Всем привет!
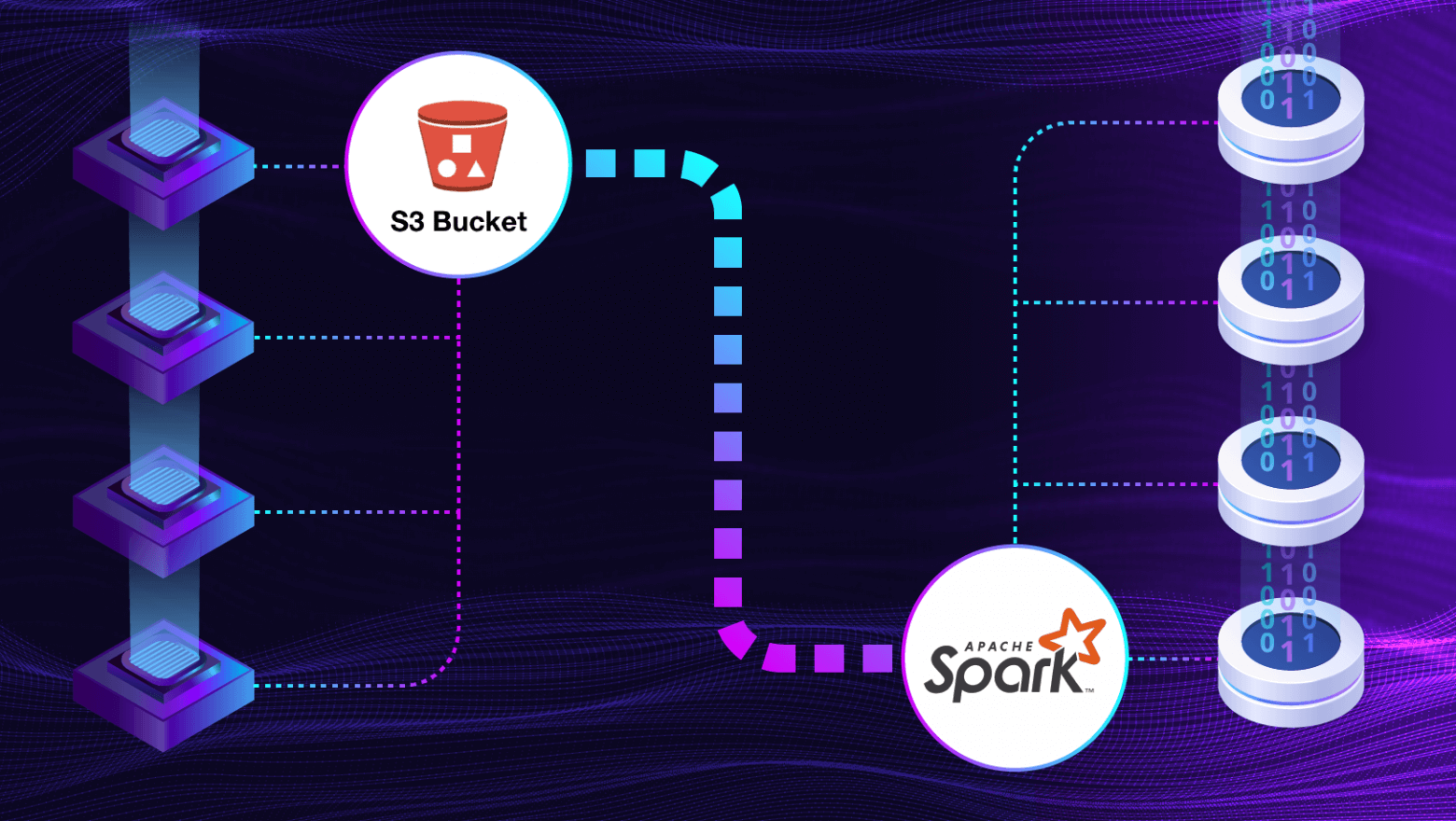
В этой статье мы расскажем, как нам удалось настроить взаимодействие Apache Spark и S3 для обработки больших файлов: с какими проблемами пришлось столкнуться и как нам удалось их решить.

Архитектор домена BI
Всем привет!
В этой статье мы расскажем, как нам удалось настроить взаимодействие Apache Spark и S3 для обработки больших файлов: с какими проблемами пришлось столкнуться и как нам удалось их решить.

