Этим летом мне посчастливилось быть в Торонто. Именно там, а не в привычной всем Долине, находится офис стартапа №1 в Канаде — 500px. Конечно, нельзя было упускать шанс побывать в гостях у известного на весь мир проекта, который, кстати сказать, создали и развивают два «наших» фотографа — москвич Евгений Чеботарев и киевлянин Олег Гуцол. Так что, в одну из пятниц я отправился в гости.
 «500px — is a photo community powered by creative people worldwide», — так о своем проекте говорят сами авторы. Я бы добавил, что это лучший сайт с самыми красивыми фотографиями, которые я когда либо встречал.
«500px — is a photo community powered by creative people worldwide», — так о своем проекте говорят сами авторы. Я бы добавил, что это лучший сайт с самыми красивыми фотографиями, которые я когда либо встречал.
Благодаря внутренней экосистеме, которая каждому в его ленту отбирает действительно потрясающие снимки, отличному интерфейсу и продуманным мотивационным правилам для фотографов, сайт получил мировую известность и продолжает стремительный рост.
Побывать в офисе у такого проекта и окунуться в рабочую атмосферу было по-настоящему интересно.
Основное рабочее пространство — open space в большой комнате. Столы расположены «фермами» в несколько рядов по 4-6 рабочих мест в ряду. Рабочие места — друг на против друга.

Что такое 500px?
«500px — is a photo community powered by creative people worldwide», — так о своем проекте говорят сами авторы. Я бы добавил, что это лучший сайт с самыми красивыми фотографиями, которые я когда либо встречал.Благодаря внутренней экосистеме, которая каждому в его ленту отбирает действительно потрясающие снимки, отличному интерфейсу и продуманным мотивационным правилам для фотографов, сайт получил мировую известность и продолжает стремительный рост.
Побывать в офисе у такого проекта и окунуться в рабочую атмосферу было по-настоящему интересно.
Офис
Основное рабочее пространство — open space в большой комнате. Столы расположены «фермами» в несколько рядов по 4-6 рабочих мест в ряду. Рабочие места — друг на против друга.
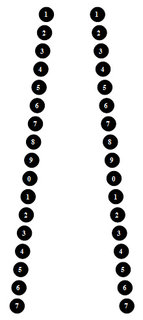 Не знаю, все ли программисты всесторонне любознательные люди, но я всегда пытаюсь получить фундаментальные знания во всех областях, которые могут быть практически полезны. В то время, когда мне в голову пришла эта идея я изучал анатомию и физиологию по журналам «Тело человека. Снаружи и внутри», ну а по работе я занимался стерео-варио фотографиями (для тех кто не знает — были такие советские календарики с ребристой поверхностью, где картинка либо казалась объемной, либо менялась). Так вот, в один из вечеров мне пришла в голову замечательная идея, которую я на протяжении уже 4х лет использую для поддержания своего зрения.
Не знаю, все ли программисты всесторонне любознательные люди, но я всегда пытаюсь получить фундаментальные знания во всех областях, которые могут быть практически полезны. В то время, когда мне в голову пришла эта идея я изучал анатомию и физиологию по журналам «Тело человека. Снаружи и внутри», ну а по работе я занимался стерео-варио фотографиями (для тех кто не знает — были такие советские календарики с ребристой поверхностью, где картинка либо казалась объемной, либо менялась). Так вот, в один из вечеров мне пришла в голову замечательная идея, которую я на протяжении уже 4х лет использую для поддержания своего зрения.



