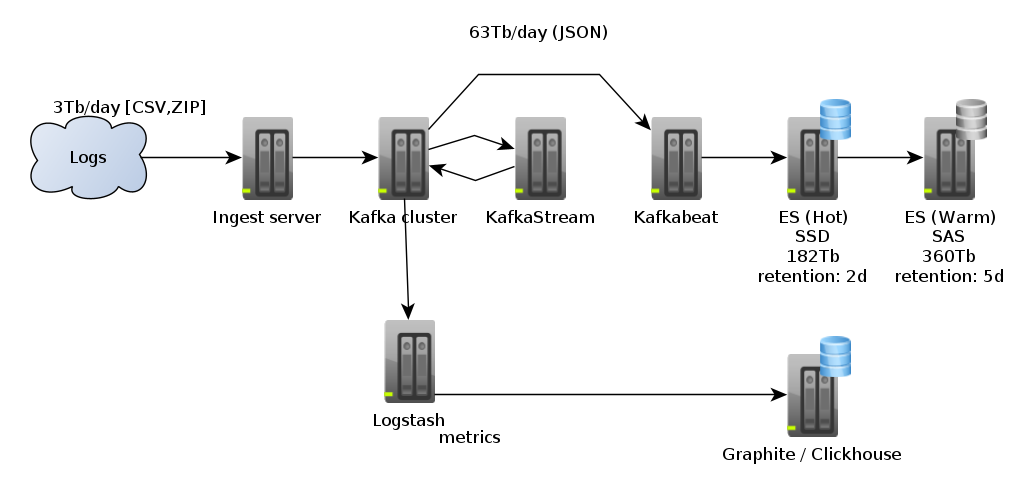
Kubernetes состоит из нескольких компонентов, где значительная часть взаимодействий итогового пользователя с системой осуществляется при помощи API-сервера. Он представляет собой отправную точку для многих функций, которые проект создал за время своего существования, и может быть расширен для поддержания дополнительной произвольной функциональности. Поэтому API-сервер иногда оказывается ограниченным местом, которое изначально не было задумано для размещения, или, по крайней мере, хорошего размещения.
В новой серии статей «Мир приключений по API-серверу Kubernetes» («k8s ASA») мы погрузимся во все детали работы API-сервера, получим представление о том, как они работают, а также с какими компонентами взаимодействуют. Параллельно поэкспериментируем с заменой пользовательских компонентов, создадим инструментарий и рассмотрим, как другие пользователи модифицировали его в соответствии с пользовательскими кейсами. Кто знает, возможно, даже построим наш собственный. ?