Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Очень сильное колдунство
После всей кучи возможностей, которые нам предоставило декартово дерево в предыдущих двух частях, сегодня я совершу с ним нечто странное и кощунственное. Тем не менее, это действие позволит рассматривать дерево в совершенно новой ипостаси — как некий усовершенствованный и мощный массив с дополнительными фичами. Я покажу, как с ним работать, покажу, что все операции с данными из второй части сохраняются и для модифицированного дерева, а потом приведу несколько новых и полезных.
Вспомним-ка еще раз структуру дерамиды. В ней есть ключ x, по которому дерамида есть дерево поиска, случайный ключ y, по которому дерамида есть куча, а также, возможно, какая-то пользовательская информация с (cost). Давайте совершим невозможное и рассмотрим дерамиду… без ключей x. То есть у нас будет дерево, в котором ключа x нет вообще, а ключи y — случайные. Соответственно, зачем оно нужно — вообще непонятно :)
На самом деле расценивать такую структуру стоит как декартово дерево, в котором ключи x все так же где-то имеются, но нам их не сообщили. Однако клянутся, что для них, как полагается, выполняется условие двоичного дерева поиска. Тогда можно представить, что эти неизвестные иксы суть числа от 0 до
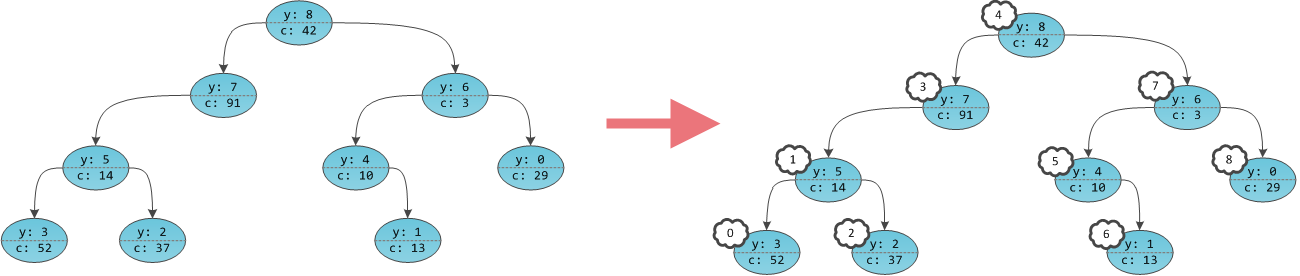
Получается, что в дереве будто бы не ключи в вершинах проставлены, а сами вершины пронумерованы. Причем пронумерованы в уже знакомом с прошлой части порядке in-order обхода. Дерево с четко пронумерованными вершинами можно рассматривать как массив, в котором индекс — это тот самый неявный ключ, а содержимое — пользовательская информация
c. Игреки нужны только для балансировки, это внутренние детали структуры данных, ненужные пользователю. Иксов на самом деле нет в принципе, их хранить не нужно.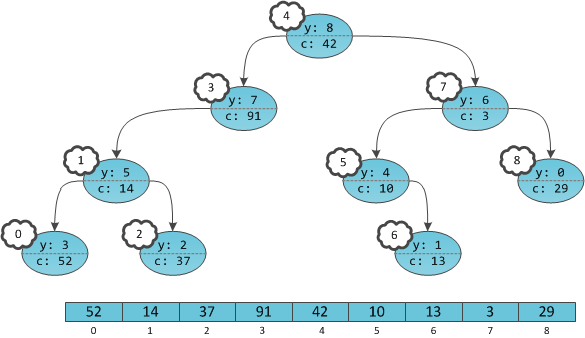
В отличие от прошлой части, этот массив не приобретает автоматически никаких свойств, вроде отсортированности. Ведь на информацию-то у нас нет никаких структурных ограничений, и она может храниться в вершинах как попало.
Главные применения
Теперь стоит поговорить о том, зачем такая трактовка вообще нужна.
Например, вам никогда не хотелось слить два массива? То есть просто приписать один из них в конец другого, при этом не копируя в цикле все элементы второго за O(N). С декартовым деревом по неявному ключу у вас такая возможность есть: ведь операцию Merge у нас никто не отбирал.
