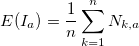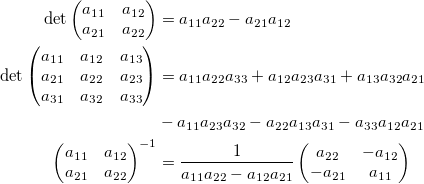Этой весной мы получили разрешение на эксплуатацию нашего нового дата-центра. Первого, для которого всё, даже здание, команда Яндекса спроектировала и построила с нуля. За те 18 лет, которые люди ищут в интернете Яндексом, мы прошли большой путь от сервера под столом одного из наших разработчиков до постройки дата-центра, где используем оборудование собственной разработки. По дороге у нас появилось несколько дата-центров в России, в которые мы перестроили прекратившие когда-то свою работу заводы и цеха.

Когда мы выбирали место, где можно строить дата-центр с нуля, холодный климат был одним из важнейших факторов. Но именно в процессе этой стройки мы нашли технологическое решение, которое позволяет нам эксплуатировать ДЦ в более теплом климате. Сейчас мы планируем построить наш следующий дата-центр во Владимирской области. И теперь у нас есть все возможности создать в России дата-центр, который станет одним из самых передовых в мире.
В этом посте мы хотим рассказать, как мы проектировали ДЦ, с какими сложностями столкнулась наша команда в процессе строительства, как проходила пуско-наладка, в чем особенности дата-центров Яндекса и как устроена рекуперация тепла, о которой вы уже могли слышать.
Когда мы выбирали место, где можно строить дата-центр с нуля, холодный климат был одним из важнейших факторов. Но именно в процессе этой стройки мы нашли технологическое решение, которое позволяет нам эксплуатировать ДЦ в более теплом климате. Сейчас мы планируем построить наш следующий дата-центр во Владимирской области. И теперь у нас есть все возможности создать в России дата-центр, который станет одним из самых передовых в мире.
В этом посте мы хотим рассказать, как мы проектировали ДЦ, с какими сложностями столкнулась наша команда в процессе строительства, как проходила пуско-наладка, в чем особенности дата-центров Яндекса и как устроена рекуперация тепла, о которой вы уже могли слышать.

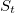 . Рассчитаем логарифмические отношения:
. Рассчитаем логарифмические отношения: 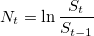
 на
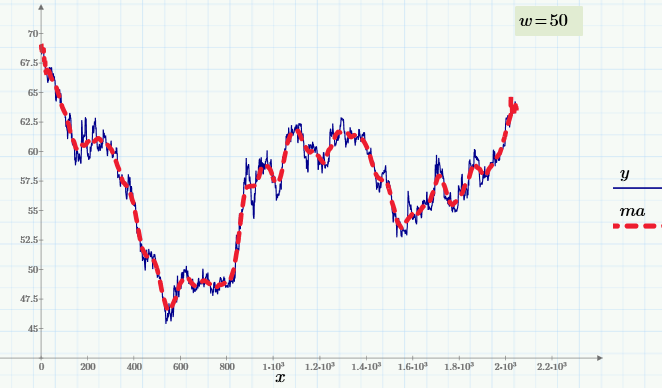
на 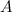 смежных периодов длиной
смежных периодов длиной 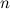 . Отметим каждый период как
. Отметим каждый период как 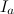 , где
, где 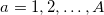 . Определим для каждого
. Определим для каждого