Привет, Хабр!
Меня зовут Соловьев Андрей, я Java-разработчик в «Рексофт». Сегодня мы поговорим про Kotlin Coroutines. Это моя первая серьезная публикация, и я буду рад вашему фидбеку.
Ну что ж, давайте начинать!

User
Привет, Хабр!
Меня зовут Соловьев Андрей, я Java-разработчик в «Рексофт». Сегодня мы поговорим про Kotlin Coroutines. Это моя первая серьезная публикация, и я буду рад вашему фидбеку.
Ну что ж, давайте начинать!

Всем привет! Проверяя задания в учебном центре моей компании, обнаружил, что двумя словами описать то, как можно избавиться от ResponseEntity<?> в контроллерах не получится, и необходимо написать целую статью. Для начала, немного введения.
ВАЖНО! Статья написана для новичков в программировании и Spring в частности, которые знакомы со Spring на базовом уровне.

В математике идеальной фигурой является шар. В мире микросервисов близкой к идеальной можно считать шестиугольник. Сегодня мы поговорим о преимуществах и недостатках гексагональной архитектуры, и относительно новой, но перспективной библиотеке Hexagon для Kotlin, предоставляющей базовую функциональность для создания веб-приложений и API, разрабатываемых с использованием гексагональной архитектуры. В результате мы разработаем общую архитектуру и несколько компонентов некоторого идеального приложения для ведения домашней бухгалтерии и автоматизации оплаты счетов и налогов.
Сказ о том как сделать свой List<?>, который будет быстрее ArrayList и занимать меньше памяти.

В этой статье я хочу исследовать возможности технологии Java Native Image, поделиться опытом взаимодействия с ней и со средствами Spring для генерации нативных образов.
Добро пожаловать в статью о миграции приложения Spring Boot на Java 17.
В первый день мы пытались использовать Java 17 со Spring Boot и завершили день компиляцией нашего кода и зелеными юнит тестами.
В этом посте мы рассмотрим миграции: Spring Cloud, Spring Data, Spring Kafka

В этой статье поговорю про основы работы с Postman для начинающих тестировщиков. Сама я столкнулась с этим инструментом как раз на последнем проекте.
Расскажу, как с его помощью создавать простейшие автотесты и уменьшать объем рутины с помощью переменных.

Современное представление о REST сильно отличается от концепции архитектурного стиля, описанной в диссертации его создателя, Роя Филдинга. В этой статье разберемся, как ограничения REST понимал их автор.

Одним из главных требований к каталогу является возможность быстро искать и находить его элементы по различным критериям.
Существует множество подходов к реализации таких требований. Это и nosql решения и механизмы работы с json в реляционных СУБД. До nosql эпохи, решать такие задачи приходилось средствами реляционных БД.
Основная причина по которой реляционные СУБД плохо подходят для решения таких задач это разнообразие характеристик товаров. Набор характеристик к примеру для одежды и смартфонов будет совершенно разный. В самом деле не создавать же для каждой категории товаров отдельную таблицу с со своим набором реквизитов.
По этой причине в большинстве случаев в реляционных БД используется EAV (Entity Attribute Value) модель данных в тех или иных вариациях.
Недостатков у такой модели множество. Чаще всего EAV модель критикуют чрезмерную сложность, так же за то, что по сути схема данных храниться в самих данных.
Есть мнение, что EAV вообще является анти паттерном, что тоже не лишено оснований, однако надо заметить, что есть и другое мнение, что лучше такая схема, чем вообще отсутствие таковой.
Рискуя навлечь на себя гнев сообщества хочу представить свой вариант реализации каталога. Это не совсем EAV, скорее его по мотивам.
Я использовал его в различных проектах много лет, его достоинства чрезвычайная простота, действительная универсальность и хорошая скорость выборки, что на первый взгляд не кажется очевидным.
Всё описанное далее предполагает использование СУБД Postgresql.