Стоп-стоп-стоп, но Merge ведь была написана для явного декартового дерева. Значит, её алгоритм придется здесь переработать? На самом деле нет. Посмотрите еще раз на её код.
public static Treap Merge(Treap L, Treap R) { if (L == null) return R; if (R == null) return L; if (L.y > R.y) { var newR = Merge(L.Right, R); return new Treap(L.x, L.y, L.Left, newR); } else { var newL = Merge(L, R.Left); return new Treap(R.x, R.y, newL, R.Right); } }
Операция Merge, как вы помните, полагается на то, что все ключи левого входного дерева L не превосходят ключей правого входного дерева R. В предположении, что это условие выполняется, она производит слияние, не обращая внимания на ключи в принципе: в процессе выполнения алгоритма сравниваются лишь приоритеты.
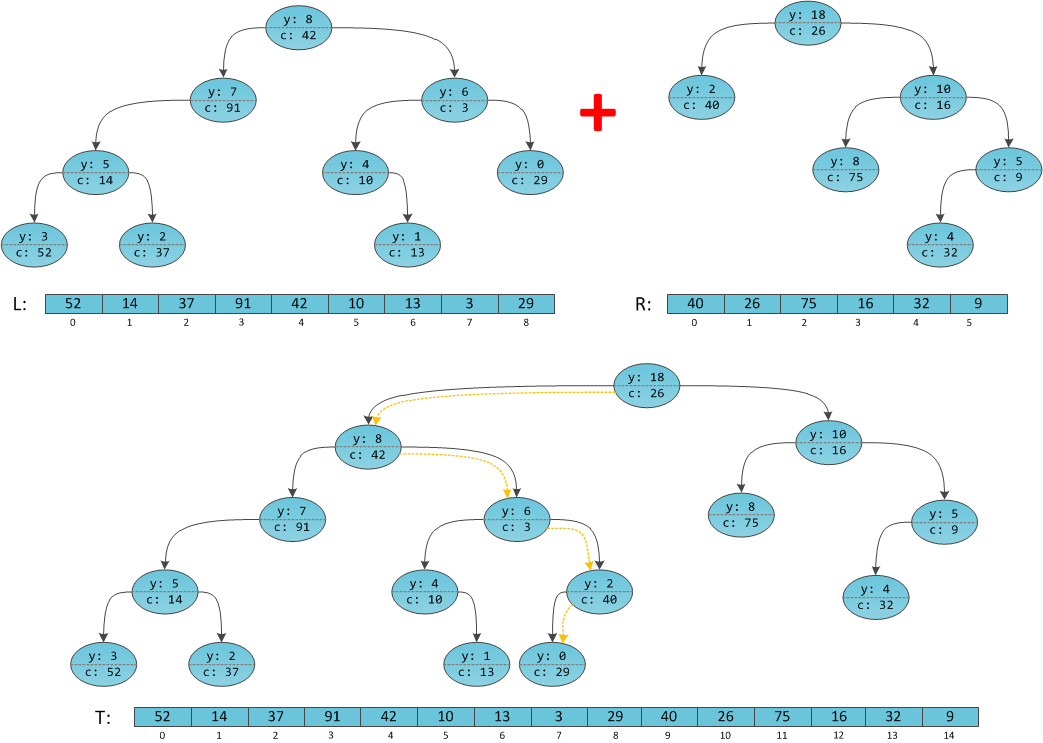
Получается, что операцию Merge мы с вами здесь обманываем самым наглым образом: она рассчитывает, что ей дадут деревья с упорядоченными ключами, а мы ей подсовываем деревья вообще без ключей :) Однако предположение что в деревьях есть явные ключи, и они упорядочены, заставит её слить деревья так, что ключи L окажутся по структуре дерева в некотором смысле раньше, чем ключи R — ведь условие дерева поиска должно выполняться. То есть: если в дереве L было N элементов, а в дереве R, соответственно, M элементов, то после слияния элементы дерева R автоматически приобретут неявные номера от N до
Что касается исходников, нам потребуется лишь завести новый тип данных
ImplicitTreap без ключа x, и для него соответствующий приватный конструктор. Весь код Merge останется таким же. Разумеется, это если учитывать, что здесь приведена версия без вычисления множественных запросов — функции «восстановления справедливости» и «проталкивания обещаний», реализованные во второй части, также останутся в Merge на своих старых местах.Для полной ясности я возьму два случайных неявных декартовых дерева и приведу их на рисунке вместе с результатом слияния. Приоритеты выбраны случайно, поэтому реальная структура обоих деревьев и результата может сильно отличаться. Но это неважно — структура массива, т.е. порядок следования элементов
c, всегда сохраняется.Оранжевая стрелка — путь следования рекурсии в Merge.
