 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.Тема не нова, но становится особенно актуальной, когда в базе наблюдается постоянный рост данных – таблицы становятся большими, а поиск и выборка по ним – медленной.
Как правило, это происходит из-за плохо спроектированной схемы – изначально не рассчитанной на оперирование большими объемами данных.
Чтобы рост данных в таблицах не приводил к падению производительности при работе с ними, рекомендуется взять на вооружение несколько правил при проектировании схемы.
Первое и, наверное, самое важное. Типы данных в таблицах должны иметь минимальную избыточность.
Все данные, которыми оперирует SQL Server, хранятся на, так называемых, страницах, которые имеют фиксированный размер в 8 Кб. При записи и чтении сервер оперирует именно страницами, а не отдельными строками.
Поэтому, чем более компактные типы данных используются в таблице, тем меньше страниц требуется для их хранения. Меньшее число страниц – меньшее количество дисковых операций.
Кроме очевидного снижения нагрузки на дисковую подсистему – в данном случае есть еще одно преимущество — при чтении с диска, любая страница вначале помещается в специальную область памяти (Buffer Pool), а потом уже используется по прямому назначению – для считывания или изменения данных.
При использовании компактных типов данных, в Buffer Pool можно поместить больше данных на том же количестве страниц – за счет этого мы не тратим впустую оперативную память и сокращаем количество логических операций.
Теперь рассмотрим небольшой пример – таблицу, в которой хранится информация о рабочих днях каждого сотрудника.
CREATE TABLE dbo.WorkOut1 ( DateOut DATETIME , EmployeeID BIGINT , WorkShiftCD NVARCHAR(10) , WorkHours DECIMAL(24,2) , CONSTRAINT PK_WorkOut1 PRIMARY KEY (DateOut, EmployeeID) )
Правильно ли выбраны типы данных в этой таблице? По-видимому – нет.
Например, очень сомнительно что сотрудников на предприятии насколько много (2^63-1), что для покрытия такой ситуации был выбран тип данных BIGINT.
Уберем избыточность и посмотрим, будет ли запрос из такой таблицы более быстрым?
CREATE TABLE dbo.WorkOut2 ( DateOut SMALLDATETIME , EmployeeID INT , WorkShiftCD VARCHAR(10) , WorkHours DECIMAL(8,2) , CONSTRAINT PK_WorkOut2 PRIMARY KEY (DateOut, EmployeeID) )
На плане выполнения можно увидеть разницу в стоимости, которое зависит от среднего размера строки и ожидаемого количество строк, которое вернет запрос:
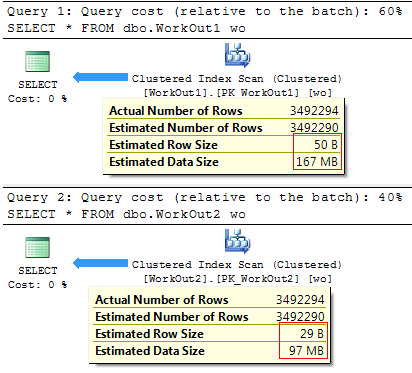
Весьма логично, что чем меньший объем данных требуется прочитать – тем быстрее будет выполняться сам запрос:
(3492294 row(s) affected)
SQL Server Execution Times:
CPU time = 1919 ms, elapsed time = 33606 ms.
(3492294 row(s) affected)
SQL Server Execution Times:
CPU time = 1420 ms, elapsed time = 29694 ms.
Как Вы видите, использование менее избыточных типов данных зачастую положительно сказывается на производительности запросов и позволяет существенно снизить размер проблемных таблиц.