Облачные технологии открыли путь к множеству новых практических областей, среди которых есть и такие, которые ранее были совершенно невозможны. Среди них выделяется бессерверная парадигма:
Бессерверные вычисления – это модель выполнения вычислений в облаке, при которой облачный провайдер предоставляет машинные ресурсы по требованию и берет на себя всю работу с серверами, на что его уполномочивает клиент. При бессерверных вычислениях ресурсы не содержатся в энергозависимой памяти; напротив, вычисления выполняются краткими всплесками, после которых результаты сбрасываются в долговременное хранилище. Когда приложение не используется, никаких ресурсов на него не выделяется.
По Википедии
<profile>
<id>deploy-deps</id>
<build>
<plugins>
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<useSubDirectoryPerScope>true</useSubDirectoryPerScope>
<excludeGroupIds>исключаем некоторые группы, попадающие в war-архив</excludeGroupIds>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<executions>
<execution>
<id>05-stop-tomcat</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<arguments>
<argument>-ssh</argument>
<argument>-4</argument>
<argument>-agent</argument>
<argument>-i</argument>
<argument>${putty.key}</argument>
<argument>${ssh.user}@${ssh.host}</argument>
<argument>${tomcat.dir.root}/bin/shutdown.sh</argument>
</arguments>
<executable>plink</executable>
</configuration>
</execution>
<execution>
<id>10-clean-shared-jars</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<arguments>
<argument>-ssh</argument>
<argument>-4</argument>
<argument>-agent</argument>
<argument>-i</argument>
<argument>${putty.key}</argument>
<argument>${ssh.user}@${ssh.host}</argument>
<argument>rm</argument>
<argument>-Rf</argument>
<argument>${tomcat.dir.shared}/*.jar</argument>
</arguments>
<executable>plink</executable>
</configuration>
</execution>
<execution>
<id>15-upload-shared-jars</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<arguments>
<argument>-scp</argument>
<argument>-4</argument>
<argument>-agent</argument>
<argument>-i</argument>
<argument>${putty.key}</argument>
<argument>${project.build.directory}/dependency/compile/*.jar</argument>
<argument>${ssh.user}@${ssh.host}:${tomcat.lib.shared}/</argument>
</arguments>
<executable>pscp</executable>
</configuration>
</execution>
<execution>
<id>20-start-tomcat</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<arguments>
<argument>-ssh</argument>
<argument>-4</argument>
<argument>-agent</argument>
<argument>-i</argument>
<argument>"${putty.key}"</argument>
<argument>${ssh.user}@${ssh.host}</argument>
<argument>bin/startup.sh</argument>
</arguments>
<executable>plink</executable>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>


Знаю, о чем вы думаете — Kubernetes? На домашнем сервере? Кто может быть настолько сумасшедшим? Что ж, раньше я согласился бы, однако недавно кое-что изменило мое мнение.
Я начал работать в небольшом стартапе, в котором нет DevOps разработчиков со знанием Kubernetes (в дальнейшем K8s), и даже будучи старым ненавистником K8s из-за его громоздкости, был вынужден признать, что мне не хватает его программного подхода к деплойментам и доступу к подам. Также должен признать, что азарт от укрощения настолько навороченного зверя давно будоражит меня. И вообще, K8s захватывает мир — так что лишние знания не навредят.

Модуль WebFlux появился в 5й версии фреймворка Spring. Этот микрофреймворк является альтернативой Spring MVC и отражает собой реактивный подход для написания веб-сервисов. В основе WebFlux лежит библиотека Project Reactor, позволяющая легко запрограммировать неблокирующие (асинхронные) потоки (streams), работающие с вводом/выводом данных.
Следует учесть, что WebFlux для работы требуется встроенный в Spring сервер Netty. Со встроенными Tomcat и Jetty настроить реактивность сложнее и они, как минимум, должны поддерживать Servlet 3.1. Следующая диаграмма иллюстрирует особенности окружения, в котором работает WebFlux [1].

В этой статье я собираюсь показать вам, как можно выполнять маппинг полиморфных объектов JSON используя JPA и Hibernate.
Поскольку Hibernate не поддерживает JSON нативно, то для достижения этой цели я буду использовать библиотеку Hibernate Types.

