Оглавление: Уроки компьютерного зрения. Оглавление / Хабр (habr.com)
Начиная с этого урока, я буду рассказывать о компьютерном зрении на примере моего пэт-проекта. Для начала, что это будет за проект. На первом уроке я рассказал о стадиях обработки изображения в компьютерном зрении. В своем пэт-проекте я создам специальный конвейер, где эти стадии будут реализованы. Напомню кратко об этих стадиях:
• Предобработка изображения.
• Промежуточная фильтрация.
• Выявления специальных признаков (фич).
• Высокоуровневый анализ.
Разумеется, это не окончательный список стадий обработки. В будущем сюда может что-то добавиться, а так же некоторые стадии могут иметь подстадии.
Естественно, делать конвейер ради самого конвейера как-то бессмысленно. Надо, чтобы моя программа делала хоть что-то условно полезное. Сначала я хотел написать пэт-проект, который бы анализировал фотографии со спутников и БЛА и превращал их в граф (это перекликается с темой моей магистерской диссертации). Правда, это слишком уж амбициозная задумка для пэт-проекта. Надо что-то по- проще. В комментариях к одному из уроков мне посоветовали добавить в финале пару глав про выделение отдельных символов и распознавание их при помощи общедоступных нейронок. И вот я и подумал, может, начать пэт-проект именно с этой задачи? Распознавание текстов? Это гораздо проще.
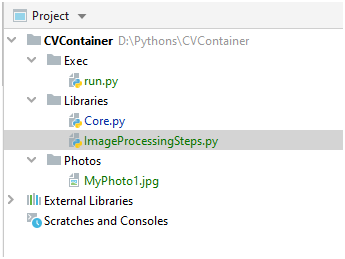
Итак, для начала я создал пустой проект и добавил туда две папки: Exec и Libraries. В первой у меня будет запускаемый файл/файлы, во втором всякие библиотечные файлы. В качестве первого библиотечного файла создал Core.py: