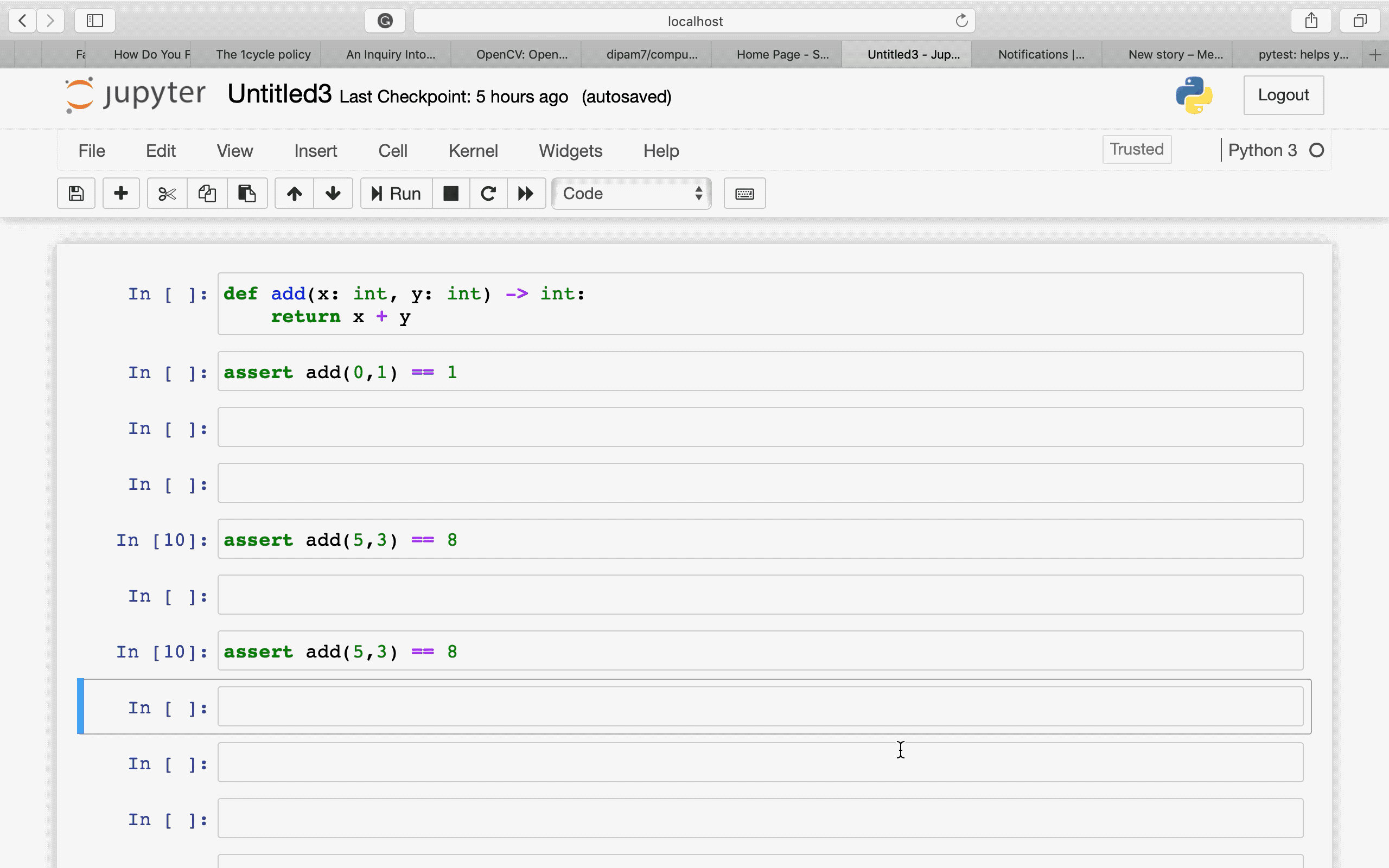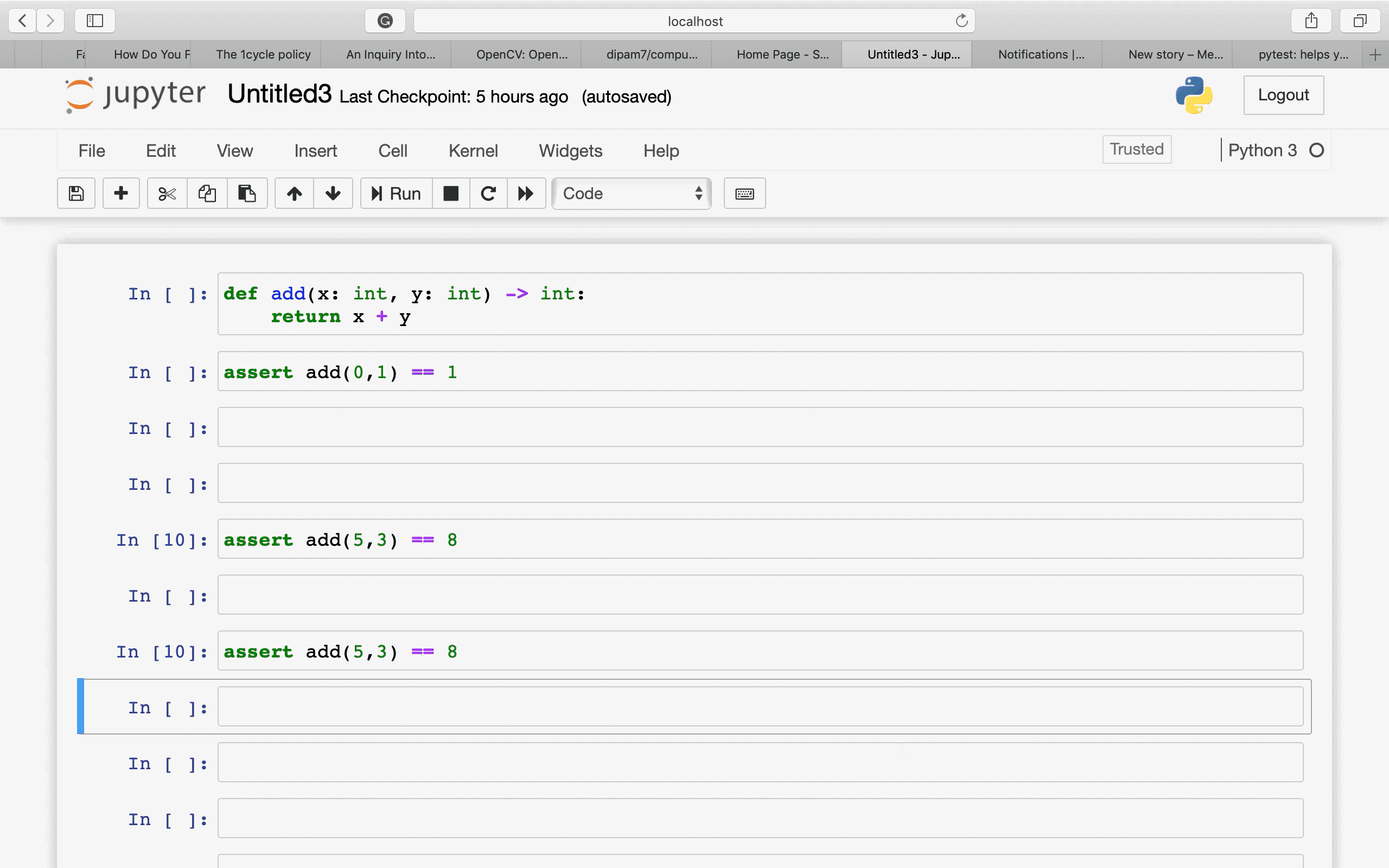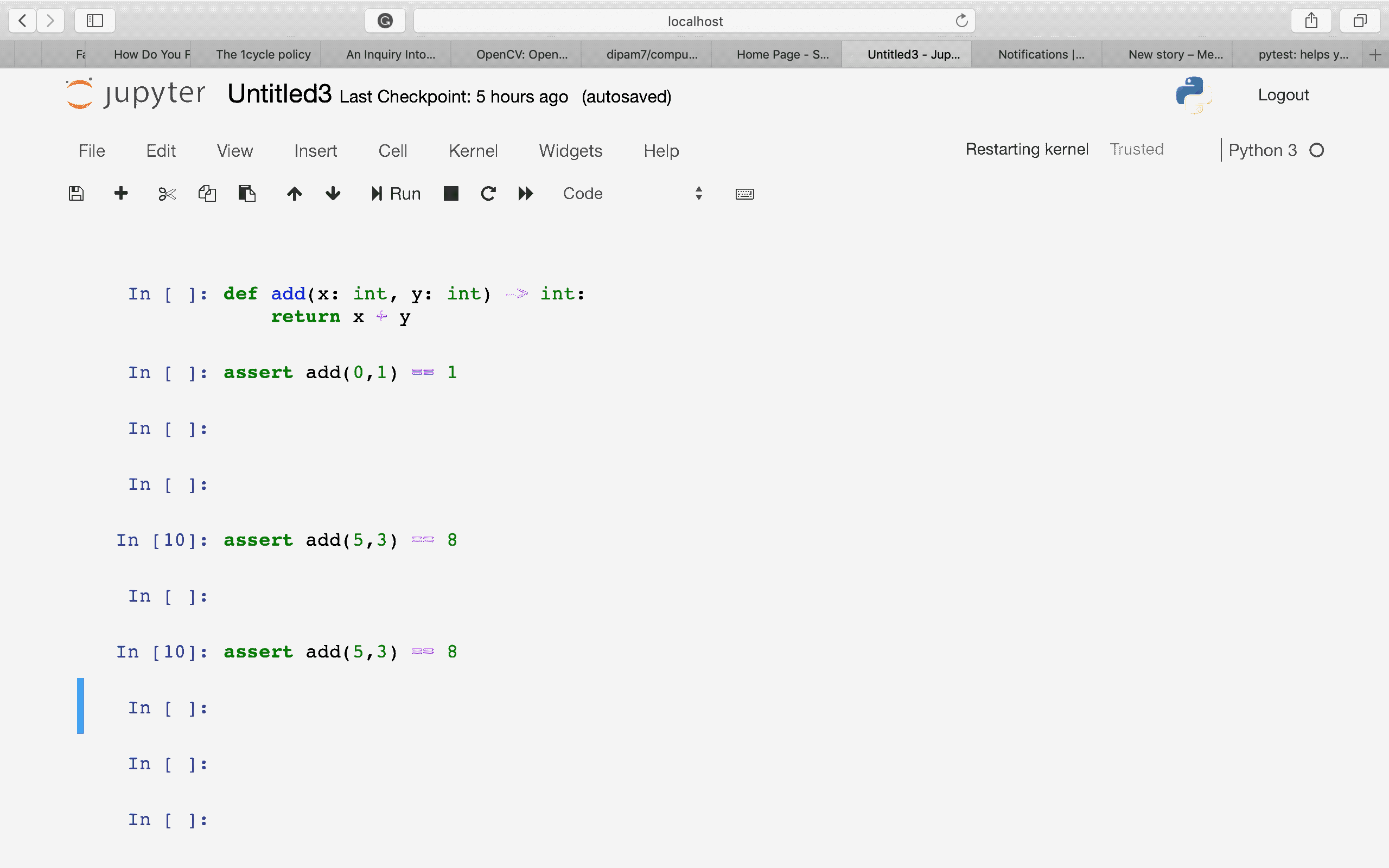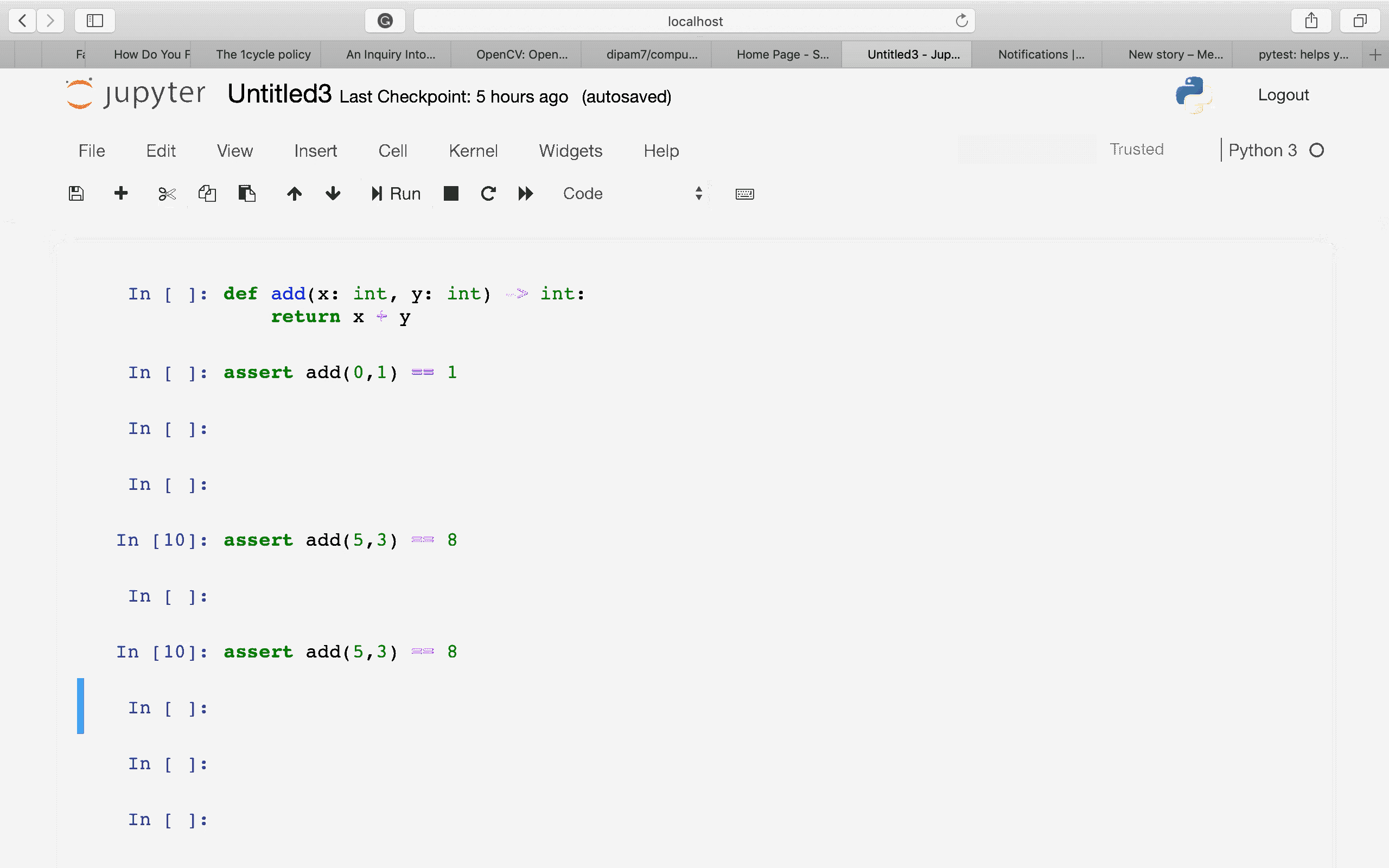
Нельзя доверять коду, который вы не написали полностью сами. — Кен ТомпсонПожалуй, моя самая любимая цитата. Именно она и стала причиной по которой я решил нырнуть в самую глубь кроличьей норы. Свой путь в мир программирования я начал совсем недавно, прошло всего около месяца и я решил писать статьи для закрепления материала. Все началось с простой задачи, синхронизировать лампы в своей фото студии с помощью Ардуины. Задача была решена, но в фото студию я больше не заходил, времени нет. С того момента я решил основательно заняться программированием микроконтроллеров. Ардуина, хоть и привлекательна в своей простоте, как платформа мне не понравилась. Выбор пал на компанию ST и их популярную продукцию. В тот момент я еще не представлял в чем особо разница, но как типичный потребитель я сравнил скорость «процессора» и количество памяти, купил себе внушительную плату с дисплеем STM32F746NG — Discovery. Я пропущу моменты отчаяния и сразу перейду к делу.
STM32 Часть 1: Основы
4 min




:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/66094188/Screen_Shot_2020_01_13_at_2.27.18_PM.0.png)