Проводится сеанс разоблачения магии (CISC, RISC, OoO, VLIW, EPIC, ...).
Без традиционной рубрики “а что, если” тоже не обошлось.
Добро пожаловать под кат, правда, лёгкого чтения ожидать не стоит.

User
Проводится сеанс разоблачения магии (CISC, RISC, OoO, VLIW, EPIC, ...).
Без традиционной рубрики “а что, если” тоже не обошлось.
Добро пожаловать под кат, правда, лёгкого чтения ожидать не стоит.


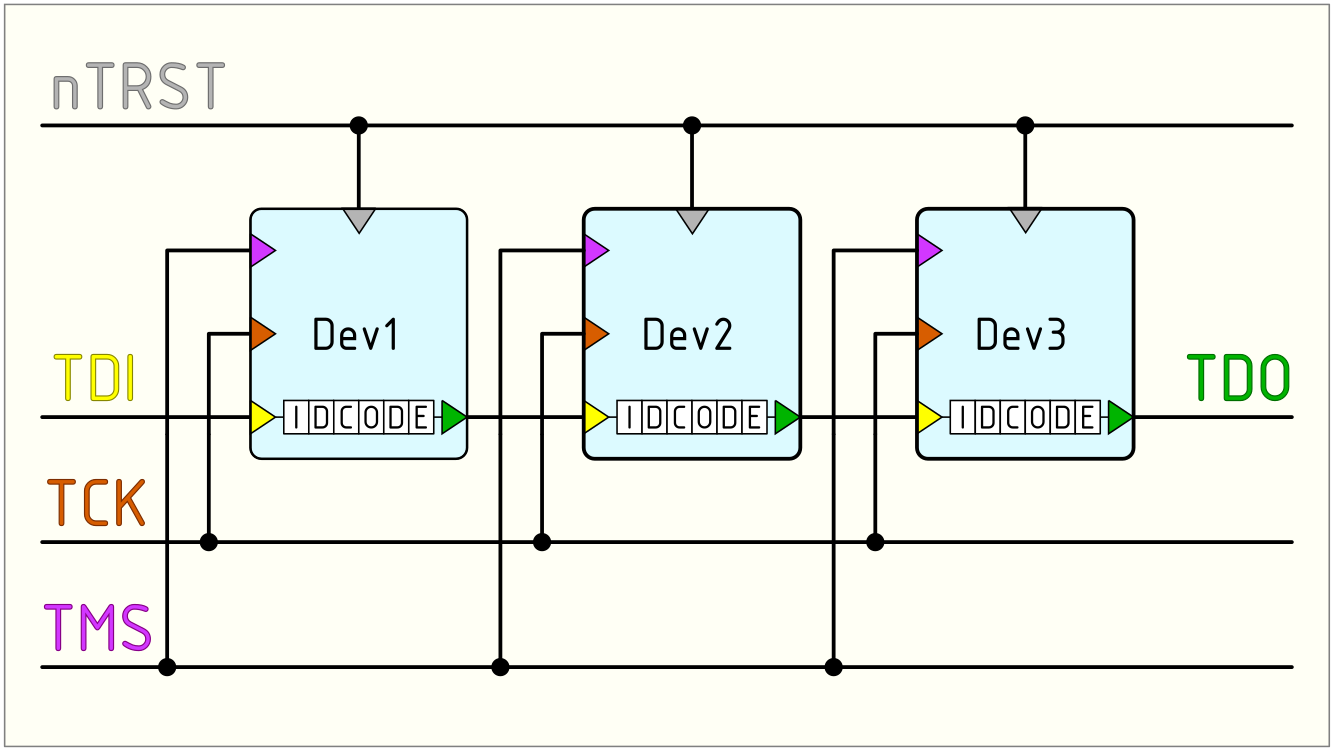
Каждый электронщик, работающий (или отдыхающий) с цифровыми микросхемами рано или поздно обязательно сталкивается с протоколом JTAG. Значительное количество материалов о данном протоколе содержит три раздела:
1) Обширный экскурс в историю и рассказ о том, как стенд с летающими щупами и рентгеновская установка легко могут быть заменены отладчиком на 2-3 порядка дешевле их.
2) Достаточно сжатое описание протокола JTAG (с картинкой его конечного автомата).
3) Рассказ о том, что фирменный отладчик, а также программное обеспечение компании <COMPANY NAME> позволят почти без усилий протестировать почти любое устройство почти любой сложности и конфигурации.
Проблема второго раздела подобных материалов в том, что в протоколе JTAG можно выделить более одного уровня абстракции. И за один раз, причём без практических примеров, осознать JTAG целиком может быть весьма непросто. В отсутствие же целостного понимания, для инженера, использующего JTAG, данный протокол будет представлять чёрный ящик, который либо работает (и всё хорошо), либо не работает (и непонятно, что делать). Представляется, что, исключив из рассмотрения историю JTAG и рекламу бренда, а также разделив задачу на отдельные составляющие, возможно осознать JTAG полностью, обретя способность устранять проблемы в работе данного протокола на любом уровне. И первым шагом к такому пониманию будет чтение идентификационного номера микросхемы.

