Привет ребят, давайте для начала проверим вашу память. Итак:
 А теперь, внимание, вопрос — как это формализовать?
А теперь, внимание, вопрос — как это формализовать?
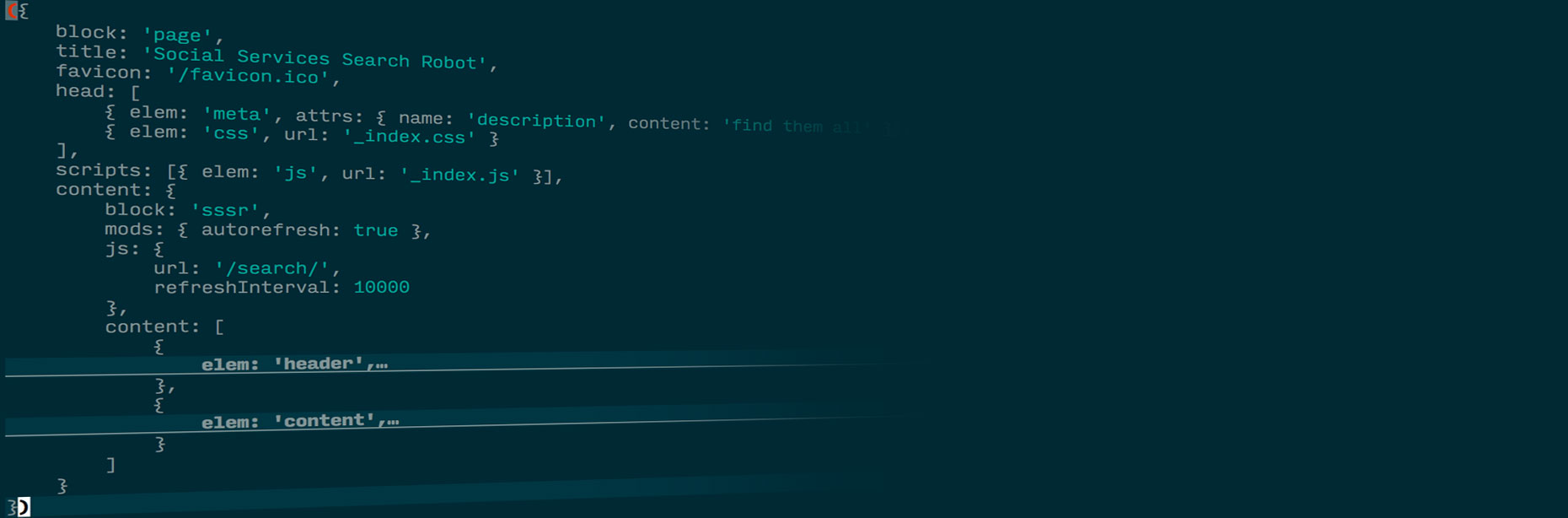
Как приатачить к яйцу иголку и какова временная сложность детача смертии моей. Как перенести сказку в быль, как это выглядит на B-деревьях и почему на самом деле нет разницы между 2D и 1D.
А было все так: давным давно, в неком царстве, некотором государстве, на одном сервисе с шейрингом геолокации очень захотелось Иванушке Дурачку на уровне ЧПУ разделить Москву(/RU/MOW/) и Область(/RU/MOS/). И вообще навести порядок, чтобы все лежало по полочкам красиво и по алфавиту. Но не получалось ему сокровища свои посчитать, и аккуратно разложить. А Василису, хоть и дурак, к сбережениям не пускал.
Но решение было найдено.
Совсем недалеко над каким-то златом успешно чах Чахлик, еще и смерть он свою прятал по науке.
И если задача определения региональной (точнее полигональной) принадлежности некой иголки к некому сундуку выходит за рамки данной статьи, то нам ничто не мешает погрузиться в глубины зайца и посмотреть как он устроен на табличном уровне.
PS: и не спрашивайте почему зайца.
«На море на океане есть остров, на том острове дуб стоит, под дубом сундук зарыт, в сундуке — заяц, в зайце — утка, в утке — яйцо» в яйце игла — смерть Кощея!
А теперь, внимание, вопрос — как это формализовать? Как приатачить к яйцу иголку и какова временная сложность детача смертии моей. Как перенести сказку в быль, как это выглядит на B-деревьях и почему на самом деле нет разницы между 2D и 1D.
А было все так: давным давно, в неком царстве, некотором государстве, на одном сервисе с шейрингом геолокации очень захотелось Иванушке Дурачку на уровне ЧПУ разделить Москву(/RU/MOW/) и Область(/RU/MOS/). И вообще навести порядок, чтобы все лежало по полочкам красиво и по алфавиту. Но не получалось ему сокровища свои посчитать, и аккуратно разложить. А Василису, хоть и дурак, к сбережениям не пускал.
Но решение было найдено.
Совсем недалеко над каким-то златом успешно чах Чахлик, еще и смерть он свою прятал по науке.
И если задача определения региональной (точнее полигональной) принадлежности некой иголки к некому сундуку выходит за рамки данной статьи, то нам ничто не мешает погрузиться в глубины зайца и посмотреть как он устроен на табличном уровне.
PS: и не спрашивайте почему зайца.




 В топике блиц-обзор книг, которые будут полезны IT-специалистам, бизнесменам и тем, кто собирается открыть своё дело. Рядом с каждой — короткие пояснения, почему и зачем стоит прочесть.
В топике блиц-обзор книг, которые будут полезны IT-специалистам, бизнесменам и тем, кто собирается открыть своё дело. Рядом с каждой — короткие пояснения, почему и зачем стоит прочесть.