Хабр, привет! 8-13 сентября команда New Professions Lab провела в Москве второй форум Data Science Week. Как и обещали, публикуем презентации наших спикеров:


Пользователь
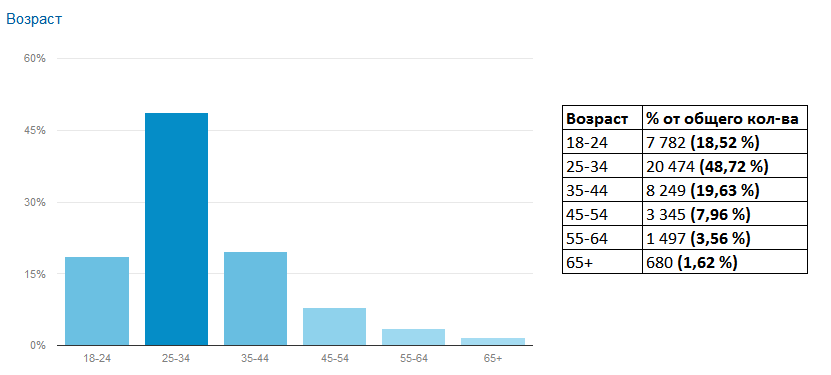
В очередной статье нашего цикла публикаций, посвященного интернет-разведке, рассмотрим, как операторы продвинутого поиска Google (advanced search operators) позволяют быстро находить необходимую информацию о конкретном человеке.
В комментариях к первой нашей статье, читатели просили побольше практических примеров и скриншотов, поэтому в этой статье практики и графики будем много. Для демонстрации возможностей «продвинутого» поиска Google в качестве целей были выбраны личные аккаунты автора. Сделано это, чтобы никого не обидеть излишним интересом к его частной жизни. Хочу сразу предупредить, что никогда не задавался целью скрыть свое присутствие в интернете, поэтому описанные методы подойдут для сбора данных об обычных людях, и могут быть не очень эффективны для деанонимизации фэйковых аккаунтов, созданных для разовых акций. Интересующимся читателям предлагаю повторить приведенные примеры запросов в отношении своих аккаунтов и оценить насколько легко собирать информацию по ним.

Какое-то время назад мы подключили модуль машинного обучения к системе, которая защищает платежи и переводы в Яндекс.Деньгах от мошенничества. Теперь она понимает, когда происходит нечто подозрительное, даже без явных инструкций в настройках.
В статье я расскажу о методиках и сложностях поиска аномалий в поведении покупателей и магазинов, а также о том, как использовать модели машинного обучения, чтобы все это взлетело.


 Эта история началась с того что я застрял в пробке на хайвее, не особенно большой, но полчаса простоял практически на месте. И, как это часто бывает, пробка рассосалась сама по себе — не было впереди ни аварии, ни ремонта, просто машины в какой-то момент начали двигаться быстрее, еще быстрее, и все — свободная дорога впереди.
Эта история началась с того что я застрял в пробке на хайвее, не особенно большой, но полчаса простоял практически на месте. И, как это часто бывает, пробка рассосалась сама по себе — не было впереди ни аварии, ни ремонта, просто машины в какой-то момент начали двигаться быстрее, еще быстрее, и все — свободная дорога впереди.
Чем обычно занимаются в пробках? Ну кто-чем и когда-как, а я в тот день был в мирном философском настроении — просто сидел и размышлял. Вспомнил в частности пост на Гиктаймс о робомобилях где в комментариях бурно сравнивали манеру вождения людей и роботов и в конце кажется пришли к выводу что будущее на дорогах за AI, при нем и движение станет безопаснее и средняя скорость возрастет. Интересно, а пробки тогда будут? Другими словами, насколько пробки обусловлены внешними (обьективными) обстоятельствами, и насколько эффектом толпы, агрессивной или наоборот тормозной манерой вождения? Заодно вспомнилась прочитанная когда-то книга где утверждалось что моделирование дорожного трафика — одна из самых сложных математических задач, которая до сих пор не решена. Ну это наверное давно уже неправда, читал я это давно и книга уже тогда была не новой, сейчас уже наверняка и теории правильные написали, и на компьютерах своих все посчитали. Хотя… пробки же остались? В общем, полет фантазии было уже не остановить.
Итак, под катом мы попытаемся построить более-менее осмысленную модель движения транспорта на дороге и, если повезет, постараемся смоделировать разницу в вождении водителя-человека и AI. Я разумеется отдаю себе отчет что этой проблемой профессионально занимаются целые организации и вообще очень умные люди, но тем интереснее. И вообще, ставьте себе нереальные цели.
И еще одно — я убежденный сторонник думанья головой, поэтому в этом посте компьютерного моделирования не будет, вообще совсем не будет, только хардкорный карандаш и бумага.


Сегодня, спустя 7 месяцев с момента предыдущего значительного выпуска, вышла версия 5.8 кроссплатформенного фреймворка Qt.
Qt позволяет разрабатывать приложения при помощи C++ и декларативного языка программирования QML, поддерживает все основные десктопные и мобильные платформы, а также некоторые встраиваемые и имеет открытый исходный код. Существует коммерческая версия Qt, содержащая дополнительные проприетарные модули.
В этом выпуске появилась новая система конфигурации, позволяющая включить в сборку только необходимый функционал (Qt Lite), стабилизация некоторых экспериментальных модулей, а также новые экспериментальные модули и удаление устаревших.



Об успехах Google Deepmind сейчас знают и говорят. Алгоритмы DQN (Deep Q-Network) побеждают Человека с неплохим отрывом всё в большее количество игр. Достижения последних лет впечатляют: буквально за десятки минут обучения алгоритмы учатся и выигрывать человека в понг и другие игры Atari. Недавно вышли в третье измерение — побеждают человека в DOOM в реальном времени, а также учатся управлять машинами и вертолетами.
DQN использовался для обучения AlphaGo проигрыванием тысяч партий в одиночку. Когда это ещё не было модным, в 2015 году, предчувствуя развитие данного тренда, руководство Phobos в лице Алексея Спасского, заказало отделу Research & Development провести исследование. Необходимо было рассмотреть существующие технологий машинного обучения на предмет возможности использования их для автоматизации победы в играх управленческих. Таким образом, в данной статье пойдёт речь о проектирование самообучающегося алгоритма в игре виртуального управленца против живого коллектива за повышение производительности.