В этой статье я решил сделать небольшое отступление от общей линии повествования и зарулю на дорогу Linux. За то непродолжительное время, что я работаю с Zynq 7000, в тематических чатах я видел много вопросов насчет того, как запустить Linux на отладке. Я в общем-то, недолго думая, сел проштудировал документацию, примеры и завёл его своими руками под ту плату, что у меня есть в распоряжении. После этого я решил обобщить свои знания по этому вопросу и описать процедуру сборки, подготовки загрузочного образа Linux, который включает в себя U-boot, Device Tree Source, RootFS, и само ядро Linux. В дополнение к этому, я решил немного усложнить задачу и выяснил, как можно поморгать светодиодом подключенным к PL-части устройства из пространства пользователя Linux.
Обо всём этом я написал в этой статье. Всем интересующимся - добро пожаловать под кат.

Все делают это. Ну ладно, не все, но большинство. Пишут скрипты, чтобы симулировать свои проекты на Verilog, SystemVerilog и VHDL. Однако, написание и поддержка таких скриптов часто бывает довольно непроста для типично используемых Bash/Makefile/Tcl. Особенно, если необходимо не только открывать GUI для одного тестбенча и смотреть в диаграммы, но и запускать пачки параметризированных тестов для различных блоков, контролировать результат, параллелизировать их выполнение и т.д. Оказалось, что всё это можно закрыть довольно прозрачным и легко поддерживаемым кодом на Python, что мне даже обидно становится от того, как я страдал ранее и сколько странного bash-кода родил.

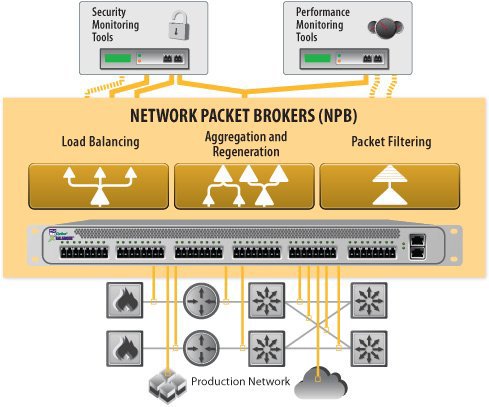 Недавно, в ходе работы над 100GE анализатором трафика передо мной была поставлена задача по изучению такого типа приборов, как Network Packet Broker (также встречается название Network Monitoring Switch), или, если просто и по-русски, «балансировщик».
Недавно, в ходе работы над 100GE анализатором трафика передо мной была поставлена задача по изучению такого типа приборов, как Network Packet Broker (также встречается название Network Monitoring Switch), или, если просто и по-русски, «балансировщик». 
printk, собрать логи, обработать их 


Поговорим о том, как при наличии небольшого количества времени и навыков построить мультимедийный комбайн с дополнительными возможностями домашнего сервера на базе Kubuntu 20.04 и KODI, способного работать 24/7/365.


int TYPE[2];int TYPE, int *TYPE и т. д., для которых операции =, &, * и другие не переопределены и обозначают обычные вещи;int x;
int *y = &x; // От любой переменной можно взять адрес при помощи операции взятия адреса "&". Эта операция возвращает указатель
int z = *y; // Указатель можно разыменовать при помощи операции разыменовывания "*". Это операция возвращает тот объект, на который указывает указатель