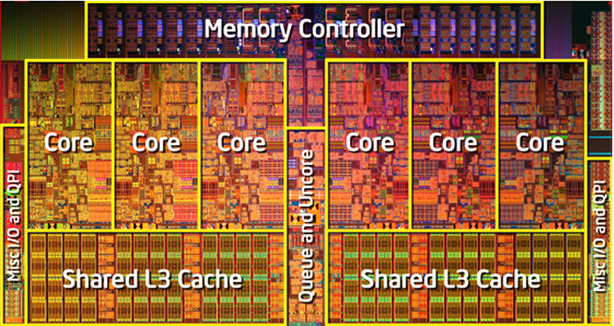
Меня зовут Вячеслав, я хронический математик и уже несколько лет не использую циклы при работе с массивами…
Ровно с тех пор, как открыл для себя векторные операции в NumPy. Я хочу познакомить вас с функциями NumPy, которые чаще всего использую для обработки массивов данных и изображений. В конце статьи я покажу, как можно использовать инструментарий NumPy, чтобы выполнить свертку изображений без итераций (= очень быстро).
Не забываем про
и поехали!
Ровно с тех пор, как открыл для себя векторные операции в NumPy. Я хочу познакомить вас с функциями NumPy, которые чаще всего использую для обработки массивов данных и изображений. В конце статьи я покажу, как можно использовать инструментарий NumPy, чтобы выполнить свертку изображений без итераций (= очень быстро).
Не забываем про
import numpy as npи поехали!
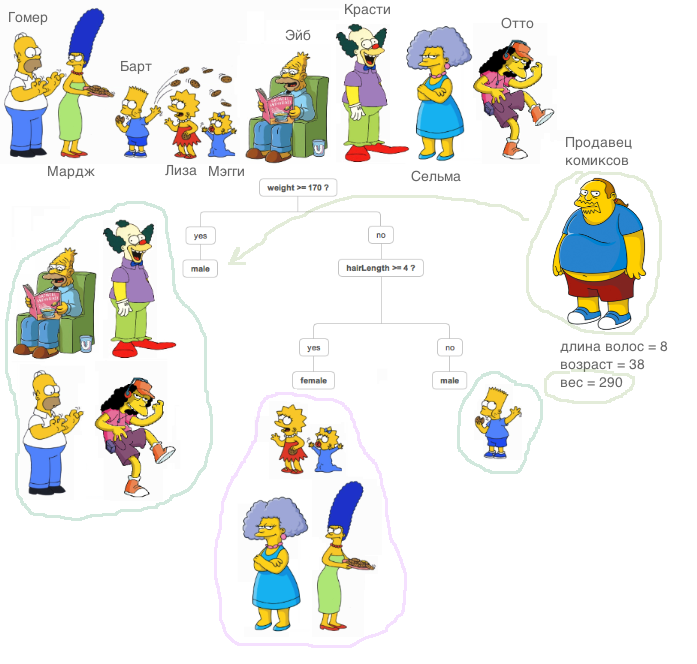
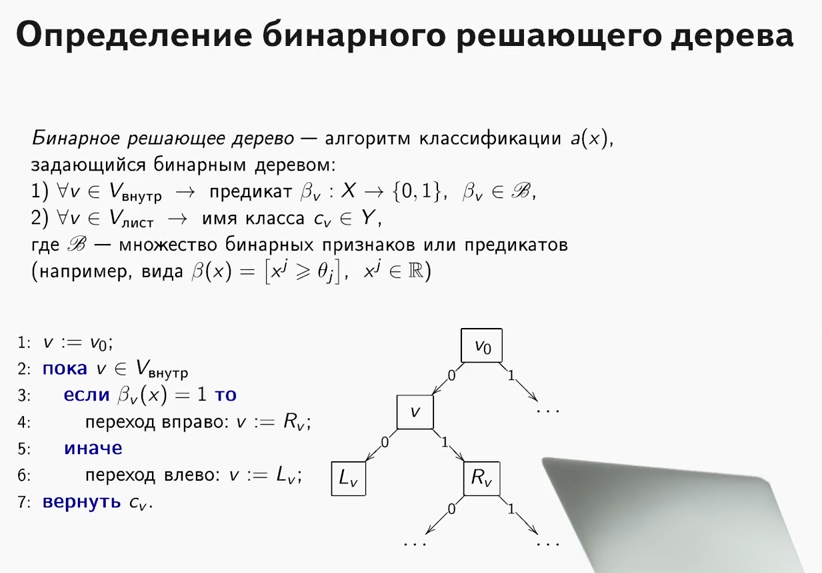




 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как  Мы продолжаем серию постов про искусственный интеллект, написанных по мотивам выступления в «Технопарке» Mail.ru Константина Анисимовича — директора департамента разработки технологий ABBYY. Вторая статья будет посвящена алгоритмам поиска.
Мы продолжаем серию постов про искусственный интеллект, написанных по мотивам выступления в «Технопарке» Mail.ru Константина Анисимовича — директора департамента разработки технологий ABBYY. Вторая статья будет посвящена алгоритмам поиска.