Всем привет, меня зовут Артем Жаринов, я специалист по анализу данных и машинному обучению команды RnD в Lamoda.
Блуждая по нашему сайту вы, возможно, заметили такие полки рекомендаций «С этим товаром покупают» или «Популярные товары». Для персонализированного ранжирования товаров в этих полках мы используем модель из фреймворка Vowpal Wabbit, написанного на языке C. Другой алгоритм отбирает определенный набор товаров, который может показываться на этой полке, а задача Vowpal Wabbit – предсказать вероятность того, что пользователь кликнет на какой-либо товар.
В этой статье расскажу, как мы:

Блуждая по нашему сайту вы, возможно, заметили такие полки рекомендаций «С этим товаром покупают» или «Популярные товары». Для персонализированного ранжирования товаров в этих полках мы используем модель из фреймворка Vowpal Wabbit, написанного на языке C. Другой алгоритм отбирает определенный набор товаров, который может показываться на этой полке, а задача Vowpal Wabbit – предсказать вероятность того, что пользователь кликнет на какой-либо товар.
В этой статье расскажу, как мы:
- составляем рекомендации, которые отображаются на сайте;
- обучаем модели, которые эти рекомендации делают;
- и почему мы пришли к тому, что необходимо автоматизировать весь процесс обучения моделей.











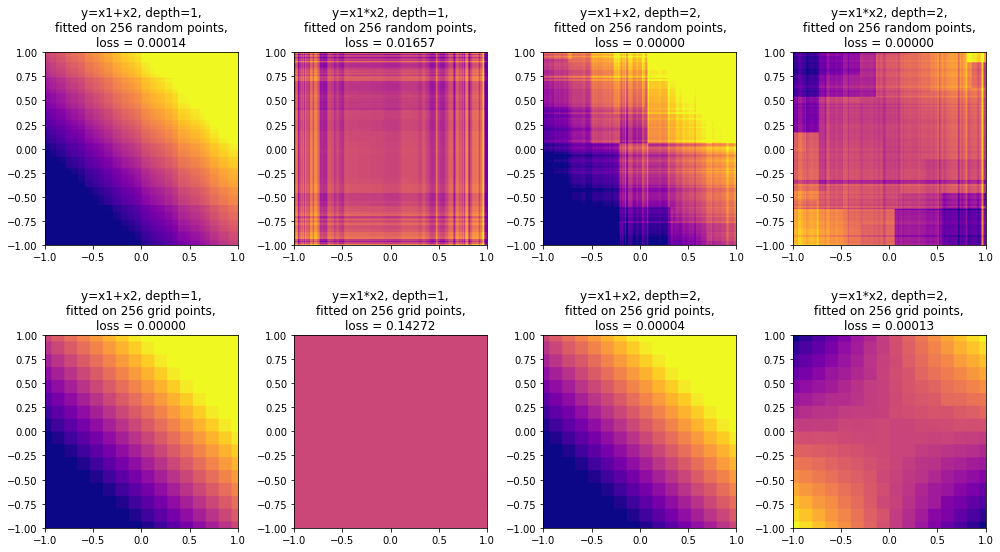
 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.