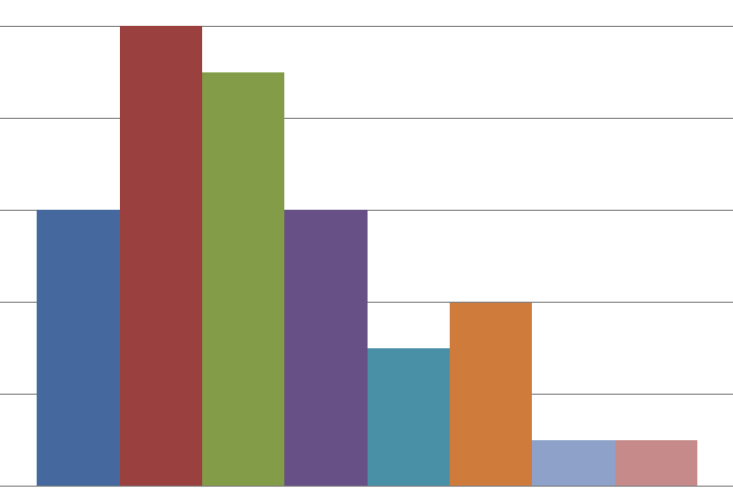
Хабр, привет. Представляю вам главную help-ссылку для работы с данными. Материал в Гугл-доке подойдет как профессионалам, так и тем, кто только учится работать с данными. Пользуйтесь и прокачивайте скиллы сами + делитесь с коллегами.
Дальнейшее описание поста — это содержание help-ссылки. Поэтому, можете сразу ознакомиться с документом. Либо начать с её содержания, которую прикрепляю ниже.
Конечно, весь список книг/сервисов/видео и лекций в файле неполный. Поэтому предлагаю сделать этот пост ценнейшим — добавляйте в комментарии свои полезные ссылки, самые крутые из них я добавлю к себе в файл.

Дальнейшее описание поста — это содержание help-ссылки. Поэтому, можете сразу ознакомиться с документом. Либо начать с её содержания, которую прикрепляю ниже.
Конечно, весь список книг/сервисов/видео и лекций в файле неполный. Поэтому предлагаю сделать этот пост ценнейшим — добавляйте в комментарии свои полезные ссылки, самые крутые из них я добавлю к себе в файл.





 Среди дата сайнтистов ведется немало холиваров, и один из них касается соревновательного машинного обучения. Действительно ли успехи на Kaggle показывают способности специалиста решать типичные рабочие задачи? Арсений
Среди дата сайнтистов ведется немало холиваров, и один из них касается соревновательного машинного обучения. Действительно ли успехи на Kaggle показывают способности специалиста решать типичные рабочие задачи? Арсений