ООП (Объектно-Ориентированное Программирование) стало неотъемлемой частью разработки многих современных проектов, но, не смотря на популярность, эта парадигма является далеко не единственной. Если вы уже умеете работать с другими парадигмами и хотели бы ознакомиться с оккультизмом ООП, то впереди вас ждет немного лонгрид и два мегабайта картинок и анимаций. В качестве примеров будут выступать трансформеры.
Некоторое время назад мне довелось организовывать новую группу разработки, которая должна была заняться развитием OLAP и BI продуктов в дружеской софтверной компании. А так как группа была собрана из свежих выпускников ВУЗов, то мне пришлось написать «краткий курс молодого бойца» для того чтобы максимально доступно дать начальные понятия об OLAP людям, которые ни разу с ним не сталкивались, но уже имели опыт программирования и работы с БД.
Выкладываю теперь это Введение в Общественное Достояние.
В статье несколько смешиваются понятия OLAP, Business Intelligence, и Data Warehouse, но и в жизни часто сложно понять, где проходит граница. А уж в реальных проектах, так и подавно, все они ходят рядом. Поэтому прошу не судить строго.
Эта статья рассказывает о времени выполнения и о расходе памяти большинства алгоритмов используемых в информатике. В прошлом, когда я готовился к прохождению собеседования я потратил много времени исследуя интернет для поиска информации о лучшем, среднем и худшем случае работы алгоритмов поиска и сортировки, чтобы заданный вопрос на собеседовании не поставил меня в тупик. За последние несколько лет я проходил интервью в нескольких стартапах из Силиконовой долины, а также в некоторых крупных компаниях таких как Yahoo, eBay, LinkedIn и Google и каждый раз, когда я готовился к интервью, я подумал: «Почему никто не создал хорошую шпаргалку по асимптотической сложности алгоритмов? ». Чтобы сохранить ваше время я создал такую шпаргалку. Наслаждайтесь!
Прогнозирование – это важный инструмент экономики. Оно позволяет осуществлять рациональные закупки, вырабатывать долгосрочные планы действий или же, как в случае аудита, спрогнозировать будущие затраты. Прогнозирование так же является одной из областей Data Science.
Давайте рассмотрим создание простой прогнозной модели на основе линейного тренда с помощью эконометрических методов.
Возьмем некоторый набор данных (можно найти в репозитории Github, ссылка в конце статьи). Примем, что генезис не имеет значения (прим. автора – происхождение), но учтем, что данные имеют нормальное распределение:
Как понять, что выборка данных принадлежит определенному распределению? Есть 2 метода: аналитический тест Колмогорова-Смирнова (тест Шапиро-Уилка для нормального) и графический метод при помощи графика квантиль-квантиль плот.
Чем так замечателен второй вариант? Он позволяет делать выводы, не основываясь на таких спорных показателях как.
Графический метод является мощнейшим инструментом анализа, но как сказано в англоязычной статье википедии про Q-Q Plots, требует серьезных навыков для интерпретации. В данной статье я представляю дорожную карту пути к пониманию квантильных графиков.