Теперь настала пора Split. Ее так просто обмануть уже не получится: операцию Split, наоборот, не интересуют приоритеты, она сравнивает лишь ключи. Придется задуматься, как она будет сравнивать вершины в неявном дереве. Хотя на самом деле проблема лежит выше: а что вообще выполняет в новой структуре данных операция Split? Раньше она разрезала дерево по ключу, но здесь у нас и ключей-то нет, по которым требуется разрезать.
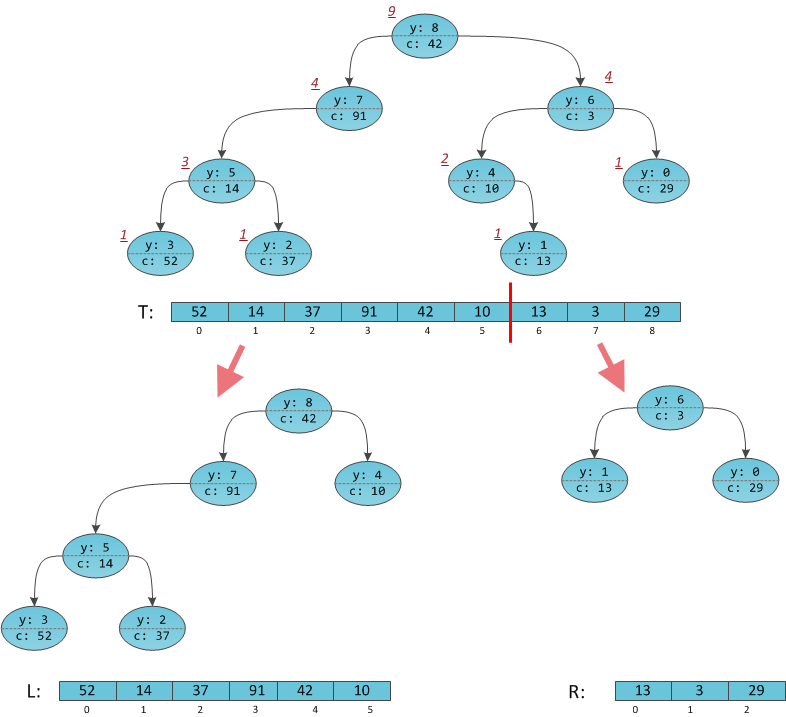
Ключей нет, однако есть их неявное представление — индексы массива. Таким образом, суть разрезания несколько изменилась: мы хотим расщепить дерево на два так, чтобы в левом оказалось ровно x0 элементов, а в правом — все остальные. В «массивной» трактовке это означает отделение от массива x0 элементов с начала в новый массив.
Как выполнить новую операцию Split? Она рассматривает, как и раньше, два случая: корень T окажется в левом результате L либо в правом R. В левом он окажется, если его индекс в массиве меньше x0, в противном случае — в правом. А что такое индекс вершины дерева в массиве? Мы ведь с ним уже умеем работать со второй части: достаточно хранить в вершинах дерева размеры поддеревьев. Тогда процесс выбора легко восстанавливается.
Пусть SL — размер левого поддерева (
T.Left.Size).Если
Если
На рисунке взято декартово дерево с проставленными размерами поддеревьев и расщеплено по
Исходный код нового Split, вместе с новой заготовкой класса — без ключа и с другим приватным конструктором.
