
До релиза Firefox Quantum остаётся всё меньше времени. Он принесёт множество улучшений в производительности, в том числе сверхбыстрый движок CSS, который мы позаимствовали у Servo.
Но есть ещё одна большая часть технологии Servo, которая пока не вошла в состав Firefox Quantum, но скоро войдёт. Это WebRender, часть проекта Quantum Render.
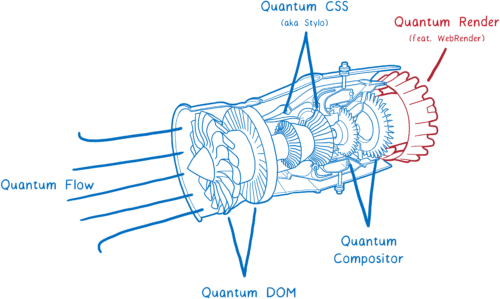
WebRender известен своей исключительной скоростью. Но главная задача — не ускорить рендеринг, а сделать его более плавным.
При разработке WebRender мы поставили задачу, чтобы все приложения работали на 60 кадрах в секунду (FPS) или лучше, независимо от размера дисплея или от размера анимации. И это сработало. Страницы, которые пыхтят на 15 FPS в Chrome или нынешнем Firefox, летают на 60 FPS при запуске WebRender.
Как WebRender делает это? Он фундаментальным образом меняет принцип работы движка рендеринга, делая его более похожим на движок 3D-игры.
Но есть ещё одна большая часть технологии Servo, которая пока не вошла в состав Firefox Quantum, но скоро войдёт. Это WebRender, часть проекта Quantum Render.

WebRender известен своей исключительной скоростью. Но главная задача — не ускорить рендеринг, а сделать его более плавным.
При разработке WebRender мы поставили задачу, чтобы все приложения работали на 60 кадрах в секунду (FPS) или лучше, независимо от размера дисплея или от размера анимации. И это сработало. Страницы, которые пыхтят на 15 FPS в Chrome или нынешнем Firefox, летают на 60 FPS при запуске WebRender.
Как WebRender делает это? Он фундаментальным образом меняет принцип работы движка рендеринга, делая его более похожим на движок 3D-игры.

 В последней своей статье про
В последней своей статье про 


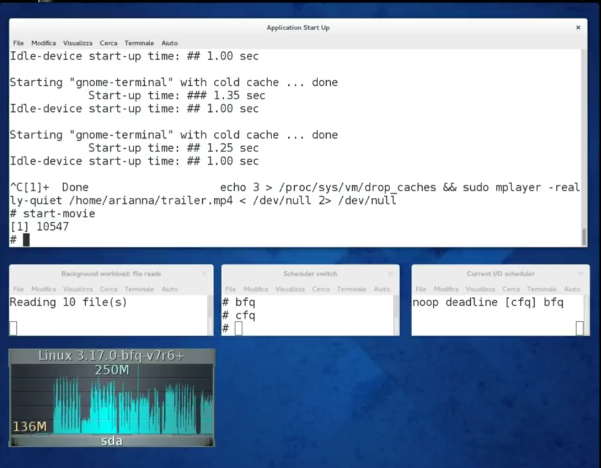
 В преддверии очередной конференции C++ Siberia, я решил выложить на всеобщее обо
В преддверии очередной конференции C++ Siberia, я решил выложить на всеобщее обо Конференции бывают разные. Некоторые собирают огромные толпы зрителей, другие могут быть интересны лишь полутора специалистам.
Конференции бывают разные. Некоторые собирают огромные толпы зрителей, другие могут быть интересны лишь полутора специалистам.