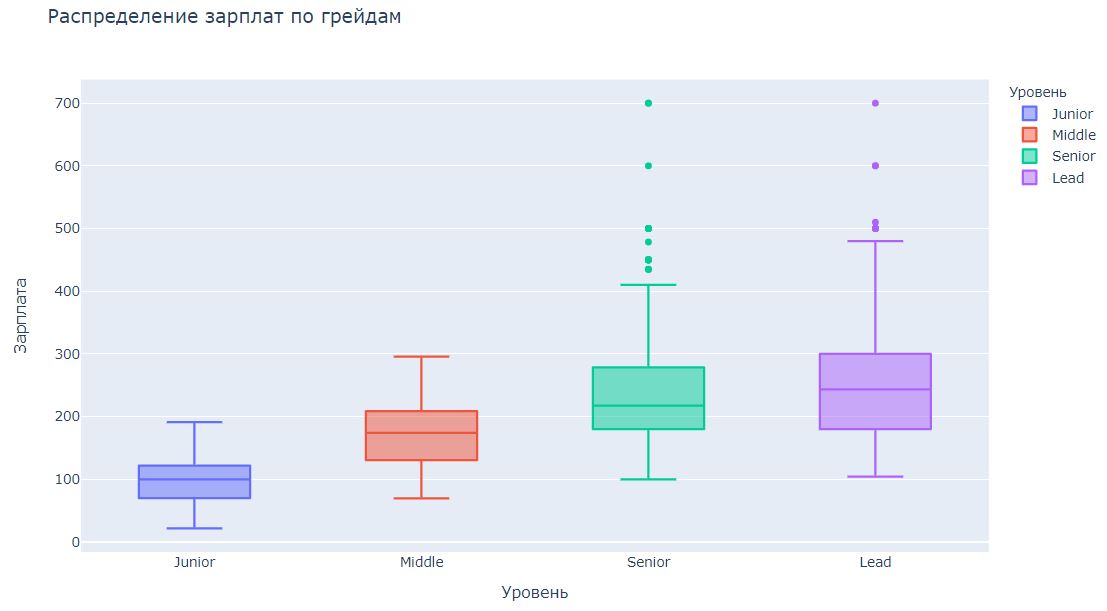
Делимся нашим исследованием вакансий и зарплат в сфере data science и data engineering. Спрос на специалистов растет, или рынок уже насытился, какие технологии теряют, а какие набирают популярность, размер зарплатных вилок и от чего они зависят?
Для анализа мы использовали вакансии, публикуемые в сообществе ODS. По правилам сообщества все вакансии должны иметь зарплатную вилку от и до и подробное описание вакансии - есть что анализировать. К статье прилагается репозиторий с ноутбуком и исходными данными.
Особенности Python, о которых я даже не подозревал
Автор оригинала: Чарудатта Манваткар
В последнее время у меня появилось новое хобби – чтение документации Python просто для удовольствия! Когда вы читаете на досуге, то, как правило, замечаете интересные «лакомые кусочки», которые пропустили бы в противном случае. Итак, вот перечень «кусочков», которые заставили меня сказать:
Поговорим не про еду, а про разведочный анализ данных (exploratory data analysis, EDA) который является обязательной прелюдией перед любым суровым ML.
Будем честны, процесс довольно занудный, и чтобы выцепить хоть какие-то значимые инсайты про наши данные — требуется потратить достаточное количество времени активно используя любимую библиотеку визуализации.
А теперь представим что мы довольно ленивы (но любопытны) и будем следовать этому постулату всю эту статью.
Машинное обучение все чаще используется аналитиками для упрощения работы при решении текущих задач, для реализации новых проектов или для выявления каких-либо ошибок и отклонений.
На данный момент одной из лидеров в машинном обучении для многих задач является библиотека XGBoost, основанная на алгоритме дерева решений и реализующая методы градиентного бустинга. Почему? Библиотека наиболее эффективна при построении моделей предсказания на структурированных больших данных, XGBoost поддерживает реализацию на Hadoop, имеется встроенная регуляризация и правила для обработки пропущенных значений, а также с помощью множества настроек можно улучшать качество прогнозирования модели за кратчайшие сроки, ведь имеется возможность параллельной обработки.
*фарм — (от англ. farming) — долгое и занудное повторение определенных игровых действий с определенной целью (получение опыта, добыча ресурсов и др.).
Введение
Недавно (1 октября) стартовала новая сессия прекрасного курса по DS/ML (очень рекомендую в качестве начального курса всем, кто хочет, как это теперь называется, "войти" в DS). И, как обычно, после окончания любого курса у выпускников возникает вопрос — а где теперь получить практический опыт, чтобы закрепить пока еще сырые теоретические знания. Если вы зададите этот вопрос на любом профильном форуме, то ответ, скорее всего, будет один — иди решай Kaggle. Kaggle — это да, но с чего начать и как наиболее эффективно использовать эту платформу для прокачки практических навыков? В данной статье автор постарается на своем опыте дать ответы на эти вопросы, а также описать расположение основных грабель на поле соревновательного DS, чтобы ускорить процесс прокачки и получать от этого фан.




 .
.