
David Drysdale, Beginner's guide to linkers (http://www.lurklurk.org/linkers/linkers.html).
Цель данной статьи — помочь C и C++ программистам понять сущность того, чем занимается компоновщик. За последние несколько лет я объяснил это большому количеству коллег и наконец решил, что настало время перенести этот материал на бумагу, чтоб он стал более доступным (и чтоб мне не пришлось объяснять его снова). [Обновление в марте 2009: добавлена дополнительная информация об особенностях компоновки в Windows, а также более подробно расписано правило одного определения (one-definition rule).
Типичным примером того, почему ко мне обращались за помощью, служит следующая ошибка компоновки:
Если Ваша реакция — 'наверняка забыл extern «C»', то Вы скорее всего знаете всё, что приведено в этой статье.
Цель данной статьи — помочь C и C++ программистам понять сущность того, чем занимается компоновщик. За последние несколько лет я объяснил это большому количеству коллег и наконец решил, что настало время перенести этот материал на бумагу, чтоб он стал более доступным (и чтоб мне не пришлось объяснять его снова). [Обновление в марте 2009: добавлена дополнительная информация об особенностях компоновки в Windows, а также более подробно расписано правило одного определения (one-definition rule).
Типичным примером того, почему ко мне обращались за помощью, служит следующая ошибка компоновки:
g++ -o test1 test1a.o test1b.o
test1a.o(.text+0x18): In function `main':
: undefined reference to `findmax(int, int)'
collect2: ld returned 1 exit status
Если Ваша реакция — 'наверняка забыл extern «C»', то Вы скорее всего знаете всё, что приведено в этой статье.

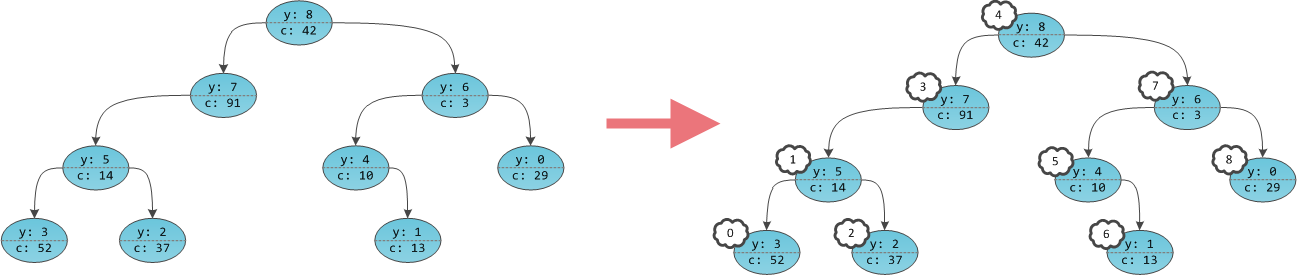
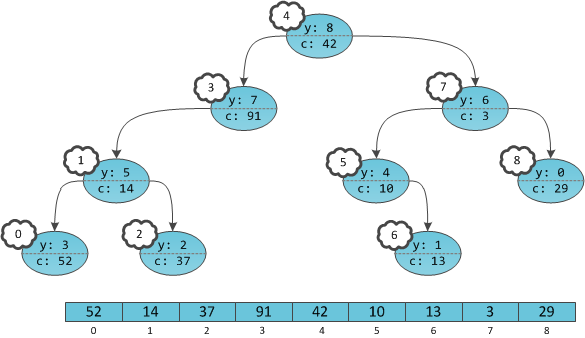
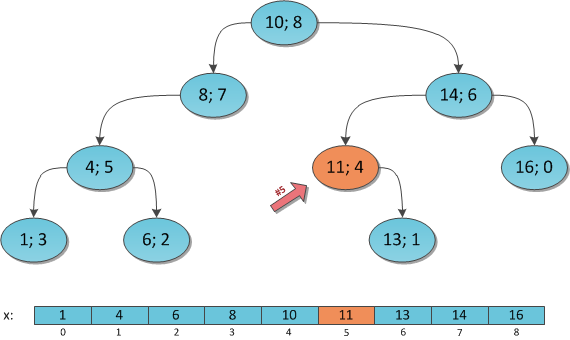

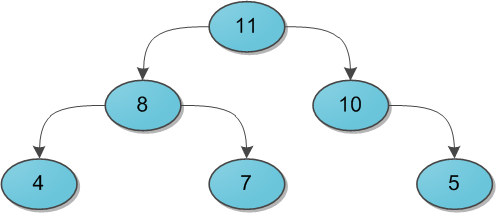
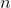 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 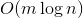 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 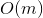 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.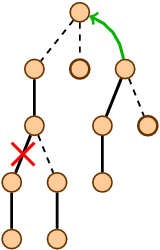 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 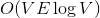 и
и 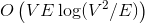 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.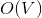 памяти и
памяти и 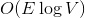 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.




