Я разрабатываю библиотеку для работы с Entity Attribute Value (репозиторий), сокращенно EAV (структура базы данных для хранения произвольных данных). В конце прошлой статьи я спросил у вас о чём мне ещё надо написать, вы попросили показать пример использования и сделать замеры быстродействия. Про замеры быстродействия статья была, эта будет о примере использования.
Назначение библиотеки
Прежде чем рассказать об использовании, надо обозначить цели этого использования. Первая цель это автоматизировать запись произвольных данных. Вторая цель - читать ранее записанные данные и делать произвольные выборки по этим данным.
Для этих двух целей применяется EAV, но он существенно замедляется при увеличении объёма данных, и главная цель библиотеки это сделать скорость работы с данными независимой от объёма данных.
Это достигается за счёт использования материализованных представлений и таблиц, и главная задача которую решает библиотека, это синхронизации данных между таблицами EAV и конкретными таблицами, выделенными под каждую категорию (Entity - сущность). Конечно сущность может быть выделена в материализованное представление, библиотека оставляет выбор за пользователем.
В статье будут приведены примеры того как задать произвольный набор атрибутов для произвольной сущности и как сделать выборку данных с произвольными условиями.
И конечно будут примеры того как для уже созданной сущности добавить новый атрибут, новую позицию и как обновить значения "позиции каталога".




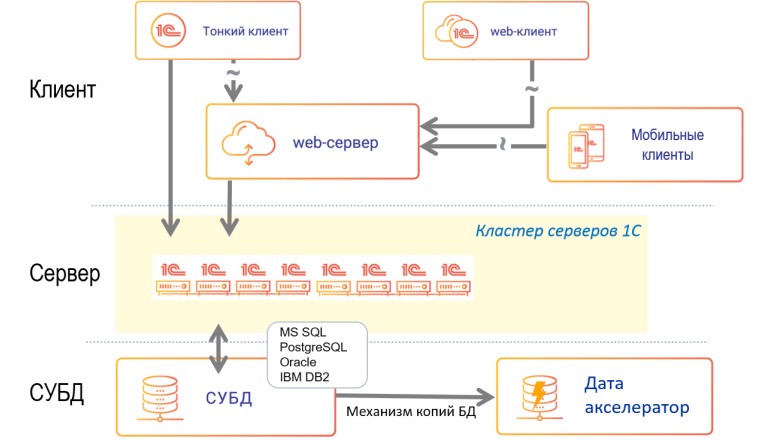

 при сортировке слиянием. Или переход от линейной сложности к логарифмической, при реализации поиска элемента в отсортированном массиве (см. бинарный поиск).
при сортировке слиянием. Или переход от линейной сложности к логарифмической, при реализации поиска элемента в отсортированном массиве (см. бинарный поиск).