Для кого эта статья? Конечно, для людей, работающих в сфере ИТ. Для разработчиков, тестировщиков, менеджеров разного уровня, аналитиков и т.д.. Уверен, что и для общего развития всем другим людям, так или иначе, причастным к ИТ было бы все же интересно это прочитать. Просто для расширения своего кругозора, для понимания того как создаются Информационные системы
Что меня сподвигло написать эту статью? Определенный опыт взаимодействия с разного уровня руководителями. Рассмотрим такую ситуацию. У нас есть вакансия, звучит она как Архитектор. И, вроде бы, понимание есть, что должен делать этот человек, но по факту оказывается, ждут “эникейщика”.
Что еще? Думаю, что надо договорится о подаче материала. Что, если это будет реальная история из моей практики, на мой взгляд, максимально демонстрирует работу Программного архитектора, а также некоторые выводы, которые можно сделать из нее. Постараюсь ответить здесь на следующие вопросы: Кто такой программный архитектор, какими навыками и знаниями должен обладать этот человек? Годиться?
И последнее, думаю надо представится. Меня зовут Владимир Воловиков. Работаю в ИТ сфере я уже почти 20-ть лет. В должности Системного архитектора и Программного архитектора, в общей сложности, более пяти лет. Имею четыре международных сертификата. Текущее место моей работы Системный архитектор, Банк ВТБ.
Для кого эта статья? Эта статья, также как и первая, рассчитана на людей, работающих в сфере ИТ. Для разработчиков, тестировщиков, менеджеров разного уровня, аналитиков и т.д. Для расширения кругозора, она также может быть полезна и всем остальным, просто, чтобы иметь представление о том, чем занимается Системный Архитектор. Пригодится материал и тем, кто планирует развитие своей профессиональной карьеры, и тем, кто выкладывает такого рода вакансию и ищет специалиста в команду.
Что еще? Думаю что надо как то договорится о подаче материала. Здесь, как и в первой статье, я рассмотрю конкретный пример из своей практики, который, как мне кажется, максимально точно иллюстрирует специфику работу данного специалиста. Как и раньше, в заключении, попробую ответить на следующие вопросы: кто такой Системный Архитектор, какими навыками должен обладать и т.д. Поехали?
И последнее, думаю, надо представится. Меня зовут Владимир Воловиков. Опыт работы в сфере разработки программного обеспечения более 20 лет. В должности Системного архитектора и Программного архитектора, в общей сложности, более пяти лет. Имею четыре международных сертификата. Текущее место моей работы Системный архитектор, Банк ВТБ.