К слову, узнать размер таблицы можно посредством следующего запроса:
SELECT table_name = SCHEMA_NAME(o.[schema_id]) + '.' + o.name , data_size_mb = CAST(do.pages * 8. / 1024 AS DECIMAL(8,4)) FROM sys.objects o JOIN ( SELECT p.[object_id] , total_rows = SUM(p.[rows]) , total_pages = SUM(a.total_pages) , usedpages = SUM(a.used_pages) , pages = SUM( CASE WHEN it.internal_type IN (202, 204, 207, 211, 212, 213, 214, 215, 216, 221, 222) THEN 0 WHEN a.[type] != 1 AND p.index_id < 2 THEN a.used_pages WHEN p.index_id < 2 THEN a.data_pages ELSE 0 END ) FROM sys.partitions p JOIN sys.allocation_units a ON p.[partition_id] = a.container_id LEFT JOIN sys.internal_tables it ON p.[object_id] = it.[object_id] GROUP BY p.[object_id] ) do ON o.[object_id] = do.[object_id] WHERE o.[type] = 'U'
Для рассматриваемых таблиц, запрос вернет следующие результаты:
table_name data_size_mb -------------------- ------------------------------- dbo.WorkOut1 167.2578 dbo.WorkOut2 97.1250
Правило второе. Избегайте дублирования и применяйте нормализацию данных.
Собственно, недавно я анализировал базу данных одного бесплатного веб-сервиса для форматирования T-SQL кода. Серверная часть там очень простая и состояла из одной единственной таблицы:
CREATE TABLE dbo.format_history ( session_id BIGINT , format_date DATETIME , format_options XML )
Каждый раз при форматировании сохранялся id текущей сессии, системное время сервера и настройки, с которыми пользователь отформатировал свой SQL код. Затем полученные данные использовались для выявления наиболее популярных стилей форматирования.
С ростом популярности сервиса, количество строк в таблице увеличилось, а обработка профилей форматирования занимала все большее количество времени. Причина заключалась в архитектуре сервиса – при каждой вставке в таблицу сохранялся полный набор настроек.
Настройки имели следующую XML структуру:
<FormatProfile> <FormatOptions> <PropertyValue Name="Select_SelectList_IndentColumnList">true</PropertyValue> <PropertyValue Name="Select_SelectList_SingleLineColumns">false</PropertyValue> <PropertyValue Name="Select_SelectList_StackColumns">true</PropertyValue> <PropertyValue Name="Select_SelectList_StackColumnsMode">1</PropertyValue> <PropertyValue Name="Select_Into_LineBreakBeforeInto">true</PropertyValue> ... <PropertyValue Name="UnionExceptIntersect_LineBreakBeforeUnion">true</PropertyValue> <PropertyValue Name="UnionExceptIntersect_LineBreakAfterUnion">true</PropertyValue> <PropertyValue Name="UnionExceptIntersect_IndentKeyword">true</PropertyValue> <PropertyValue Name="UnionExceptIntersect_IndentSubquery">false</PropertyValue> ... </FormatOptions> </FormatProfile>
Всего 450 опций форматирования – каждая такая строка в таблице занимала примерно 33Кб. А ежедневный прирост данных составлял более 100Мб. С каждым днем база разрасталась, а делать аналитику по ней становилось делать дольше.
Исправить ситуацию оказалось просто – все уникальные профили были вынесены в отдельную таблицу, где для каждого набора опций был получен хеш. Начиная с SQL Server 2008 для этого можно использовать функцию sys.fn_repl_hash_binary.
В результате схема была нормализирована:
CREATE TABLE dbo.format_profile ( format_hash BINARY(16) PRIMARY KEY , format_profile XML NOT NULL ) CREATE TABLE dbo.format_history ( session_id BIGINT , format_date SMALLDATETIME , format_hash BINARY(16) NOT NULL , CONSTRAINT PK_format_history PRIMARY KEY CLUSTERED (session_id, format_date) )
И если запрос на вычитку раньше был таким:
SELECT fh.session_id, fh.format_date, fh.format_options FROM SQLF.dbo.format_history fh
То на получение тех же данных в новой схеме потребовалось сделать JOIN:
SELECT fh.session_id, fh.format_date, fp.format_profile FROM SQLF_v2.dbo.format_history fh JOIN SQLF_v2.dbo.format_profile fp ON fh.format_hash = fp.format_hash
Если сравнить время выполнения запросов, то мы не увидим явного преимущества от изменения схемы.
(3090 row(s) affected)
SQL Server Execution Times:
CPU time = 203 ms, elapsed time = 4698 ms.
(3090 row(s) affected)
SQL Server Execution Times:
CPU time = 125 ms, elapsed time = 4479 ms.
