Просто хотел поделиться этой историей. Знаю, я мог бы лучше подготовиться к этому инциденту, но так уж получилось. :)
Сегодня утром я открыл почтовый ящик и обнаружил около 150 предупреждений из программы мониторинга лога. Я подумал, что случайно запушил какой-то баг в продакшн — и быстро начал расследование. Но вскоре стало понятно, что некий парень очень быстро создаёт новые учетные записи на нашем сервисе API скриншотов ApiLeap и быстро расходует весь кредит бесплатного плана на каждом аккаунте.
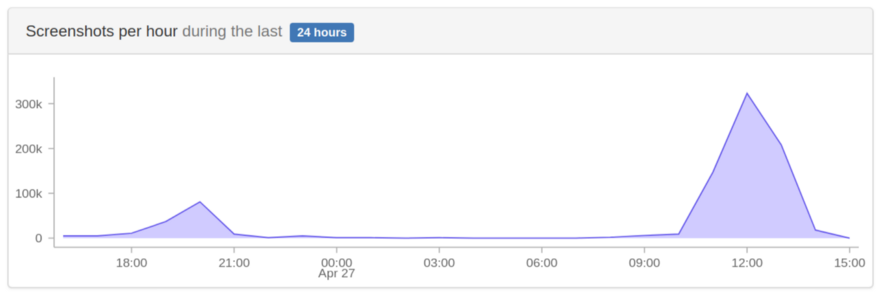
Он делал скриншоты этой страницы и майнил криптовалюту на машинах, где работают инстансы Chrome, которые мы используем для скриншотов.
Я выяснил, что он зависает на главной странице нашего сайта, так что можно поговорить с ним через онлайновый чат Crisp — инструмент, который мы используем для общения с потенциальными клиентами на сайте. Вот это разговор:
Сегодня утром я открыл почтовый ящик и обнаружил около 150 предупреждений из программы мониторинга лога. Я подумал, что случайно запушил какой-то баг в продакшн — и быстро начал расследование. Но вскоре стало понятно, что некий парень очень быстро создаёт новые учетные записи на нашем сервисе API скриншотов ApiLeap и быстро расходует весь кредит бесплатного плана на каждом аккаунте.
Он делал скриншоты этой страницы и майнил криптовалюту на машинах, где работают инстансы Chrome, которые мы используем для скриншотов.
Я выяснил, что он зависает на главной странице нашего сайта, так что можно поговорить с ним через онлайновый чат Crisp — инструмент, который мы используем для общения с потенциальными клиентами на сайте. Вот это разговор: