В деле удалённого вызова процедур дела уже давно обстоят в точности как в известном комиксе
«14 стандартов» — чего только тут ни
напридумано: древние DCOM и Corba, странные SOAP и .NET Remoting, современные REST и AMQP (да, я знаю, что кое-что из этого формально не RPC, для того чтобы обсудить терминологию даже вот
специальный топик недавно создали, тем ни менее всё это используется как RPC, а если что-то выглядит, как утка и плавает, как утка — ну,
вы в курсе).
И конечно же, в полном соответствии со сценарием комикса, на рынок пришел Google и заявил что вот теперь наконец он создал ещё один, последний и самый правильный стандарт RPC. Google можно понять — продолжать в 21-ом веке гонять петабайты данных по старому и неэффективному HTTP+REST, теряя на каждом байте деньги — просто глупо. В то же время взять чужой стандарт и сказать «мы не смогли придумать ничего лучше» — совершенно не в их стиле.
Поэтому, встречайте,
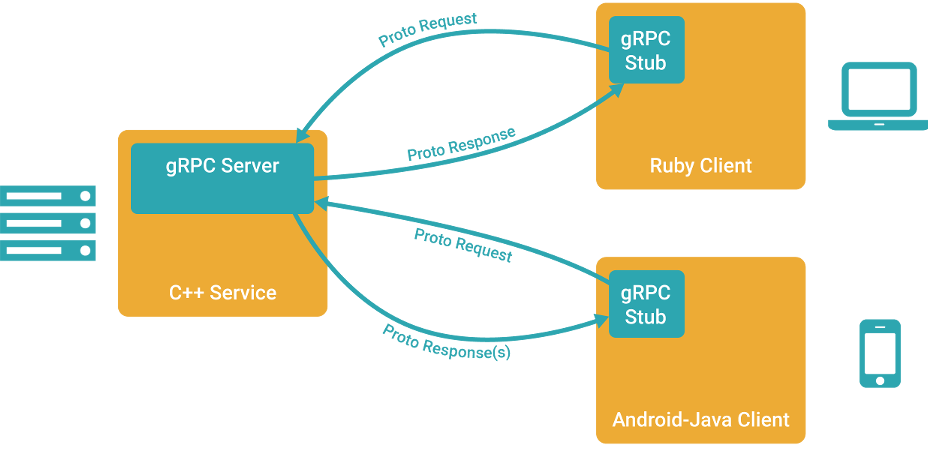
gRPC, что расшифровывается как «gRPC Remote Procedure Calls» — новый фреймворк для удалённого вызова процедур от Google. В этой статье мы поговорим о том, почему же он, в отличии от предыдущих «14 стандартов» всё-таки захватит мир (ну или хотя бы его часть), попробуем собрать билд gRPC под Windows + Visual Studio (и даже не говорите мне, что инструкция не нужна — в официальной документации упущено штук 5 важных шагов, без которых ничего не собирается), а также попробуем написать простенький сервис и клиент, обменивающиеся запросами и ответами.