Понимаем красно-черное дерево. Часть 1. Введение
Довольно долгое время я воевал с красно-черным деревом. Вся информация, которую я находил, была в духе "листья и корень дерева всегда черные, ПОТОМУ ЧТО", "топ 5 свойств красно-черного дерева" или "3 случая при балансировке и 12 случаев при удалении ноды". Такой расклад меня не устраивал.
Мне не хотелось заучивать свойства дерева, псевдокод и варианты балансировки, я хотел знать: почему. Каким образом цвета помогают при балансировке? Почему у красной ноды не может быть красного потомка? Почему глубину дерева измеряют "черной высотой"?
Ответы на эти вопросы я получил только тогда, когда мне дали ссылку на лекцию про два-три дерево, с которого мы и начнем.
Эта статья разделена на 3 логические части. Я рекомендую прочитать их в указанном порядке. Первая часть (данная) будет направлена на введение в кчд и знакомство с ним. Во второй части мы поговорим о балансировке и вставке в кчд. В третьей, завершающей, части мы разберем процесс удаления ноды. Наберитесь терпения и приятного чтения.
 Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией
Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией 




 » работает под капотом.
» работает под капотом. 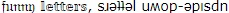 , а также отобразить «GHz» как один глиф:
, а также отобразить «GHz» как один глиф:  .
. или семиглазый монстр:
или семиглазый монстр:  . И утка:
. И утка: