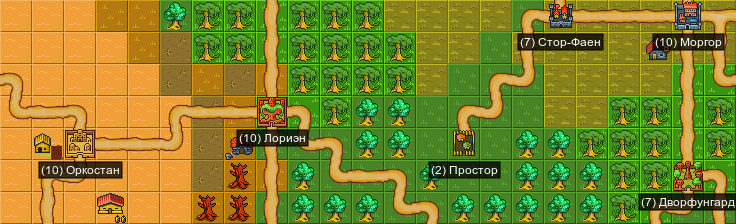
В своей работе вы используете MySQL, Postgres или Mongo, а может даже Apache Spark? Хотите знать с чего начинались эти проекты и куда они движутся сейчас? В этой статье я представлю соответствующую визуализацию


User
"The joy of coding Python should be in seeing short, concise, readable classes that express a lot of action in a small amount of clear code — not in reams of trivial code that bores the reader to death."
Guido van Rossum
 Python — язык программирования, на котором приятно писать и который приятно читать. Мы предлагаем тринадцать лекций осеннего курса CS центра, чтобы посмотреть вглубь языка и попробовать понять, как пользоваться всеми его возможностями. Лекции читает Сергей Лебедев, разработчик в компании JetBrains и преподаватель в Computer Science Center.
Python — язык программирования, на котором приятно писать и который приятно читать. Мы предлагаем тринадцать лекций осеннего курса CS центра, чтобы посмотреть вглубь языка и попробовать понять, как пользоваться всеми его возможностями. Лекции читает Сергей Лебедев, разработчик в компании JetBrains и преподаватель в Computer Science Center. 


 1 июля 2014 года произошло одно из самых значимых событий в истории государства Российского: с этого момента у нас в стране наконец появилась эталонная база адресов по всем, даже самым малым населённым пунктам! Имя этой базе — ФИАС. Собственно, сам по себе справочник ФИАС появился гораздо раньше, но именно 1 июля вступил в силу ФЗ 443, согласно которому все государственные и муниципальные структуры теперь должны опираться на него как на единственно верную базу адресов. Мы решили исследовать, стоит ли переходить на ФИАС, и с какими подводными камнями столкнутся те, кто решит это делать.
1 июля 2014 года произошло одно из самых значимых событий в истории государства Российского: с этого момента у нас в стране наконец появилась эталонная база адресов по всем, даже самым малым населённым пунктам! Имя этой базе — ФИАС. Собственно, сам по себе справочник ФИАС появился гораздо раньше, но именно 1 июля вступил в силу ФЗ 443, согласно которому все государственные и муниципальные структуры теперь должны опираться на него как на единственно верную базу адресов. Мы решили исследовать, стоит ли переходить на ФИАС, и с какими подводными камнями столкнутся те, кто решит это делать.
<canvas> очень часто. Я сделал несколько достаточно сложных веб-приложений, в которых canvas — это основной элемент представления данных. Использовать canvas без всяких фреймворков и библиотек может быть действительно сложно в крупных приложениях. Поэтому я начал часто использовать фреймворки. Сейчас я поддерживаю фреймворк Konva (есть обзорная статья https://habrahabr.ru/post/250897/).