В первой части рассказа об унификации продуктовой линейки Mail.Ru Group я описал наш первый подход к снаряду —
решение для мобильного веба. Помимо создания единого стиля и принципов работы интерфейса для дюжины сервисов, мы смогли перестроить дизайн-процесс от классического «прототип → макет → верстка → код» для каждого экрана к более эффективному и современному, основанному на фреймворках. Во второй части я расскажу о переводе на эту же технологию более сложных и масштабных больших версий сайтов — как наш «Bootstrap на стероидах» стал еще мощнее.
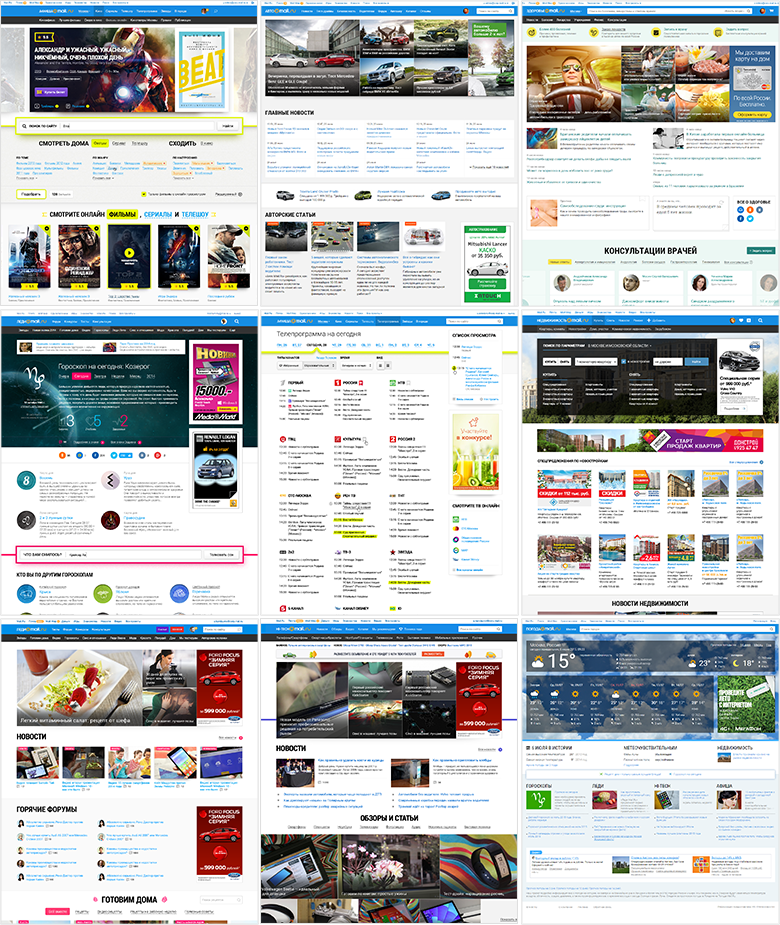
Афиша, Авто, Здоровье, Гороскопы, ТВ, Недвижимость, Леди, Hi-Tech, Погода
Весной 2012 года в наше подразделение Почты и портала передали 11 контент-проектов — Авто, Афиша, Гороскопы, Дети, Здоровье, Леди, Мото, Новости, Погода, Спорт, ТВ. Многие из них — лидеры в своей нише в Рунете. Но история создания и развития у каждого была своя, так что дизайн делался по-своему, зачастую на аутсорсе, без систематизации и выработки общих подходов и решений.
Для нашей команды приведение их внешнего вида и логики работы в порядок стало одной из основных задач. А позднее — и необходимость унифицировать подход к дизайну. Простое и понятное решение — интерфейсно-визуальные гайдлайны для всей линейки продуктов. Они должны сделать работу пользователя понятной и предсказуемой — ему легко перейти с одного сайта на другой и не разбираться в новых паттернах взаимодействия. Это также усиливает бренд. И как приятный бонус — облегчает продуктовой команде развитие и поддержку сервисов.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}