Split даю снова пока что без множественных операций — читатель может восстановить эти строчки самостоятельно, они со своих старых мест никуда не подевались. Зато нельзя забывать о пересчете размеров поддеревьев.
private int y; public double Cost; public ImplicitTreap Left; public ImplicitTreap Right; public int Size = 1; private ImplicitTreap(int y, double cost, ImplicitTreap left = null, ImplicitTreap right = null) { this.y = y; this.Cost = cost; this.Left = left; this.Right = right; } public static int SizeOf(ImplicitTreap treap) { return treap == null ? 0 : treap.Size; } public void Recalc() { Size = SizeOf(Left) + SizeOf(Right) + 1; } // теперь после заготовки - собственно Split public void Split(int x, out ImplicitTreap L, out ImplicitTreap R) { ImplicitTreap newTree = null; int curIndex = SizeOf(Left) + 1; if (curIndex <= x) { if (Right == null) R = null; else Right.Split(x - curIndex, out newTree, out R); L = new ImplicitTreap(y, Cost, Left, newTree); L.Recalc(); } else { if (Left == null) L = null; else Left.Split(x, out L, out newTree); R = new ImplicitTreap(y, Cost, newTree, Right); R.Recalc(); } }
Теперь, после того как мы написали для массива Split и Merge, работающие за логарифмическое время, настала пора их где-нибудь применить. Давайте поиграемся с массивом.
Игры с массивом
Вставка
Фокус №1 — мы вставим элемент внутрь массива на требуемую позицию Pos за O(log2 N), а не за O(N), как обычно.
В принципе, мы это уже умеем делать с обычными декартовыми деревьями, только теперь на месте ключа стал индекс. А в остальном процедура не изменилась.
• Разрезаем массив
• Делаем из вставляемого элемента массив-дерево из одной вершины.
• Приписываем созданный массив справа к левому результату L, а к ним обоим — правый результат R.
• Получили массив
Исходный код вставки не изменился совершенно.
public ImplicitTreap Add(int pos, double elemCost) { ImplicitTreap l, r; Split(pos, out l, out r); ImplicitTreap m = new ImplicitTreap(rand.Next(), elemCost); return Merge(Merge(l, m), r); }
Удаление
Фокус №2 — вырежем из массива элемент, стоящий на данной позиции Pos.
Опять-таки, процедура та же, что и с обычными декартовыми деревьями.
• Разрезаем массив
• Правый результат R разрезаем по индексу 1 (единица!). Получаем массив
• Сливаем массивы L и R'.
Исходный код удаления:
public ImplicitTreap Remove(int pos) { ImplicitTreap l, m, r; Split(pos, out l, out r); r.Split(1, out m, out r); return Merge(l, r); }
Множественные запросы на отрезке
Фокус №3: за O(log2 N) можно также выполнять все те же множественные запросы на подотрезках массива (сумма/максимум/минимум/наличие или количество меток и т.д.).
Структура дерева не меняется с прошлой части: в вершине храним параметр, соответствующий искомой величине, вычисленной для всего подотрезка. В конце Merge и Split вставляется такой же вызов
Recalc(), пересчитывающий значение величины в вершине на основании вычисленных параметров в ее потомках.Запрос на отрезке
Исходный код — как пример, для максимума.
public double MaxTreeCost; public static double CostOf(ImplicitTreap treap) { return treap == null ? double.NegativeInfinity : treap.MaxTreeCost; } public void Recalc() { Size = SizeOf(Left) + SizeOf(Right) + 1; MaxTreeCost = Math.Max(Cost, Math.Max(CostOf(Left), CostOf(Right))); } public double MaxCostOn(int A, int B) { ImplicitTreap l, m, r; this.Split(A, out l, out r); r.Split(B - A, out m, out r); return CostOf(m); }
Множественные операции на отрезке
Фокус №4: теперь за O(log2 N) мы будем на подотрезках массива выполнять операции из второй части: прибавление константы, покраску, установку в единое значение и т.д.
Имея рабочие Merge и Split, реализация отложенных вычислений в декартовом дереве совершенно не меняется. Основный принцип работы тот же: перед выполнением любой операции «протолкнуть обещание» потомкам. Если дополнительно нужно поддерживать еще и множественные запросы из предыдущего раздела, после выполнения операции необходимо «восстановить справедливость».
Для выполнения операции на отрезке нужно этот отрезок сначала вырезать из дерева двумя вызовами Split, а потом снова вставить его двумя вызовами Merge.
