Давно хотели что-то хакнуть? Да не было возможности? Представляю вашему вниманию крайне полный список площадок для пентеста и самостоятельного обучения.

Защита информации
Давно хотели что-то хакнуть? Да не было возможности? Представляю вашему вниманию крайне полный список площадок для пентеста и самостоятельного обучения.


Большинство разработчиков знают и любят github pages. На случай, если вы не встречались с ними — этот сервис даёт возможность создать статический сайт из вашего репозитория, который будет доступен на домене smth.github.io. Это безумно удобно для всякой временной статики, документации, небольших простых сайтов и так далее. Не приходится думать о каком-то дополнительном веб сервере.
Так же там есть возможность привязать к репозиторию свой домен — тогда всё будет совсем красиво. Даже поддержка SSL есть.
После этого небольшого введения перейдём к собственно теме статьи. Совсем недавно (9 ноября) у меня приключилась интересная история. Рекомендую не читать её залпом, а периодически останавливаться и прикидывать, что же означают все полученные на текущий момент вводные. Думаю, из этого выйдет интересная тренировка, хотя сюжет моего детектива оказался и не очень длинным и закрученным.
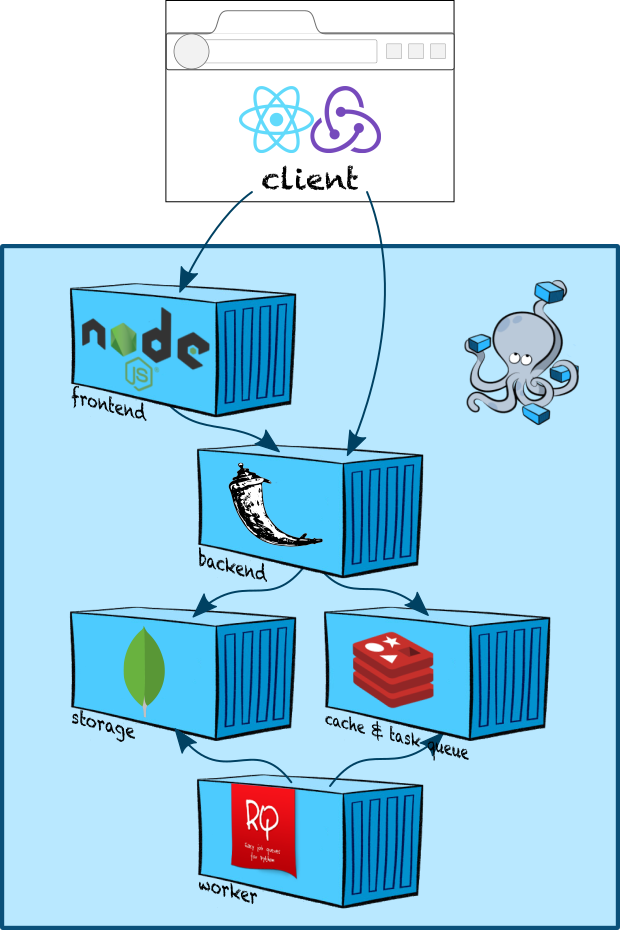
Поддержка огромной кодовой базы с одновременным обеспечением высокой производительности большого числа разработчиков — это серьезный вызов. В течение последних 5 лет в Яндексе идет разработка особой системы непрерывной интеграции. В данной статье мы расскажем про масштаб кодовой базы Яндекса, про перенос разработки в единый репозиторий с trunk-based подходом к разработке, про то, какие задачи должна решать система непрерывной интеграции для эффективной работы в таких условиях.

Много лет назад в Яндексе никаких особенных правил в разработке сервисов не было: каждый отдел мог использовать любые языки, любые технологии, любые системы деплоя. И как показала практика, такая свобода не всегда помогала двигаться вперед быстрее. В то время для решения одних и тех же задач часто существовало несколько собственных или open-source разработок. С ростом компании такая экосистема работала всё хуже. При этом мы хотели остаться одним большим Яндексом, а не разделиться на множество независимых компаний, потому что это дает массу преимуществ: много людей делают одни похожие задачи, результаты их труда можно использовать повторно. Начиная от разнообразных структур данных, типа распределённых хеш-таблиц и lock-free очередей, и заканчивая множеством разного специализированного кода, который мы написали за 20 лет.

В методологии OWASP Automated Threat Handbook представлена информация защите веб-приложений от автоматизированных угроз. Эти угрозы связаны с использованием автоматизированных средств, отказа от обслуживания, нарушения логики работы приложения, "брошенные корзины", незавершенные транзакции и т.д.


У функционального программирования много преимуществ, и его популярность постоянно растет. Но, как и у любой парадигмы программирования, у ФП есть свой жаргон. Мы решили сделать небольшой словарь для всех, кто знакомится с ФП.
В примерах используется JavaScript ES2015). (Почему JavaScript?)
Работа над материалом продолжается; присылайте свои пулл-реквесты в оригинальный репозиторий на английском языке.
В документе используются термины из спецификации Fantasy Land spec по мере необходимости.
Количество аргументов функции. От слов унарный, бинарный, тернарный (unary, binary, ternary) и так далее. Это необычное слово, потому что состоит из двух суффиксов: "-ary" и "-ity.". Сложение, к примеру, принимает два аргумента, поэтому это бинарная функция, или функция, у которой арность равна двум. Иногда используют термин "диадный" (dyadic), если предпочитают греческие корни вместо латинских. Функция, которая принимает произвольное количество аргументов называется, соответственно, вариативной (variadic). Но бинарная функция может принимать два и только два аргумента, без учета каррирования или частичного применения.

В этой заметке я хочу рассказать о том, как можно достаточно легко строить интерактивные графики в Jupyter Notebook'e с помощью библиотеки plotly. Более того, для их построения не нужно поднимать свой сервер и писать код на javascript. Еще один большой плюс предлагаемого подхода — визуализации будут работать и в NBViewer'e, т.е. можно будет легко поделиться своими результатами с коллегами. Вот, например, мой код для этой заметки.
Для примеров я взяла скаченные в апреле данные о фильмах (год выпуска, оценки на КиноПоиске и IMDb, жанры и т.д.). Я выгрузила данные по всем фильмам, у которых было хотя бы 100 оценок — всего 36417 фильмов. Про то, как скачать и распарсить данные КиноПоиска, я рассказывала в предыдущем посте.

Всем привет!
Сегодня мы поговорим про распознавание доменов, сгенерированных при помощи алгоритмов генерации доменных имен. Посмотрим на существующие методы, а также предложим свой, на основе рекуррентных нейронных сетей. Интересно? Добро пожаловать под кат.

«Всё содержится в моих чертогах разума, вы же понимаете о чём я мистер Холмс? Я обладаю знаниями, и поэтому могу щёлкать доктора Ватсона по носу хоть целый день.»