Сегодня я подробно разберу настройку аутентификации в Kubernetes с помощью Dex в связке с LDAP, а также покажу, как можно добавлять статических пользователей в Dex.
В статье не буду останавливаться на основных принципах работы Dex, а сразу перейду к установке и настройке LDAP. Познакомиться с принципами работы Dex можно в этой статье.
Руководитель отдела эксплуатации залез в люк подземного топливохранилища, чтобы показать маркировку на электромагнитном клапане.
В начале февраля наш самый большой дата-центр Tier III NORD-4 прошел повторную сертификацию Uptime institute (UI) по стандарту Operational Sustainability. Сегодня расскажем, на что смотрят аудиторы и с какими результатами мы финишировали.
Для тех, кто с дата-центрами на «вы», кратко пройдемся по матчасти. Tier Standards оценивает и сертифицирует дата-центры на трех этапах:
проект (Dеsign): проверяется пакет проектной документации.Тут как раз присваиваются всем известные Tier. Всего их 4: Tier I–IV. Последний, соответственно, самый высокий.
построенный объект (Facility): проверяется инженерная инфраструктура дата-центра и ее соответствие проекту. Дата-центр проверяют под полной проектной загрузкой с помощью множества тестов примерно такого содержания: один из ИБП (ДГУ, чиллеров, прецизионных кондиционеров, распределительных шкафов, шинопроводов и т.п.) выводится из эксплуатации на обслуживание или ремонт, при этом отключается городское энергоснабжение. ЦОД уровня Tier III и выше должен справиться с ситуацией без каких-либо последствий для полезной ИТ-нагрузки.
Facility можно сдавать, если дата-центр уже прошел сертификацию Dеsign.
NORD-4 получил свой сертификат Design в 2015 году, а Facility — в 2016.
эксплуатация (Operational Sustainability). По сути, самая главная и сложная сертификация. Она в комплексе оценивает процессы и компетенции оператора по обслуживанию и управлению дата-центром с установленным уровнем Tier (чтобы сдать Operational Sustainability, вы уже должны иметь сертификат Facility). Ведь без правильно выстроенных процессов эксплуатации и квалифицированной команды даже дата-центр Tier IV может превратиться в бесполезное здание с очень дорогим оборудованием.
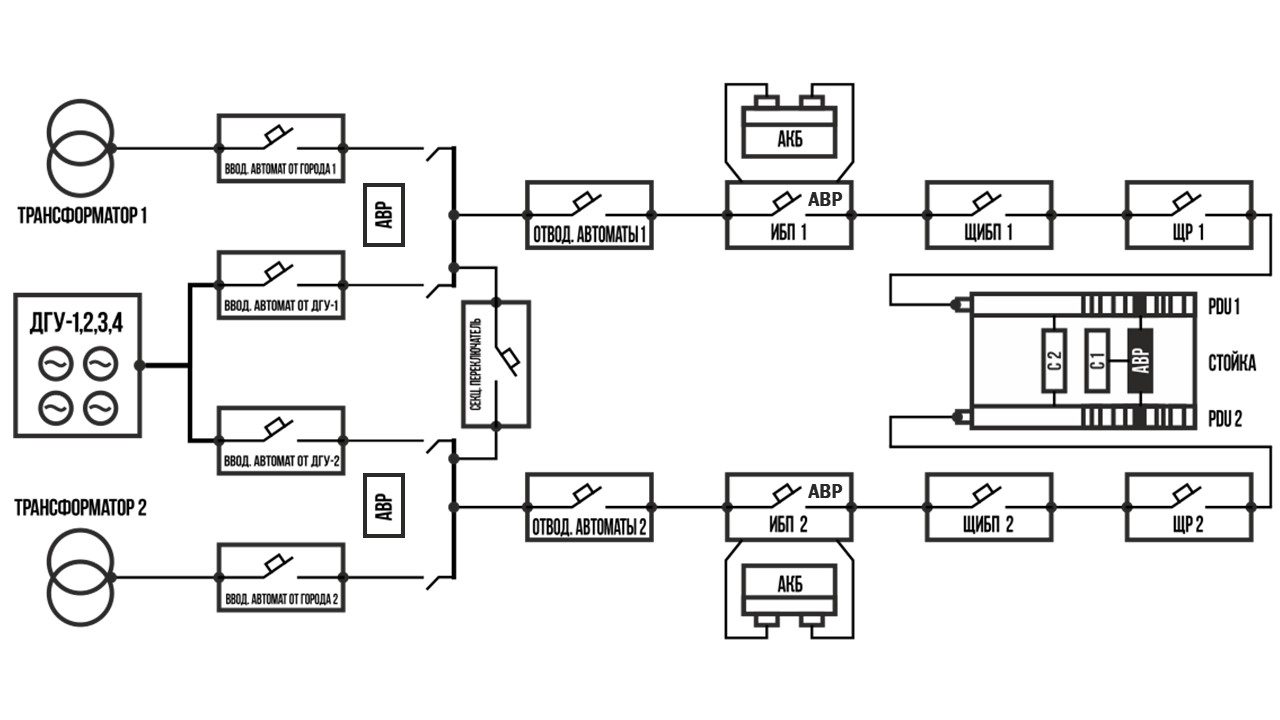
В прошлом посте про PDU мы говорили, что в некоторых стойках установлен АВР — автоматический ввод резерва. Но на самом деле в ЦОДе АВР ставят не только в стойке, но и на всем пути электричества. В разных местах они решают разные задачи:
