
Последнее время вышло много статей на тему тимлидства. Где-то спорили о написании кода тимлидами, где-то говорили о найме, где-то обсуждали пипл-менеджмент. Но давайте подумаем, есть ли вообще смысл становиться тимлидом.

User
Последнее время вышло много статей на тему тимлидства. Где-то спорили о написании кода тимлидами, где-то говорили о найме, где-то обсуждали пипл-менеджмент. Но давайте подумаем, есть ли вообще смысл становиться тимлидом.


Сейчас трудно себе представить «боевую» инсталляцию любой серьезной СУБД в виде единственного инстанса. Конечно, некоторые приложения требуют для своей работы использование локальных баз данных, но если мы говорим о сетевом многопользовательском режиме работы, то здесь использование только одной инсталляции это очень плохая идея.
Основной проблемой единственной инсталляции естественно является надежность. В случае падения сервера нам потребуется некоторое, возможно значительное, время на восстановление. Так восстановление террабайтной базы может занять несколько часов.
Да и исправный бэкап есть не всегда, но об этом мы уже говорили в предыдущей статье.

Или максимы Английского языка, которые бы я хотел знать 20 лет назад.
Чем отличается хороший геймер от плохого? Хороший геймер сидит и изучает игру. Он знает каждый закуток. Он может без запинки назвать все характеристики всех юнитов в Star Craft. А самый крутой игрок знает все пропускные способности желтых, красных и синих конвейеров. А плохой игрок использует чит-коды или assistant apps.
Можно сколько угодно сидеть и жаловаться о том, что правила сложны. А можно просто взять, изучить эти правила и уделать наисложнейшую игру.
Я не раз в своей жизни слышал, что Английский чрезвычайно сложен. Подобные заявления фактически являются чит-кодом. Вы просто сдаётесь и перестаёте пытаться. А зря. В английском языке есть очень много полезных и понятных вещей.
В этой статье я хочу вам показать основные моменты, которые помогли мне хорошо овладеть языком. И надеюсь, что понимание этих моментов поможет и вам.

Open-source проекты, сторонние инструменты и библиотеки - это то, за что мы действительно любим Python. В этой статье я собрал самые полезные, валидированные сообществом и проверенные временем инструменты, конфигурации которых можно встретить в популярных проектах с открытым исходным кодом.
Инструменты распределены по этапам/сферам разработки. По каждому из них я дам небольшое описание и попытаюсь рассказать о его пользе. Если утилита имеет дополнительные расширения/плагины, то я расскажу про самые полезные (на мой взгляд).

В этой статье я покажу как решить одну из проблем, возникающих при использовании распределенных очередей задач — регулирование пропускной способности очереди, или же, более простым языком, настройка ее rate limit'a. В качестве примера я возьму python и свою любимую связку Celery+RabbitMQ, хотя алгоритм, который я использую, никак не зависит от этих инструментов и может быть реализован на любом другом стэке.

Для начала пара слов о том, какую проблему я вообще пытаюсь решить. Дело в том, что 99.9% сервисов в интернете запрещают бесконтрольно закидывать их сотнями/тысячами запросов в секунду, угрожая дать в ответ какой-нибудь 403 или 500. Нет, ну правда, жалко им чтоле? Иногда таким сервисом может выступать даже своя собственная БД… Вобщем, доверять нынче нельзя никому, поэтому приходится себя как-то сдерживать.
Конечно, если вся работа ведется внутри 1го процесса, то никакой проблемы нет, но т.к мы работаем с Celery, то у нас может быть не только N процессов (далее воркеров), но и M машин, и задача все это дело синхронизировать уже не кажется столь тривиальной.


Сканер уязвимостей на Python или как написать сканер за 6 часов
Недавно мне довелось участвовать в хакатоне по информационной безопасности на научной конференции в прекрасном городе Санкт-Петербург в СПбГУТ. Одно из заданий представляло из себя написание собственного сканера уязвимостей на любом ЯП с условиями, что использование проприетарного ПО и фреймворков запрещено. Можно было пользоваться кодом и фреймворками существующих сканеров уязвимости с открытым кодом. Это задание и мое решение с моим коллегой мы и разберем в этой публикации.

В начале своего разработческого пути, меня часто посещало желание понять и принять паттерны. Но в интернете, этот материал крайне сложен для начинающих программистов. Поэтому я решил создать цикл статей, в которых разберу все GoF паттерны.
Первым разобранным шаблоном будет Снимок, замечательный паттерн, который часто не могут понять начинающие разработчики.