Седьмого марта компания RedHat (вскоре — IBM) представила новый фреймворк — Quarkus. По словам разработчиков, этот фреймворк базируется на GraalVM и OpenJDK HotSpot и предназначен для Kubernetes. Стек Quarkus включает в себя: JPA/Hibernate, JAX-RS/RESTEasy, Eclipse Vert.x, Netty, Apache Camel, Kafka, Prometheus и другие.
Цель создания — сделать Java лидирующей платформой для развертывания в Kubernetes и разработки serverless приложений, предоставляя разработчикам унифицированный подход к разработке как в реактивном, так и в императивном стиле.
Если смотреть на эту классификацию фреймворков, то Quarkus где-то между "Aggregators/Code Generators" и "High-level fullstack frameworks". Это уже больше, чем агрегатор, но и до full-stack не дотягивает, т.к. заточен на разработку backend.
Quarkus – это стек Java, приспособленный для работы с OpenJDK HotSpot (или OpenJ9 на zSeries) и GraalVM, собранный из оптимизированных библиотек и стандартов Java. Он хорошо подходит для создания сильно масштабируемых приложений, при этом значительно скромнее использует ресурсы CPU и памяти, нежели другие фреймворки Java. Quarkus может работать с традиционными веб-приложениями, бессерверными приложениями и даже с функциями, предоставляемыми как услуга.
Существует много документированных случаев, в которых организации переносили свои приложения на Quarkus. В этой статье рассмотрим один из таких миграционных путей: со Spring Boot на Quarkus. Есть в этом своя магия и свое безумие. Магия – это когда миграция осуществляется как по мановению руки, и ни одной строки кода при этом менять не приходится. Безумие – в том, чтобы попытаться осознать, как все это делается.
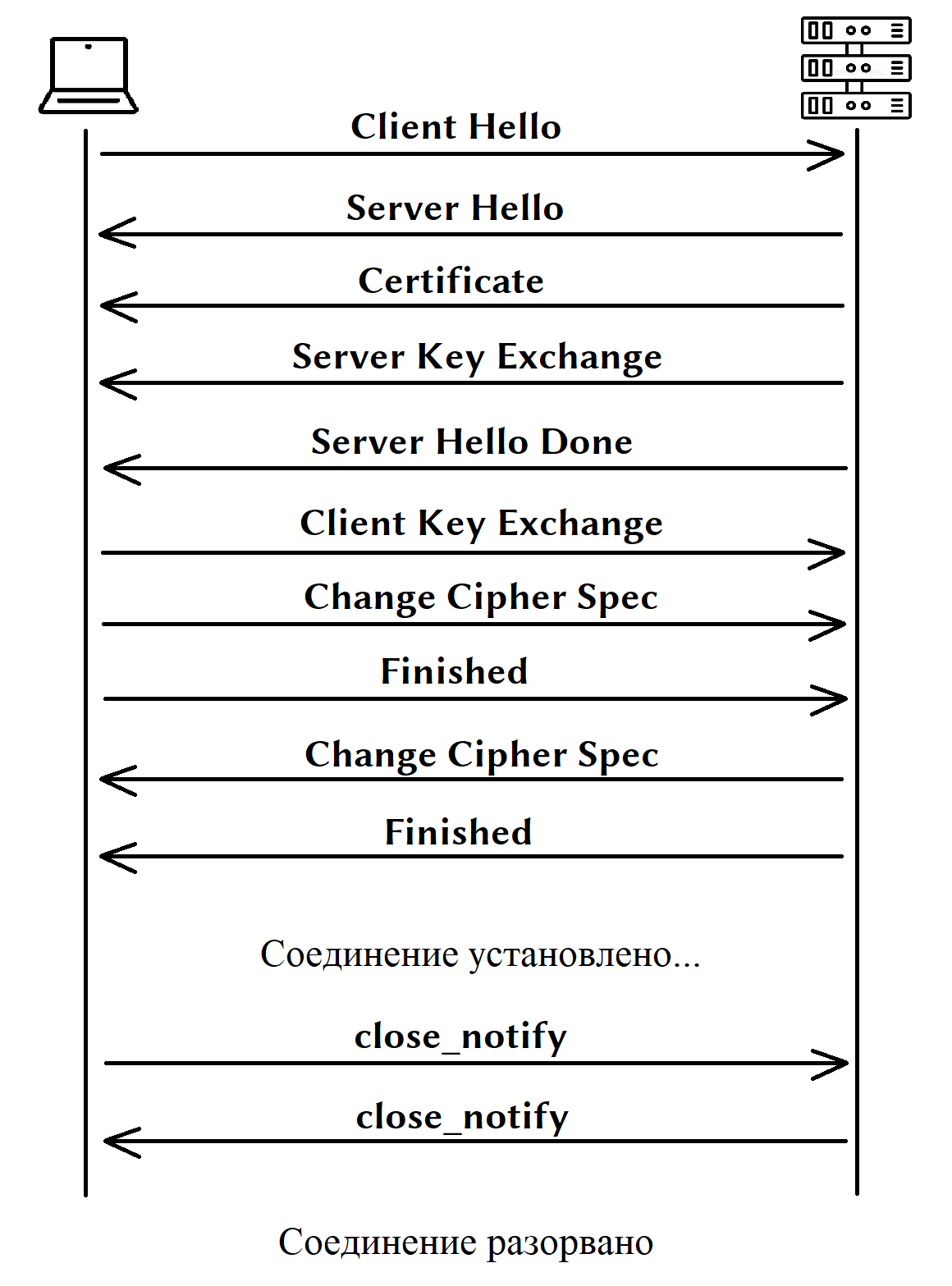
Привет, Хабр! В современном мире абсолютное большинство сайтов используют HTTPS (Google даже снижает рейтинг сайтов работающих по HTTP в поисковой выдаче), а подключение к различным системам происходит по протоколу TLS/SSL. Поэтому любой разработчик рано или поздно сталкивается с этими технологиями на практике. Данная статья призвана помочь разобраться, если вы совершенно не в курсе что это такое и как оно устроено. Мы разберем как работает соединение по протоколу TLS, как выпустить собственные сертификаты и настроем TLS в Spring Boot приложении. Поехали!