в главных распределительных щитах (ГРЩ) АВР переключает нагрузку между вводом от города и резервным питанием от дизель-генераторных установок (ДГУ);
в источниках бесперебойного питания (ИБП) АВР переключает нагрузку с основного ввода на байпас (об этом чуть ниже);
в стойках АВР переключает нагрузку с одного ввода на другой в случае возникновения проблем с одним из вводов.
АВР в стандартной схеме энергоснабжения дата-центров DataLine.
О том, какие АВР и где используются, и поговорим сегодня.
Сегодня речь пойдет о работе с VMware vCloud Availability (vCAV). Этот продукт помогает организовать Disaster Recovery (DR) и миграцию в рамках нескольких площадок облачного провайдера или переехать/восстановиться в облако сервис-провайдера с on-premise площадок. vCAV встроен в панель vCloud Director, что позволяет клиентам публичных облаков самостоятельно управлять DR и миграцией своих виртуальных машин из привычного интерфейса.
В этой статье я приводил кейс, как мы мигрировали клиента между нашими площадками в Москве и Питере с помощью vCAV. Сегодня пошагово покажу, как настроить восстановление и миграцию виртуальных машин.
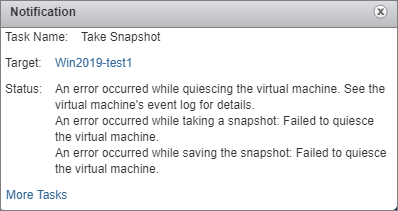
У виртуальных машин Windows Server 2019 с эмуляцией EFI на VMware есть проблема с Application-Aware снапшотами. Выглядит это так: снапшот делается, доходит до 100%, висит минут 5, а потом вываливается в ошибку Failed to quiesce the virtual machine.
Расследование показало, что причина такой ошибки – конфликт службы VSS Windows Server 2019 и VMware Snapshot Provider, который и отвечает за application quiescing. Эта штука готовит виртуальную машину к снапшоту: останавливает работу приложений и операции записи, чтобы после восстановления из снапшота все данные были консистентны.
За последний год возникало много утечек из баз Elasticsearch (вот, вот и вот). Во многих случаях в базе хранились персональные данные. Этих утечек можно было избежать, если бы после разворачивания базы администраторы потрудились проверить несколько несложных настроек. Сегодня о них и поговорим.
Сразу оговоримся, что в своей практике используем Elasticsearch для хранения логов и анализа журналов средств защиты информации, ОС и ПО в нашей IaaS-платформе, соответствующей требования 152-ФЗ, Cloud-152.
После новогодних праздников мы перезапустили катастрофоустойчивое облако на базе двух площадок. Сегодня расскажем, как это устроено, и покажем, что происходит с клиентскими виртуальными машинами при отказе отдельных элементов кластера и падении целой площадки (спойлер – с ними все хорошо).