Abstract: Изоляция приложения на уровне сети использованием network namespaces Линукса. Организация SSH-туннелей.
Традиционно, большая часть статьи будет посвящена теории, а скучные скрипты — в конце статьи. В качестве субъекта для экспериментов будет использоваться Steam, хотя написанное применимо к любому приложению, включая веб-браузеры.
Вместо вступления. Я просто покажу эту картинку:
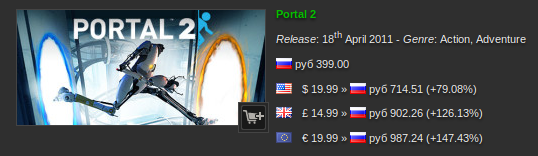
147%… Что-то мне это напоминает. Впрочем, хабр не для политики.
Цена на игры в Стиме зависит от региона. Регион — от IP'шника. Есть желание иметь цены в рублях, а не в евро.
Для этого мы используем VPN через SSH с использованием tun-устройств, плюс network namespaces для изоляции приложения от всех остальных сетевых устройств.
Network namespaces
Традиционно, приложение, запускающееся даже с правами пользователя, имеет полный доступ в сеть. Оно может использовать любой сетевой адрес, существующий в системе для отправки пакетов.
Более того, большинство десктопных приложений вообще ничего не понимает в интерфейсах, так как предполагают, что у системы есть только один сетевой интерфейс и не даёт возможности указать, каким из интерфейсов надо пользоваться. Серверное ПО обычно имеет эту опцию (какой адрес использовать в качестве адреса отправителя), но для десктопов это непозволительная роскошь.
Если у нас есть несколько интерфейсов (один из которых относится к VPN), то нет штатных методов сказать стиму, что надо использовать его, а не eth0/wlan0. Точнее, мы можем «завернуть» весь трафик в VPN, но это не всегда желательно. Как минимум — рост latency и снижение скорости (даже если VPN ведёт на супербыстрый сервер, увеличение latency, оверхед от туннеля и фиксированная ширина локального канала ставят TCP в положение, когда приходится резать скорость). Как максимум — одно дело «покупать через русский VPN», другое дело — пускать туда весь трафик. Меня совсем не прельщает использование VPN
для получения защиты роскомнадзором от оппозиции и вольнодумства.
В этих условиях возникает большое желание оставить один на один конкретное приложение и заданный сетевой интерфейс. Один. Сконфигурированный для нужд только этого приложения.
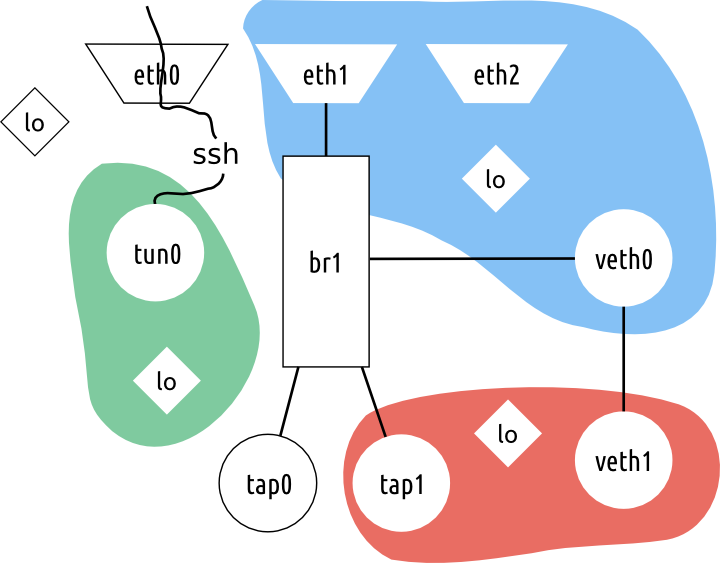
Для решения этой задачи в Linux, уже довольно давно (аж с 2007 года) существует технология, называемая network namespaces, то есть пространства имён для сетей. Суть технологии: над сетевыми интерфейсами создаётся подобие «каталогов», в каждом каталоге может быть несколько сетевых интерфейсов и приложений. Приложение, оказавшееся в заданном сетевом пространстве имён, может использовать (и видит) только те сетевые интерфейсы, которые отнесены к этому пространству.
Картинка ниже поясняет происходящее:










")