, если это приводит к игнорированию барьера памяти. Поэтому барьеры памяти должны взаимодействовать с invalidate queue: когда процессор выполняет барьер памяти, он должен помечать все элементы в своей invalidate-очереди и притормозить все последующие чтения до тех пор, пока invalidate-очередь не будет им полностью обработана.
Барьеры чтения и записи
В предыдущих главах барьеры памяти применялись для отметки элементов в store buffer и invalidate queue. Но в последнем примере нет причин для того, чтобы
foo() взаимодействовал с invalidate-очередью (так как нет чтения), равно как и нет причин для того, чтобы bar() взаимодействовал с буфером записи (так как нет записи).Многие архитектуры предоставляют более слабые (и, как следствие, более быстрые) барьеры памяти, позволяющие упорядочить только чтение или только запись. Грубо говоря, барьер чтения (read memory barrier) взаимодействует только с invalidate queue (помечает её элементы, то есть наводит некоторый порядок в очереди), а барьер записи (write memory barrier) – только со store buffer (также помечает его элементы, наводит порядок в буфере). Полный барьер взаимодействует и с тем, и с другим.
Эффект этих полубарьеров таков: барьер чтения упорядочивает только чтения (loads) для процессора, который выполняет барьер. Все чтения перед барьером полностью завершаются, и только тогда начинают выполняться чтения после барьера. Аналогично, барьер записи упорядочивает только запись (stores) для своего процессора: все записи до барьера завершаются, и только потом начинают выполняться записи (stores) после барьера. Полный барьер упорядочивает чтения и записи, но опять, — только для процессора, выполняющего этот барьер.
Если мы обновим наш пример так, что
foo и bar будут использовать барьеры чтения/записи, мы получим следующее:1 void foo() 2 { 3 a = 1; 4 smp_wmb(); // барьер записи 5 b = 1; 6 } 7 8 void bar() 9 { 10 while (b == 0) continue; 11 smp_rmb(); // барьер чтения 11 assert(a == 1); 12 }
Некоторые архитектуры имеют даже больший набор разнообразных барьеров, но и понимания рассмотренных трех вариантов достаточно для введения в теорию барьеров памяти.

Послесловие переводчика
На этом я завершаю перевод. Далее в оригинале ведется краткий обзор тех барьеров, которые предоставляют современные архитектуры. Интересующихся отсылаю к оригиналу, — по объему там осталось примерно столько же.
Попробуем подвести итоги.
Итак, мы имеем две операции взаимодействия процессора с кэшем/памятью – чтение (load) и запись (store). Две операции дают нам в совокупности четыре разных барьера памяти:
op1; // store или load barrier ; // memory fence op2; // store или load
- Load/Load – упорядочивает предыдущие load-инструкции с последующими. Как мы видели, этот барьер “наводит порядок” в invalidate queue: либо целиком обрабатывает эту очередь, либо проставляет в ней некоторые метки, задающие порядок обработки очереди в будущем. Относительно легкий барьер
- Store/Store – упорядочивает предыдущие store-инструкции с последующими. Воздействует на store buffer: либо целиком обрабатывает накопившийся буфер (что довольно накладно – операции записи всегда тяжелы для современных процессоров), либо, более вероятно, как-то помечает текущее содержимое store buffer, то есть опять-таки наводит в нем некоторый порядок его последующей обработки. В этом случае относительно легкий барьер
- Load/Store – упорядочивает предыдущие load-инструкции с последующими store. На что он может воздействовать? Думаю, препятствует спекулятивной записи. Похоже, также является довольно легким барьером
- Store/Load – упорядочивает предыдущие store-инструкции с последующими load. У нас store-инструкции попадают в store buffer. То есть этот барьер должен упорядочить store buffer, — просто проставить в нем некие метки? Нет, похоже, этого недостаточно. Ведь существует еще спекулятивное чтение, — этот барьер и его должен ограничить. На основании того, что мне известно о современных архитектурах, могу сделать вывод, что этот барьер приводит к полной обработке store buffer, что является довольно тяжелым действием. Итог: это самый тяжелый барьер из всех рассмотренных
Поздравляю, мы вывели барьеры памяти архитектуры Sparc!