Недавно я сделал опрометчивый твит, в котором намекнул на то, что у меня имеется глубоко продуманное мнение по одному важному вопросу. Я написал, что пакет pytest-subtests достоин того, чтобы им пользовалось бы больше программистов. Я даже дошёл до того, что, говоря о подтестах (subtests), сказал, что они были единственным, что мне по-настоящему нравилось в unittest до появления их поддержки в pytest. И, как на грех, Брайан Оккен предложил мне поучаствовать в подкасте Test and Code, чтобы подробнее обсудить подтесты. Я могу лишь догадываться о том, что он это сделал, дабы преподнести мне урок, показать мне, что я не должен, накачавшись продуктами Splenda и травяным чаем, выдавать скороспелые мнения о тестировании кода.Но, тем не менее, когда Брайан взглянет на меня со своей хитрой улыбкой и скажет: «Итак, ты готов поговорить о подтестах?», я планировал ответить: «Да, я готов — сделал обширные заметки и набрал справочных материалов». А когда мы вместе будем стоять на сцене, получая Дневную премию «Эмми» за лучший подкаст о тестировании, я шепну ему: «Я раскрыл твою хитрость, и хотя я тебя обыграл, ты реально показал мне — что такое скромность», а по его щеке скатится одинокая слеза.
Или, что скорее всего так и есть, ему просто хотелось пригласить кого-то, с кем можно поговорить об этом конкретном аспекте Python-тестирования, а я оказался одним из тех немногих, встретившихся ему, кто высказывал по этому поводу своё мнение. В любом случае, этот пост будет играть роль моих заметок по механизму подтестов из unittest, который появился в Python 3.4. Здесь же пойдёт речь о сильных и слабых сторонах подтестов, о сценариях их использования. Этот материал можно считать дополнением к подкасту Test and Code Episode 111.

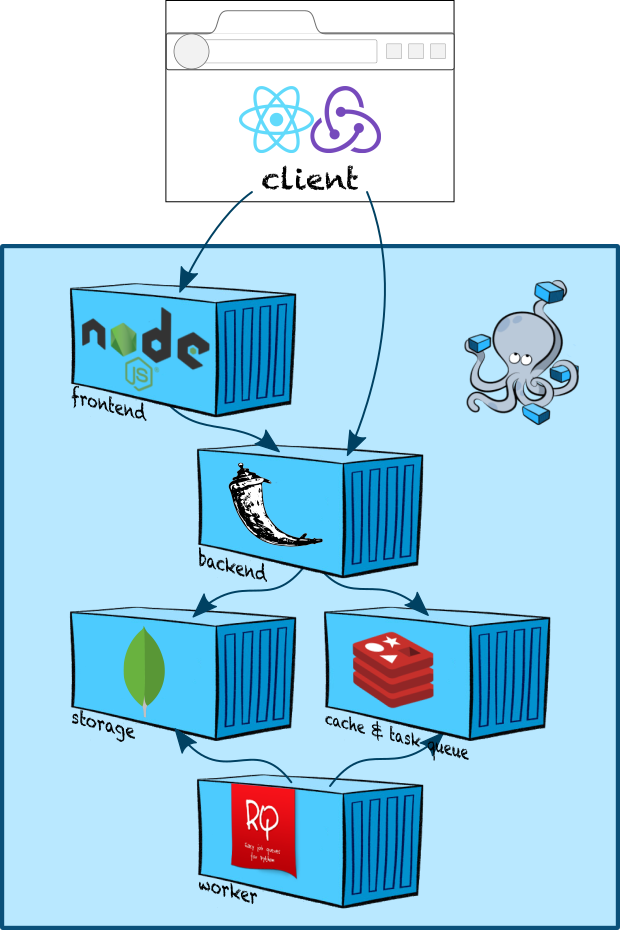
Да, действительно, в этом посте не будет гайда, как поднять Celery в Django. Это статья для тех, кто уже пощупал Celery и хочет погрузиться в детали.
Мотивацией перевести эту статью были следующие вопросы, на которые я не знал ответа: при запуске создается процесс или поток? В какую очередь попадают отложенные задачи с ETA? А какие бывают очереди (спойлер: она не одна)? А в какой момент задача удаляется из очереди? Если я создам задачу с ETA=завтра_в_12:00, она ровно в этот момент и выполнится (спойлер: нет)?
Ответы на все эти вопросы в статье, велком!

 Приветствую!
Приветствую!