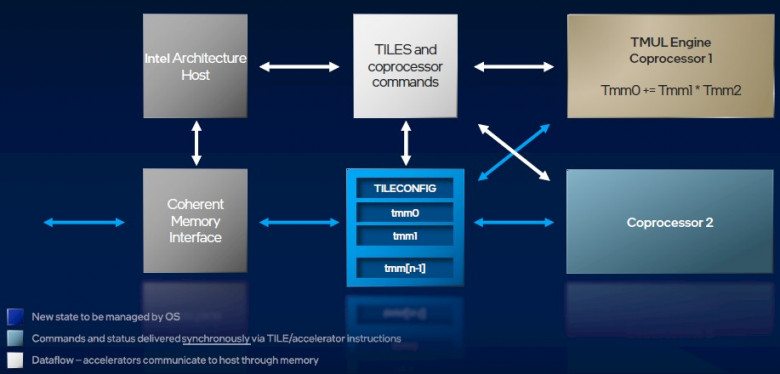
AMX (Advanced Matrix Extension) - это модуль аппаратного ускорения умножения матриц, который появился в серверных процессорах Intel Xeon Scalable, начиная с 4 поколения (архитектура Sapphire Rapids).
В начале этого года ко мне в руки наконец попал сервер, с данным типом процессора.
Конкретно модель Xeon(R) Gold 5412U - это 24 ядерный процессор с тактовой частотой в 2.1 GHz. При этом 8 приоритетных ядер могут разгонятся до 2.3 GHz, а 1 ядро до 3.9 GHz в Turbo Boost). Кроме того данный процессор поддерживает 8 канальную DDR-5 4400 MT/s.
Мне как человеку, достаточно долгое время посвятившему оптимизации алгоритмов компьютерного зрения и запуска нейронный сетей на CPU (библиотеки Simd и Synet), было интересно: на сколько AMX позволяет реально ускорить вычисления и как извлечь из него максимальную производительность.
Далее я постараюсь максимально подробно ответить на данные вопросы. Прежде все я буду касаться вопросов однопоточной производительности (многопоточную рассмотрю позже).