Для ленивых привожу полный исходный код для прибавления, вместе с новыми реализациями Merge/Split (они отличаются аж на 1-2 строки), а также с функцией проталкивания
Push:public double Add; public static void Push(ImplicitTreap treap) { if (treap == null) return; treap.Cost += treap.Add; if (treap.Left != null) treap.Left.Add += treap.Add; if (treap.Right != null) treap.Right.Add += treap.Add; treap.Add = 0; } public void Recalc() { Size = SizeOf(Left) + SizeOf(Right) + 1; } public static ImplicitTreap Merge(ImplicitTreap L, ImplicitTreap R) { // проталкивание! Push( L ); Push( R ); if (L == null) return R; if (R == null) return L; ImplicitTreap answer; if (L.y > R.y) { var newR = Merge(L.Right, R); answer = new ImplicitTreap(L.y, L.Cost, L.Left, newR); } else { var newL = Merge(L, R.Left); answer = new ImplicitTreap(R.y, R.Cost, newL, R.Right); } answer.Recalc(); return answer; } public void Split(int x, out ImplicitTreap L, out ImplicitTreap R) { Push(this); // проталкивание! ImplicitTreap newTree = null; int curIndex = SizeOf(Left) + 1; if (curIndex <= x) { if (Right == null) R = null; else Right.Split(x - curIndex, out newTree, out R); L = new ImplicitTreap(y, Cost, Left, newTree); L.Recalc(); } else { if (Left == null) L = null; else Left.Split(x, out L, out newTree); R = new ImplicitTreap(y, Cost, newTree, Right); R.Recalc(); } } public ImplicitTreap IncCostOn(int A, int B, double Delta) { ImplicitTreap l, m, r; this.Split(A, out l, out r); r.Split(B - A, out m, out r); m.Add += Delta; return Merge(Merge(l, m), r); }
Небольшое отступление про разрешенные операции:
Фактически, рекурсивная структура дерева и отложенные вычисления позволяют реализовать любую операцию моноида. Моноид — множество с заданной на нем бинарной операцией ◦, которая обладает следующими свойствами:
• Ассоциативность — для любых элементов a, b, c имеем(a ◦ b) ◦ c = a ◦ (b ◦ c) .
• Существование нейтрального элемента — в множестве есть такой элемент e, что для любого элемента a имеет местоa ◦ e = e ◦ a = a .
Тогда для такой операции возможно реализовать дерево отрезков, и по аналогичным причинам — декартово дерево.
Переворот массива
Фокус № 5 — переворот подотрезка, то есть перестановка его элементов в обратном порядке.
А на этом месте я остановлюсь чуть поподробнее. Разворот массива не является моноидальной операцией — откровенно говоря, это вообще не бинарная операция на каком бы то ни было множестве — но тем не менее. Уникальность этой задачи в том, что для неё можно придумать функцию проталкивания. А раз существует возможность протолкнуть операцию — значит, можно реализовать её как отложенную.
Итак, будем хранить в каждой вершине булево значение — бит перевернутости. Это будет отложенное обещание «данный отрезок массива в будущем необходимо развернуть». Тогда, в предположении что мы умеем проталкивать этот бит к потомкам своеобразной версией функции
Push, дерево всегда остается в актуальном виде — перед любыми операциями доступа к элементам массива (поиск), а также в начале Merge и Split выполняется проталкивание. Осталось выяснить, как производить это «выполнение обещания».Пусть в некоторой вершине T стоит обещание о переворачивании подотрезка. Чтобы его начать фактически выполнять, достаточно сделать следующее:
• Снять обещание в текущей вершине:
T.Reversed = false;• Поменять местами его левого и правого сыновей.
temp = T.Left; T.Left = T.Right; T.Right = temp;• Изменить обещание у потомков. Обратите внимание: не установить в true (мы не знаем, стоял ли этот бит у потомков до сих пор!), а изменить. Для этого используется операция ^.
T.Left.Reversed ^= true; T.Right.Reversed ^= true;
Действительно, что такое «фактически перевернуть массив»? Возьмем два куска этого массива (поддеревья), поменяем их местами в реальности, и пообещаем перевернуть эти два подмассива в будущем. Нетрудно заметить, что, когда все обещания таки исполнятся до единого, элементы исходного массива окажутся в перевернутом порядке.
Заметьте — с обычными декартовыми деревьями такую махинацию проводить нельзя, поскольку мы нарушаем свойство дерева поиска — ключи в правом поддереве оказываются меньше ключей в левом. Но поскольку в неявном декартовом дереве ключей нет вообще, а для индексов свойство соблюдается всегда, то в дереве ничего не ломается.