Архитектура Sparc (в самом расслабленном своем режиме RMO – Relaxed Memory Ordering) имеет инструкцию
Например, полный барьер памяти в Sparc будет выглядеть на ассемблере так:
В принципе, все флаги и их комбинации представляют довольно легкие барьеры, кроме одного —
Архитектура Sparc (в самом расслабленном своем режиме RMO – Relaxed Memory Ordering) имеет инструкцию
membar, в качестве параметров которой передается всегда константа — набор битовых флагов, которые можно комбинировать битовым ИЛИ. Мнемоники этих флагов — #LoadLoad, #LoadStore, #StoreStore, #StoreLoad (остальные специфические флаги я рассматривать не буду, — они не относятся к прикладному программированию). Инструкция membar должна располагаться в коде между соответствующими операциями, для которых она является барьером:Load1; membar #LoadLoad; Load2Load; membar #LoadStore; StoreStore; membar #StoreLoad; LoadStore1; membar #StoreStore; Store2
Например, полный барьер памяти в Sparc будет выглядеть на ассемблере так:
membar #LoadLoad|#LoadStore|#StoreStore|#StoreLoad
В принципе, все флаги и их комбинации представляют довольно легкие барьеры, кроме одного —
#StoreLoad. И это не особенность архитектуры Sparc, а фактически свойство всех современных weakly-ordered процессоров. Далее
Итак, мы рассмотрели, откуда взялись барьеры памяти. Узнали, что они есть необходимое зло. Мы даже попробовали их как-то расставить в коде.
Вытесняющий планировщик и барьеры памяти
Стоит заметить, что барьеры памяти — это именно отдельные ассемблерные инструкции практически у всех современных архитектур (особняком стоит, пожалуй, только Intel Itanium – в нем барьер может являться частью load/store/RMW-инструкции). Корректная расстановка барьеров критически важна в lock-free алгоритмах. Но современные операционные системы в подавляющем большинстве реализуют вытесняющую модель управления процессами/потоками. То есть потоку отводится квант времени, по истечении которого он вытесняется другим потоком. Вытеснение (переключение контекста) может произойти и непосредственно перед инструкцией барьера памяти. Получается, что все наши старания насмарку – мы выполнили критическую атомарную операцию, а барьера после неё нет?
На самом деле барьер есть. Код переключения контекста имеет одной из своих первых инструкций как раз полный барьер памяти или что-то подобное, зачастую более тяжеловесное, чем нам нужно. Поэтому наш lock-free алгоритм будет работать правильно, если, конечно же, мы сами где-то не накосячим.
На самом деле барьер есть. Код переключения контекста имеет одной из своих первых инструкций как раз полный барьер памяти или что-то подобное, зачастую более тяжеловесное, чем нам нужно. Поэтому наш lock-free алгоритм будет работать правильно, если, конечно же, мы сами где-то не накосячим.
Рассмотренный подход к расстановке барьеров памяти я бы назвал read/wrire-подходом. В ходе разработки стандарта C++11 read/write-подход к проблемам упорядочения доступа к памяти был признан слишком привязанным к архитектуре и была разработана acquire/release семантика, легшая в основу стандарта. Как не раз было сказано в статье, барьеры памяти прямо влияют только на процессор, выполняющий барьер, и только опосредованно (через протокол MESI) — на другие процессоры. Модель acquire/release поступает по-другому, — в ней постулируется, как должны взаимодействовать разные параллельные потоки (то есть процессоры/ядра), и практически ничего не говорится, как этого достичь. На самом деле, реализация этой модели — это применение тех или иных барьеров памяти.
О модели памяти C++11 я собираюсь поговорить в следующей статье Основ.
Lock-free структуры данных