 Наверное любой современный веб-проект сложно себе представить без… без контента! Да, именно контент в разных его проявлениях сегодня «правит бал» в различных веб-проектах. Не так важно — создаваемый пользователями или получаемый из других источников автоматически — информация является основной любого (ну, или почти любого) проекта. А раз так — то вопрос поиска необходимой информации стоит очень остро. И острее с каждым днем, ввиду стремительного расширения количества этого самого контента, в основном за счёт создаваемого пользователями (это и форумы, и блоги и модные нынче сообщества, вроде
Наверное любой современный веб-проект сложно себе представить без… без контента! Да, именно контент в разных его проявлениях сегодня «правит бал» в различных веб-проектах. Не так важно — создаваемый пользователями или получаемый из других источников автоматически — информация является основной любого (ну, или почти любого) проекта. А раз так — то вопрос поиска необходимой информации стоит очень остро. И острее с каждым днем, ввиду стремительного расширения количества этого самого контента, в основном за счёт создаваемого пользователями (это и форумы, и блоги и модные нынче сообщества, вроде 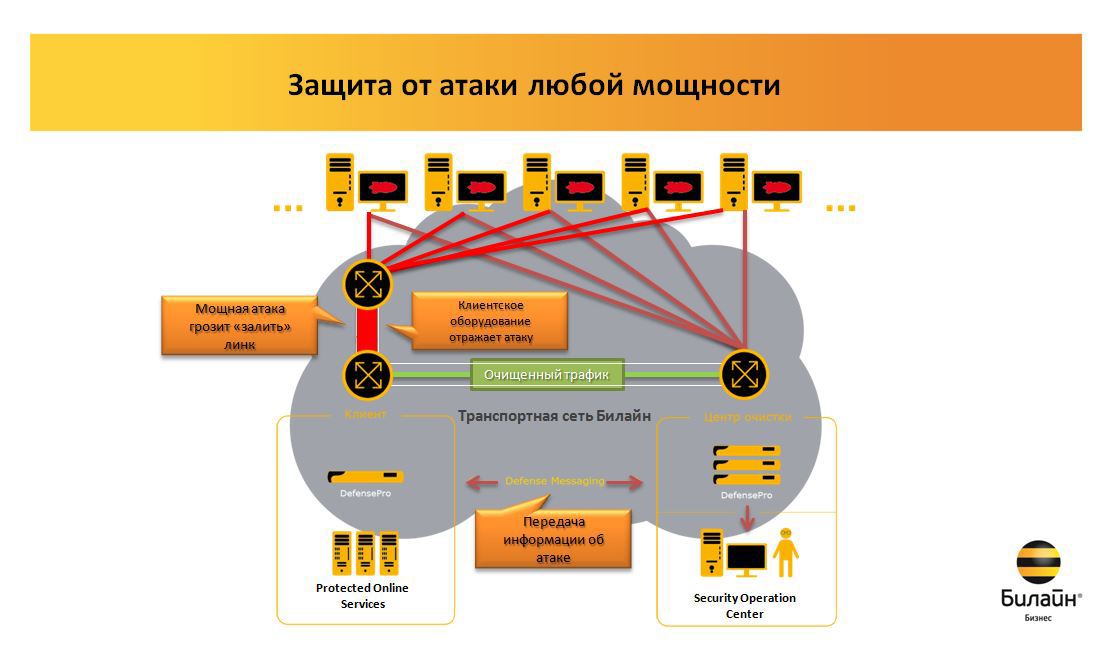
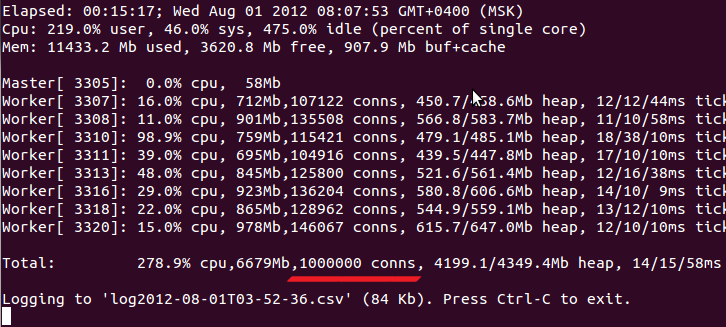
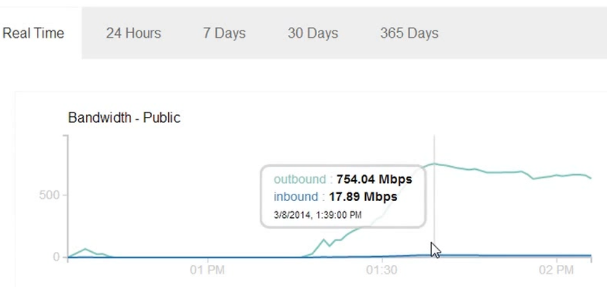
 На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется
На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется 






 Салют, Хабр!
Салют, Хабр!