Пользовательская функция переворачивания отрезка работает по неизменному принципу, как и любая другая операция: вырезать требуемый отрезок, установить в его корне обещание, и вклеить отрезок обратно. Вот исходный код функций проталкивания и переворачивания:
public bool Reversed; public static void Push(ImplicitTreap treap) { if (treap == null) return; // не установленное обещание - не проталкивается if (!treap.Reversed) return; var temp = treap.Left; treap.Left = treap.Right; treap.Right = temp; treap.Reversed = false; if (treap.Left != null) treap.Left.Reversed ^= true; if (treap.Right != null) treap.Right.Reversed ^= true; } public ImplicitTreap Reverse(int A, int B) { ImplicitTreap l, m, r; this.Split(A, out l, out r); r.Split(B - A, out m, out r); m.Reversed ^= true; return Merge(Merge(l, m), r); }
Теперь вы можете решать классическое задание на собеседованиях принципиально новым способом :)
Циклический сдвиг массива
Фокус №6: циклический сдвиг. Суть этой операции, для тех, кто не знает, проще пояснить на рисунке.

Разумеется, циклический сдвиг всегда можно выполнить за O(N), но, реализовав массив как неявное декартово дерево, вы сможете сдвигать его за O(log2 N). Процедура сдвига влево на K банальна: разрезаем дерево по индексу K, и склеиваем его в обратном порядке. Сдвиг вправо симметричен, только разрезать нужно по индексу
public ImplicitTreap ShiftLeft(int K) { ImplicitTreap l, r; this.Split(K, out l, out r); return Merge(r, l); }
Опять-таки: операция уникальная для декартовых деревьев по неявному ключу, поскольку склеивать два результата Split, будь они обычными декартовыми деревьями, недопустимо: ведь Merge ожидает от нас упорядоченные деревья, а мы скармливаем ему аргументы в неверном порядке.
Резюме
Декартово дерево по неявному ключу — простое представление массива в виде дерева, которое позволяет производить с ним и с его подмассивами кучу операций за логарифмическое время. Памяти при этом тратится все так же O(N). Конечно, использовав O-нотацию, я здесь слегка покривил душой, ведь в реальной жизни важна фактическая память, занимаемая деревом, а декартово дерево славится своим overhead`ом. Судите сами: N на информацию, N на приоритеты, 2N на ссылки на потомков, N на размеры поддеревьев — это прожиточный минимум, а если добавить еще и множественные запросы, то получим еще N на каждую операцию. Можно чуточку улучшить себе жизнь, создавая приоритеты из информации, однако это, во-первых, капля в море (всего лишь минус N), а во-вторых, чревато последствиями с точки зрения безопасности: если некто выяснит функцию, с помощью которой вы создаете приоритеты, то он будет потенциально способен подавать вам новые записи для создания в зловредном порядке, чтобы сильно разбалансировать декартово дерево. В конечном итоге возможна ситуация, когда все ваши данные будут заметно притормаживать — хотя такие случаи, конечно, считанные и требуют недюжинной работы. От опасности можно избавляться, используя разные простые числа P для разных вершин дерева… но это уже тема для отдельного научного исследования. Лично для меня возможности декартового дерева и простота его кода — преимущества, превосходящие проблему большого расхода памяти. Хотя, конечно же, программа программе рознь.
Из интересных фактов: в западной литературе, статьях и Интернете ни одного упоминания о декартовом дереве по неявному ключу мне найти не удалось. Конечно, никто и не знает, как оно должно называться в английской терминологии — однако вопросы на форумах и StackOverflow тоже ни к чему не привели. В русской практике спортивного программирования ACM ICPC эта структура была использована впервые в 2000 году, придуманная членом команды Kitten Computing Николаем Дуровым — многочисленным победителем международных олимпиад (впрочем, рунет больше знает его брата Павла, а также их совместное творение).
Обязательную программу по декартовому дереву я на этом заканчиваю. Скорее всего, попозже будет еще как минимум одна или две части — об альтернативных реализациях операций дерева, и о функциональной его реализации, — однако уже написанные три в принципе составляют достаточный боекомплект для полноценного использования дерамиды в жизни. Спасибо всем, кто честно продирался со мной сквозь строки этого туториала :) Надеюсь, вам было интересно.
