

У нас было 17 романов Стивена Кинга, много свободного времени, навыки анализа данных Python и безудержная любовь к поиску пасхалок. Вот, что из этого вышло.
У нас было 17 романов Стивена Кинга, много свободного времени, навыки анализа данных Python и безудержная любовь к поиску пасхалок. Вот, что из этого вышло.


Мы нашли все самые крутые логические задачи!
15 лет назад мы решили создать сайт для любителей каверзных задач и головоломок. Не просто сборник с ответами под катом, а интерактивный ресурс, дающий возможность насладиться самостоятельным поиском решения, почувствовать озарение, научиться смотреть на вещи под другим углом и поверить в свои силы.
Так появилось сообщество решателей задач BrainGames.ru. Наш сайт развивался и менялся, сменялись решающие, сменялись проверяющие, но вот уже много лет мы не изменяем трем основным принципам:
Мы не даем ответов. Ответ узнать можно, но только найдя его самостоятельно и услышав “верно” от модератора (так мы называем проверяющих задачи).
Задачи проходят жесткий отбор и переработку.
Присоединиться к сообществу и проверить ответ смогут только те, кто решит несколько “регистрационных” задач - простых, но нестандартных.


Bremsstrahlung ("тормозное излучение") — ударная волна света, которая генерируется, когда заряженные частицы "застревают" в твердом теле (классический процесс генерации излучения в рентгеновских вакуумных трубках).
Для многих вполне естественно ассоциировать электрическое и магнитное поля с векторами и силовыми линиями. Но как этими математическими объектами описать волны? Когда они возникают? Ответы на эти вопросы можно получить с помощью школьных формул с щепоткой специальной теории относительности.


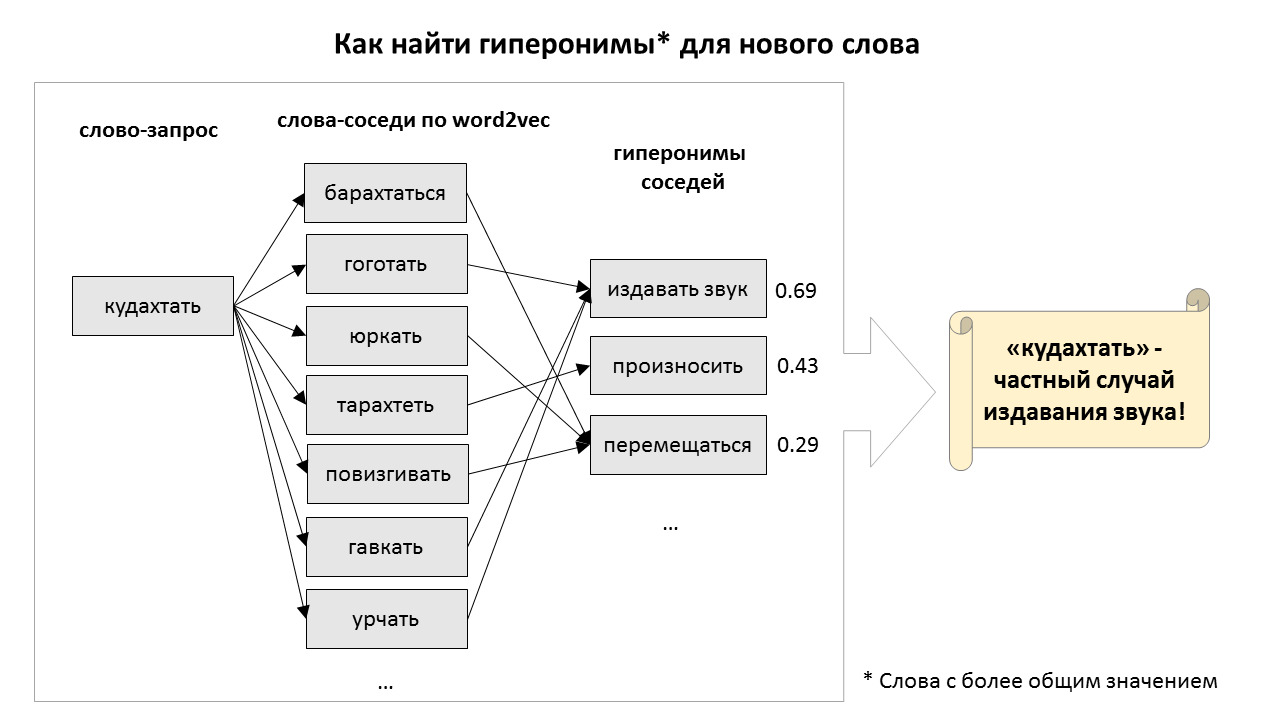
Как может машина понимать смысл слов и понятий, и вообще, что значит — понимать? Понимаете ли вы, например, что такое спаржа? Если вы скажете мне, что спаржа — это (1) травянистое растение, (2) съедобный овощ, и (3) сельскохозяйственная культура, то, наверное, я останусь убеждён, что вы действительно знакомы со спаржей. Лингвисты называют такие более общие понятия гиперонимами, и они довольно полезны для ИИ. Например, зная, что я не люблю овощи, робот-официант не стал бы предлагать мне блюда из спаржи. Но чтобы использовать подобные знания, надо сначала откуда-то их добыть.
В этом году компьютерные лингвисты организовали соревнование по поиску гиперонимов для новых слов. Я тоже попробовал в нём поучаствовать. Нормально получилось собрать только довольно примитивный алгоритм, основанный на поиске ближайших соседей по эмбеддингам из word2vec. Однако этот простой алгоритм каким-то образом оказался наилучшим решением для поиска гиперонимов для глаголов. Послушать про него можно в записи моего выступления, а если вы предпочитаете читать, то добро пожаловать под кат.

Если вы не проспали последние пару-тройку лет, то вы, конечно, слышали от трансформерах — архитектуре из каноничной Attention is all you need. Почему трансформеры так хороши? Например, они избегают рекуррентности, что дает им возможность эффективно создавать такое представление данных, в которое можно запихнуть очень много контекстной информации, что положительно сказывается на возможности генерации текстов и непревзойденной способности к transfer learning.
Трансформеры запустили лавину работ по language modelling — задаче, в которой модель подбирает следующее слово, учитывая вероятности предыдущих слов, то есть выучивая p(x), где x — текущий токен. Как можно догадаться, это задача совсем не требует разметки и потому в ней можно использовать огромные неаннотированные массивы текста. Уже обученная языковая модель может генерировать текст, да так хорошо, что авторы подчас отказываются выкладывать обученные модели.
Но что если мы хотим добавить немного “ручек” к генерации текста? Например, делать условную генерацию, задавая тему или контролируя другие атрибуты. Такая форма уже требует условной вероятности p(x|a), где a — это желаемый атрибут. Интересно? Поехали под кат!



Сегодня Lifext расскажет:
