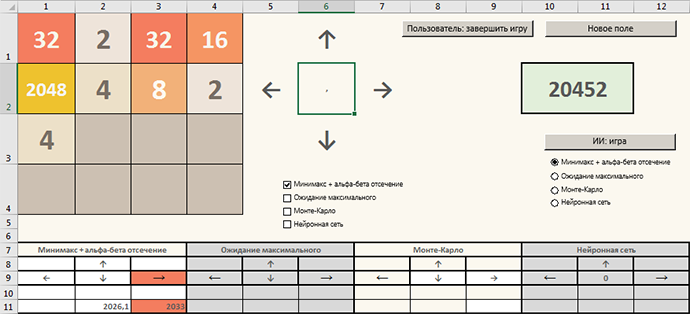
Метод Монте-Карло мы разобрали, сегодня посмотрим, как компьютерный разум играет в 2048, используя старый добрый минимакс с альфа-бета отсечением.

Разработчик ПО


От переводчика:
Представляю вашему вниманию статью авторства Andy Gainey, в прошлом независимого разработчика игровых инструментов, ныне сотрудника Paradox Development Studio. На мой взгляд, автор играючи создал один из лучших процедурных генераторов планет с открытым исходным кодом.
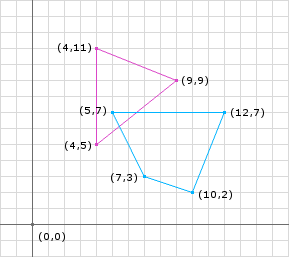
VectorIShapeCollision



Номинация: За проработку теории контрактов в неоклассической экономике. Неоклассическое направление подразумевает рациональность экономических агентов, широко использует теорию экономического равновесия и теорию игр.



 Привет, Хаброжители! Мы недавно сдали в типографию книгу Эндрю Траска (Andrew W. Trask), закладывающую фундамент для дальнейшего овладения технологией глубокого обучения. Она начинается с описания основ нейронных сетей и затем подробно рассматривает дополнительные уровни и архитектуры.
Привет, Хаброжители! Мы недавно сдали в типографию книгу Эндрю Траска (Andrew W. Trask), закладывающую фундамент для дальнейшего овладения технологией глубокого обучения. Она начинается с описания основ нейронных сетей и затем подробно рассматривает дополнительные уровни и архитектуры.