Привет. Меня зовут Евгений Вилков. Я занимаюсь системами управления и интеграции данных с 2002 г., а конкретно системами анализа и обработки данных — с 2007 г. Технологии, с которыми я имел дело на протяжении моего профессионального пути, стремительно развивались. Начиная с решений, основанных на стеке традиционных СУБД, таких как Oracle, MS SQL Server, Postgres, постепенно эволюционируя в ставшие уже классическими (а некоторые даже и закрытыми) MPP-системы, такие как Teradata, GreenPlum, Netezza, Vertica, IQ, HANA, Exadata, ClickHouse, в различные решения на базе экосистемы Hadoop, облачные сервисы и платформы. Меняется мир, меняются технологии, меняются подходы к проектированию, меняются и требования к задачам аналитического ландшафта данных.
Уверен, что многие, кто уже знаком с терминами Data Mesh и Data Lakehouse, задаются вопросом: что может предложить рынок аналитических систем в этих методологиях проектирования и архитектурных подходах. Я хочу рассказать об аналитической платформе данных Data Ocean Nova, владельцем и технологическим идеологом которой я являюсь.

Здравствуйте, меня зовут Сергей Шаблыкин. Я работаю архитектором домена BI в компании «Лента». Сегодня поделюсь описанием архитектуры рассылки отчетов SAP BW, которая помогает отказаться от тяжеловесного стандартного SAP-решения и получить много дополнительных преимуществ в части экономия времени сотрудников и ресурсов Компании.
Предыстория
Мы используем SAP BW на SAP HANA уже более 10 лет. Когда-нибудь мы напишем статью об успешном импортозамещении SAP BW, но пока это время еще не пришло. За все годы у нас сложился успешный сценарий получения пользователями отчетов через рассылки: сотни пользователей получают их в определенном формате и с требуемыми фильтрами. Есть выгоды и для ИТ в целом: мы получаем меньше жалоб на производительность SAP BW, ведь без рассылки все эти сотни людей заходили бы в систему, причем примерно в одно и то же время.
С выходом SAP BW/4 вендор поменял реализацию сценария и теперь для него требуется SAP Business Objects BI Platform – мощное, но тяжеловесное решение. Так сложилось, что от этой платформы нам нужна только рассылка. Другие компоненты платформы проиграли в свое время конкурентную борьбу. Но из-за рассылок приходится ее «терпеть», в том числе все нынешние сложности с ее обновлением, поддержкой и рядом функциональных недостатков. И это становится проблемой, которая не только усложняет эксплуатацию того, что есть, но и не позволяет расширяться.
Так и родилась идея сделать новое решение по рассылке, которое будет лучше и дешевле в эксплуатации. И, что не менее важно, оно будет реализовано на нашей стороне с расширенными возможностями по техподдержке и возможностью его дальнейшей доработки.

Привет! Меня зовут Адель Давлетшин, я занимаюсь роботизацией процессов в компании «Лента». Сегодня я хочу поделиться историей о том, как наше чрезмерное увлечение RPA привело к остановкам и сбоям в критическом процессе, и как этот случай побудил нас перейти от вопроса «Можно ли это сделать с помощью RPA?» к более важному вопросу: «А почему это стоит делать именно с помощью RPA?».
Привет, я Дмитрий Логвиненко — Data Engineer отдела аналитики группы компаний «Везёт».
Я расскажу вам о замечательном инструменте для разработки ETL-процессов — Apache Airflow. Но Airflow настолько универсален и многогранен, что вам стоит присмотреться к нему даже если вы не занимаетесь потоками данных, а имеете потребность периодически запускать какие-либо процессы и следить за их выполнением.
И да, я буду не только рассказывать, но и показывать: в программе много кода, скриншотов и рекомендаций.
Что обычно видишь, когда гуглишь слово Airflow / Wikimedia Commons
Статья предназначена в первую очередь для консультантов и архитекторов, работающих с продуктами SAP, перед которыми стоит задача проектирования и реализации решения по подготовке отчетности в формате XLSX.
В настоящее время все большую популярность набирают облачные решения для визуализации данных, демонстрируя двузначный рост год-к-году по большинству показателей. Однако не все компании - клиенты поставщиков облачных решений могут позволить себе использовать “облака” по самым разным причинам: от требований безопасности данных до недостаточной функциональности или даже более высокой стоимости владения по сравнению с on-premise.
Поэтому время от времени возникают задачи подготовки отчетности для визуализации в on-premise-инструментах. Автор долгое время работал и продолжает работать с решениями SAP, поэтому именно решения SAP (SAP BW/4, SAP S/4), как поставщики данных для отчетности, наиболее близки. Однако предлагаемый подход может быть скопирован и на другие системы-источники. Никаких препятствий к этому нет.
Задача формулируется так: реализовать on-premise решение по автоматической и регулярной подготовке отчетов по бизнес-данным SAP-систем (BW/4 или S/4) в формате XLSX.


Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.