Но цель в данном случае преследовалась другая – ускорить аналитику. И если раньше приходилось писать очень мудреный запрос для получения списка самых популярных профилей форматирования:
;WITH cte AS ( SELECT fh.format_options , hsh = sys.fn_repl_hash_binary(CAST(fh.format_options AS VARBINARY(MAX))) , rn = ROW_NUMBER() OVER (ORDER BY 1/0) FROM SQLF.dbo.format_history fh ) SELECT c2.format_options, c1.cnt FROM ( SELECT TOP (10) hsh, rn = MIN(rn), cnt = COUNT(1) FROM cte GROUP BY hsh ORDER BY cnt DESC ) c1 JOIN cte c2 ON c1.rn = c2.rn ORDER BY c1.cnt DESC
То за счет нормализации данных стало возможным существенно упростить не только сам запрос:
SELECT fp.format_profile , t.cnt FROM ( SELECT TOP (10) fh.format_hash , cnt = COUNT(1) FROM SQLF_v2.dbo.format_history fh GROUP BY fh.format_hash ORDER BY cnt DESC ) t JOIN SQLF_v2.dbo.format_profile fp ON t.format_hash = fp.format_hash
Но и сократить время его выполнения:
(10 row(s) affected)
SQL Server Execution Times:
CPU time = 2684 ms, elapsed time = 2774 ms.
(10 row(s) affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 379 ms.
Приятным дополнением также стало и снижение размера база данных на диске:
database_name row_size_mb ---------------- --------------- SQLF 123.50 SQLF_v2 7.88
Вернуть размер файла данных для базы можно следующим запросом:
SELECT database_name = DB_NAME(database_id) , row_size_mb = CAST(SUM(CASE WHEN type_desc = 'ROWS' THEN size END) * 8. / 1024 AS DECIMAL(8,2)) FROM sys.master_files WHERE database_id IN (DB_ID('SQLF'), DB_ID('SQLF_v2')) GROUP BY database_id
Надеюсь, на этом примере, мне удалось показать важность нормализации данных и минимизации избыточности в базе.
Третье. Осторожно выбирайте столбцы, входящие в индексы.
Индексы позволяют существенно ускорить выборку из таблицы. Также как и данные из таблиц, индексы хранятся на страницах. Соотвественно. чем меньше страниц требуется для хранения индекса – тем быстрее по нему можно провести поиск.
Очень важно правильно выбрать поля, которые будут входить в кластерный индекс. Поскольку все столбцы кластерного индекса автоматически входят в каждый некластерный (по указателю).
Четвертое. Используйте промежуточные и консолидированные таблицы.
Здесь все достаточно просто – зачем каждый раз делать сложный запрос из большой таблицы, если есть возможность сделать простой запрос из маленькой.
Например, в наличии есть запрос по консолидации данных:
SELECT WorkOutID , CE = SUM(CASE WHEN WorkKeyCD = 'CE' THEN Value END) , DE = SUM(CASE WHEN WorkKeyCD = 'DE' THEN Value END) , RE = SUM(CASE WHEN WorkKeyCD = 'RE' THEN Value END) , FD = SUM(CASE WHEN WorkKeyCD = 'FD' THEN Value END) , TR = SUM(CASE WHEN WorkKeyCD = 'TR' THEN Value END) , FF = SUM(CASE WHEN WorkKeyCD = 'FF' THEN Value END) , PF = SUM(CASE WHEN WorkKeyCD = 'PF' THEN Value END) , QW = SUM(CASE WHEN WorkKeyCD = 'QW' THEN Value END) , FH = SUM(CASE WHEN WorkKeyCD = 'FH' THEN Value END) , UH = SUM(CASE WHEN WorkKeyCD = 'UH' THEN Value END) , NU = SUM(CASE WHEN WorkKeyCD = 'NU' THEN Value END) , CS = SUM(CASE WHEN WorkKeyCD = 'CS' THEN Value END) FROM dbo.WorkOutFactor WHERE Value > 0 GROUP BY WorkOutID
Если данные в таблице изменяются не слишком часто, можно создать отдельную таблицу:
SELECT * FROM dbo.WorkOutFactorCache
И не удивительно, что чтение из консолидированной таблицы будет проходить быстрее:
(185916 row(s) affected)
SQL Server Execution Times:
CPU time = 3448 ms, elapsed time = 3116 ms.
(185916 row(s) affected)
SQL Server Execution Times:
CPU time = 1410 ms, elapsed time = 1202 ms.
Пятое. В каждом правиле есть свои исключения.
Я показал пару примеров, когда изменение типов данных на менее избытоные позволяет сократить время выполнения запроса. Но это бывает не всегда.
Например, у типа данных BIT есть одна особенность – SQL Server оптимизирует хранение группы столбцов этакого типа на диске. Например, если в таблице имеется 8 или меньше столбцов типа BIT, они хранятся на странице как 1 байт, если до 16 столбцов типа BIT, они хранятся как 2 байта и т.д.
Хорошая новость – таблица будет занимать существенно меньше места и сократит количество дисковых операций.
Плохая новость – при выборке данных этого типа будет происходить неявное декодирование, которое очень требовательно к ресурсам процессора.
Покажу это на примере. Есть три идентичные таблицы, которые содержат информацию о календарном графике сотрудников (31 + 2 PK столбца). Все они отличаются только типом данных для консолидированных значений (1 — вышел на работу, 0 — отсутствовал):
SELECT * FROM dbo.E_51_INT SELECT * FROM dbo.E_52_TINYINT SELECT * FROM dbo.E_53_BIT
При использовании менее избыточных данных размер таблицы заметно уменьшился (особенно последняя таблица):
table_name data_size_mb -------------------- -------------- dbo.E31_INT 150.2578 dbo.E32_TINYINT 50.4141 dbo.E33_BIT 24.1953
Но существенного выигрыша в скорости выполнения от использования типа BIT мы не получим:
(1000000 row(s) affected) Table 'E31_INT'. Scan count 1, logical reads 19296, physical reads 1, read-ahead reads 19260, ... SQL Server Execution Times: CPU time = 1607 ms, elapsed time = 19962 ms. (1000000 row(s) affected) Table 'E32_TINYINT'. Scan count 1, logical reads 6471, physical reads 1, read-ahead reads 6477, ... SQL Server Execution Times: CPU time = 1029 ms, elapsed time = 16533 ms. (1000000 row(s) affected) Table 'E33_BIT'. Scan count 1, logical reads 3109, physical reads 1, read-ahead reads 3096, ... SQL Server Execution Times: CPU time = 1820 ms, elapsed time = 17121 ms.
Хотя план выполнения будет говорить об обратном:
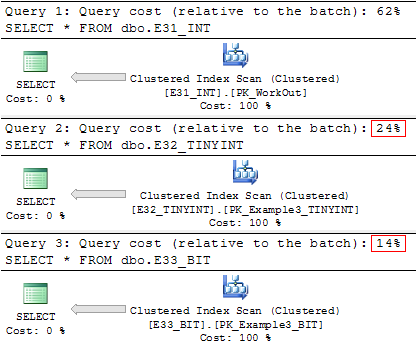
В результате наблюдений было замечено, что негативный эффект от декодирования не будет проявятся если таблица содержит не более 8 BIT столбцов.
Попутно стоит отметить, что в метаданных SQL Server тип данных BIT используется очень редко – чаще применяют тип BINARY и вручную делают сдвиг для получения того или иного значения.
И последнее о чем нужно упомянуть. Удаляйте ненужные данные.
Собственно, зачем это делать?
При выборке данных, SQL Server поддерживает механизм оптимизации производительности, называемый упреждающим чтением, который пытается предугадать, какие именно страницы данных и индексов понадобятся для выполнения запроса, и помещает эти страницы в буферный кэш, прежде чем в них возникнет реальная необходимость.
Соответственно, если таблица содержит много лишних данных – это может привести к ненужным дисковым операциям.
Кроме того, удаление ненужных данных позволяет сократить количество логических операций при чтении данных из Buffer Pool – поиск и выборка данных будет проходить по меньшему объёму данных.
В заключение, что могу еще добавить – внимательно выбирайте типы данных для столбцов в Ваших таблицах и старайтесь учитывать будущие нагрузки на базу данных.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод:
Practical Tips to Reduce SQL Server Database Table Size
