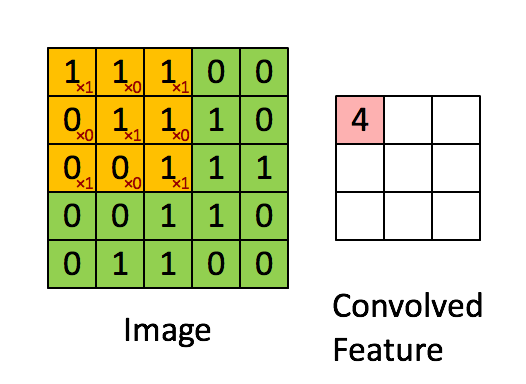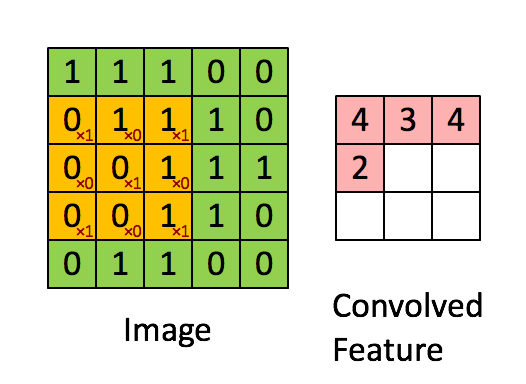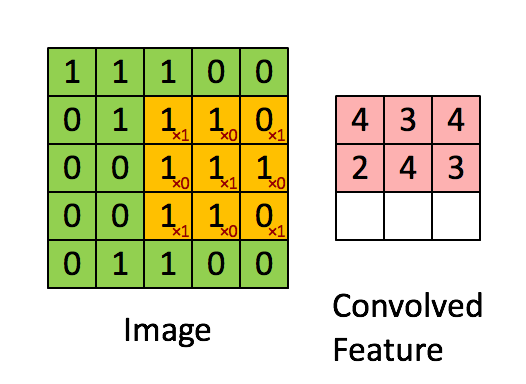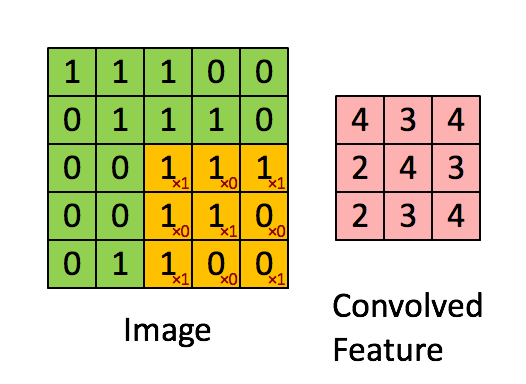
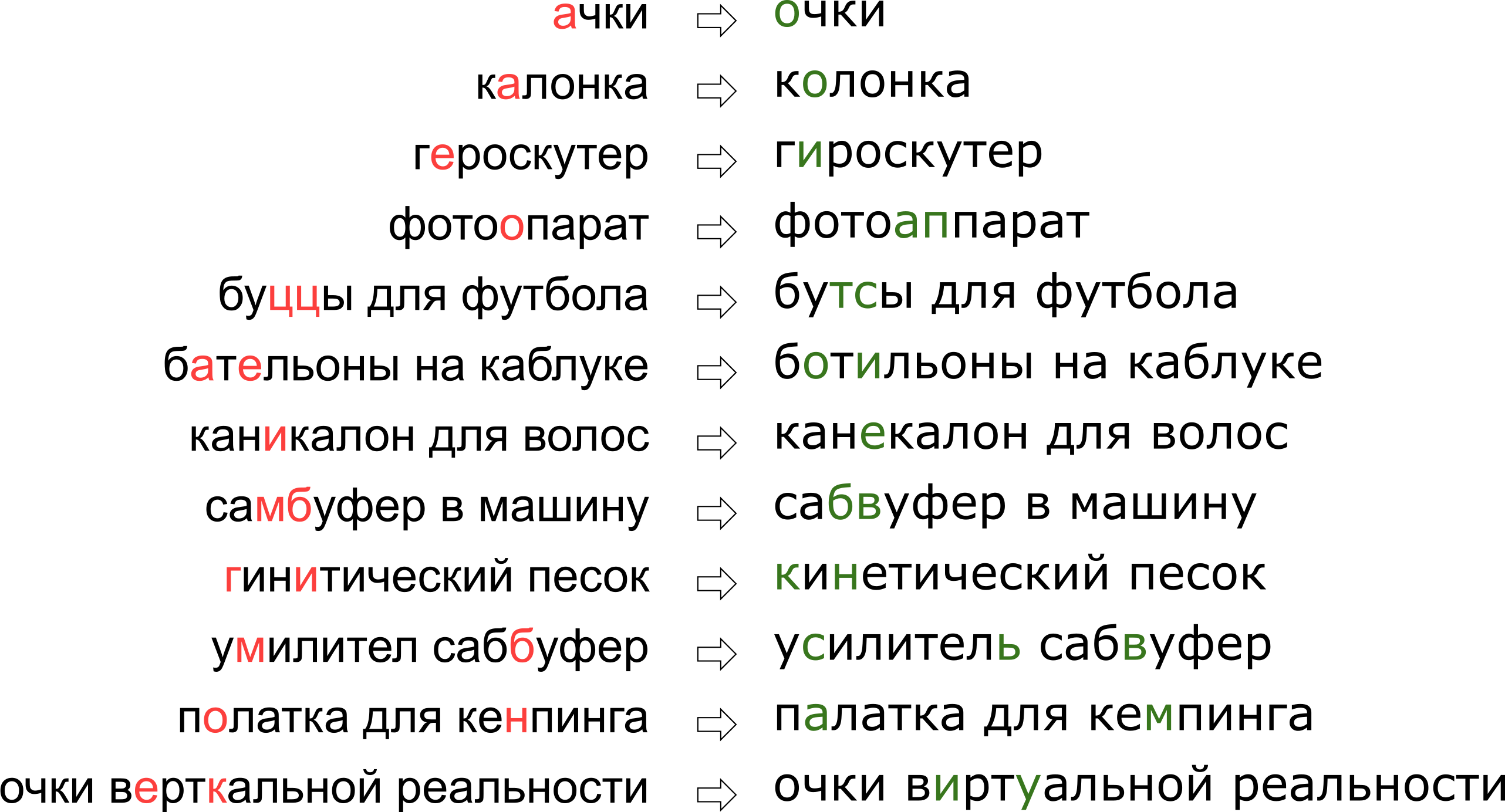
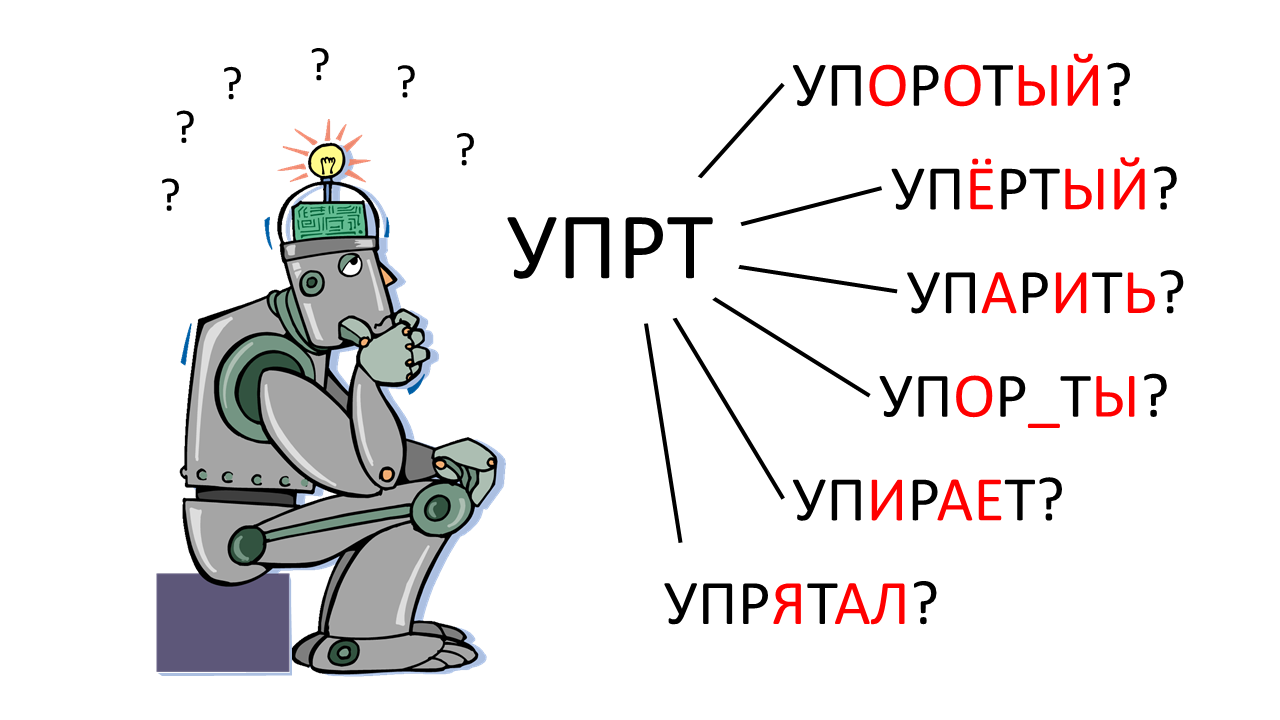
Введение

Я математик-программист. Самый большой скачок в своей карьере я совершил, когда научился говорить:«Я ничего не понимаю!» Сейчас мне не стыдно сказать светилу науки, что мне читает лекцию, что я не понимаю, о чём оно, светило, мне говорит. И это очень сложно. Да, признаться в своём неведении сложно и стыдно. Кому понравится признаваться в том, что он не знает азов чего-то-там. В силу своей профессии я должен присутствовать на большом количестве презентаций и лекций, где, признаюсь, в подавляющем большинстве случаев мне хочется спать, потому что я ничего не понимаю. А не понимаю я потому, что огромная проблема текущей ситуации в науке кроется в математике. Она предполагает, что все слушатели знакомы с абсолютно всеми областями математики (что абсурдно). Признаться в том, что вы не знаете, что такое производная (о том, что это — чуть позже) — стыдно.
Но я научился говорить, что я не знаю, что такое умножение. Да, я не знаю, что такое подалгебра над алгеброй Ли. Да, я не знаю, зачем нужны в жизни квадратные уравнения. К слову, если вы уверены, что вы знаете, то нам есть над чем поговорить! Математика — это серия фокусов. Математики стараются запутать и запугать публику; там, где нет замешательства, нет репутации, нет авторитета. Да, это престижно говорить как можно более абстрактным языком, что есть по себе полная чушь.
 Это будет длиннопост. Я давно хотел написать этот обзор, но
Это будет длиннопост. Я давно хотел написать этот обзор, но